打球部分にxwOBAvalueを用いたPitch Value(xPV)

球種による得失点増減を算出したPitch Valueとよばれる指標がある。このPitch Valueを環境中立的にしたものを作成する。
既存のPitch Value(RV)の欠点
既存のPitch Value(以下PV)やRVと呼ばれる指標はRE288の変動値の平均値や合計値を用いたものを使用している。この方法は、その球種で実際にどれだけ失点を増減させたかを測ることができるというメリットがある。しかし年間の少ない打球数や登板状況に左右されることを考えると、単年で使うには指標の一貫性に欠けやすいという欠点がある。以下はstatcastから入手したMLB 17-20のデータを用い各年度でスライダーを500球以上投球した投手のスライダーのdelta_run_expの平均値(RV/100)の年度間相関をとったものである。(なおPVと単位を合わせるため-の値を反転させている)
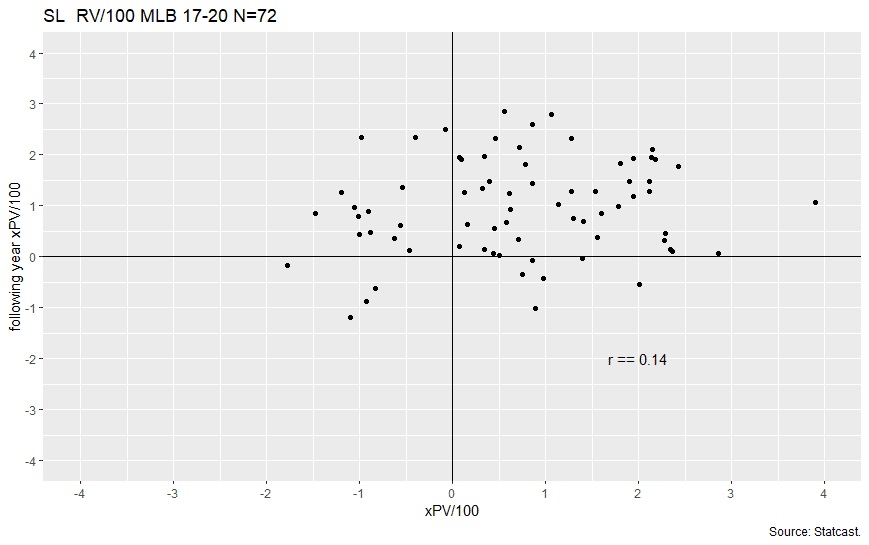
相関係数は0.14とほとんど相関がないという結果になっている。ある年に優れたRV/100を記録しても翌年にどんな値を記録するかはわからないという結果になっている。既存のPVやRVでは球種の安定した価値を測るのは難しいようだ。
状況中立的な得点価値と打球評価にxwOBAvalueを使用
単年の少ない打席数や打球数で球種の価値を測るうえで補正を行う。
まず発生したイベントに対しては、得点価値の変動ではなく状況中立的な得点価値を使用する。例えば走者なしの本塁打と走者ありの本塁打では、既存のRVでは両者の価値が異なるが状況中立的な得点価値とはすべての状況を合わせた本塁打の平均的な得点価値を用いて計算を行う。これはその球種単体が失点を防ぐのを評価するうえで投球した状況に左右されるのは適切ではないと考えたからだ。
もう1つの補正は打球発生時に、実際の打席結果ではなくxwOBAvalue(statcastではestimated_woba_using_speedangle)を用いる。セイバーメトリクスでは打たれた打球が安打になるかアウトになるかは投手自身でコントロールできる要素が少なく、単年程度では数字がブレやすいことが知られている。シーズン全体の打球数でも投手自身でコントロールすることは難しいことを考えると球種の成績は、さらに打球数が少なくなるためより指標の安定性に欠けてしまう。そこで打球については打球の速度と角度から推定される得点価値(xwOBA_value)を用いる。これは守備の影響や偶然の影響を極力取り除くことを目的としている。
このようになるべく状況中立的にPitch Valueの算出を試みる。
xPVの計算方法
このような状況中立的なPVをxPV(expected Pitch Value)とひとまず呼ぶことにする。xPVの計算方法を説明する。
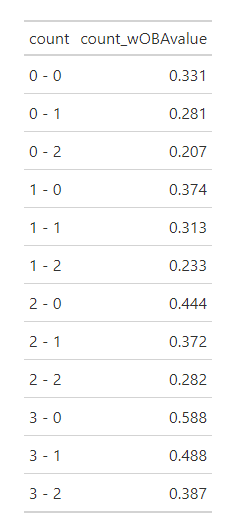
カウント別のwOBAを計算する
まずはカウント別のwOBAを求める。ここでのカウント別のwOBAとは「そのカウントを経過した全ての最終的な打席結果」を基に算出する。そのカウントの時に記録された打席結果ではないことに注意が必要だ。
例えば0-1で打者がストライクを見逃し0-2になりその後三球三振した場合、0-1の打撃成績には三振が1つ記録されるし、0-2からシングルヒットを打った場合には、0-1の打撃成績にはシングルヒットが1つ記録される。(注1)ちなみに0-0は全てのカウントで経過しているカウントのため0-0=その期間の全ての打席のwOBAとなっている。
カウント別得点価値を計算する
このカウント別wOBAを用いカウント別の得点価値を計算する。wOBAを用いれば
(投球後のカウントwOBA - 投球前のカウントwOBA)/wOBAscale(statcastのcsvデータでは≒1.15)
で大雑把なRAA(平均と比較した得点)が計算可能なことを利用する。
まずカウントが変動した場合は(投球後のカウントのwOBA - 投球前のカウントwOBA)/1.15で実際のRAAを計算する。
打球が発生した場合は
(xwOBAvalue - 投球前のカウントwOBA)/wOBAscale
でRAAを算出する。
価値の合計、平均をとる
こうして算出したRAAの合計、平均をとることでxPVを算出する。
このxPVのメリットとしては極力偶然の影響を排除することと、状況中立的に価値を与えることで指標の一貫性が高まることが挙げられる。以下はMLB17-20でスライダー500球以上投球した投手のスライダーのxPV/100(100球当たりのxPV)の年度間相関をとったものだ。

相関係数は0.49と中程度の相関を記録した。球質評価をするうえである程度の一貫性をもたせることができたようだ。
xPVについては以下の記事を参考にした。
(注1)
なぜそのカウント時の打撃成績ではなく、そのカウントを経由した打撃成績を使うのかというと、特定のカウントでのみ起きるイベントの影響をどのカウントでも取り込むことができること、打席結果に直接関係ない投球も評価できるからです。
詳しい解説はsninさんの記事が非常に参考になります。
library(tidyverse)
#dfには2017-2020のMLBデータが入っている
#カウント別wOBAの計算
df <- df %>%
select(balls,strikes,game_pk,at_bat_number,pitch_number,woba_value,woba_denom,description)
df <- df %>%
arrange(game_pk,at_bat_number,pitch_number)
#ifelseでカウントを記録するための列を作る
#打席idを作成
df <- df %>%
mutate(count = paste(balls,"-",strikes),
count_description = paste(count,description),
count00 = ifelse(balls == 0 & strikes == 0 ,1,0),
count01 = ifelse(balls == 0 & strikes == 1 ,1,0),
count02 = ifelse(balls == 0 & strikes == 2 ,1,0),
count10 = ifelse(balls == 1 & strikes == 0 ,1,0),
count11 = ifelse(balls == 1 & strikes == 1 ,1,0),
count12 = ifelse(balls == 1 & strikes == 2 ,1,0),
count20 = ifelse(balls == 2 & strikes == 0 ,1,0),
count21 = ifelse(balls == 2 & strikes == 1 ,1,0),
count22 = ifelse(balls == 2 & strikes == 2 ,1,0),
count30 = ifelse(balls == 3 & strikes == 0 ,1,0),
count31 = ifelse(balls == 3 & strikes == 1 ,1,0),
count32 = ifelse(balls == 3 & strikes == 2 ,1,0),
PA_id = paste(game_pk,"-",at_bat_number),
PA_id_count = paste(PA_id , count))
#group_byで打席idごとの通過カウントを計算
#foul除く
count_stats <- df %>%
filter(count_description != "0 - 2 foul")%>%
filter(count_description != "1 - 2 foul")%>%
filter(count_description != "2 - 2 foul")%>%
filter(count_description != "3 - 2 foul")%>%
group_by(PA_id)%>%
dplyr::summarise(count00 = sum(count00, na.rm = TRUE),
count01 = sum(count01, na.rm = TRUE),
count02 = sum(count02, na.rm = TRUE),
count10 = sum(count10, na.rm = TRUE),
count11 = sum(count11, na.rm = TRUE),
count12 = sum(count12, na.rm = TRUE),
count20 = sum(count20, na.rm = TRUE),
count21 = sum(count21, na.rm = TRUE),
count22 = sum(count22, na.rm = TRUE),
count30 = sum(count30, na.rm = TRUE),
count31 = sum(count31, na.rm = TRUE),
count32 = sum(count32, na.rm = TRUE),
wOBA_value = sum(woba_value, na.rm = TRUE),
wOBA_denom = sum(woba_denom, na.rm = TRUE))
#カウント別wOBA_value,wOBA_denomを計算
count_stats <- count_stats %>%
mutate(count00_value = ifelse(count00 == 1,wOBA_value,NA),
count00_denom = ifelse(count00 == 1,wOBA_denom,NA),
count01_value = ifelse(count01 == 1,wOBA_value,NA),
count01_denom = ifelse(count01 == 1,wOBA_denom,NA),
count02_value = ifelse(count02 == 1,wOBA_value,NA),
count02_denom = ifelse(count02 == 1,wOBA_denom,NA),
count10_value = ifelse(count10 == 1,wOBA_value,NA),
count10_denom = ifelse(count10 == 1,wOBA_denom,NA),
count11_value = ifelse(count11 == 1,wOBA_value,NA),
count11_denom = ifelse(count11 == 1,wOBA_denom,NA),
count12_value = ifelse(count12 == 1,wOBA_value,NA),
count12_denom = ifelse(count12 == 1,wOBA_denom,NA),
count20_value = ifelse(count20 == 1,wOBA_value,NA),
count20_denom = ifelse(count20 == 1,wOBA_denom,NA),
count21_value = ifelse(count21 == 1,wOBA_value,NA),
count21_denom = ifelse(count21 == 1,wOBA_denom,NA),
count22_value = ifelse(count22 == 1,wOBA_value,NA),
count22_denom = ifelse(count22 == 1,wOBA_denom,NA),
count30_value = ifelse(count30 == 1,wOBA_value,NA),
count30_denom = ifelse(count30 == 1,wOBA_denom,NA),
count31_value = ifelse(count31 == 1,wOBA_value,NA),
count31_denom = ifelse(count31 == 1,wOBA_denom,NA),
count32_value = ifelse(count32 == 1,wOBA_value,NA),
count32_denom = ifelse(count32 == 1,wOBA_denom,NA))
count_woba <- count_stats %>%
dplyr::summarise(count00 = sum(count00_value, na.rm = TRUE)/sum(count00_denom, na.rm = TRUE) ,
count01 = sum(count01_value, na.rm = TRUE)/sum(count01_denom, na.rm = TRUE) ,
count02 = sum(count02_value, na.rm = TRUE)/sum(count02_denom, na.rm = TRUE) ,
count10 = sum(count10_value, na.rm = TRUE)/sum(count10_denom, na.rm = TRUE) ,
count11 = sum(count11_value, na.rm = TRUE)/sum(count11_denom, na.rm = TRUE) ,
count12 = sum(count12_value, na.rm = TRUE)/sum(count12_denom, na.rm = TRUE) ,
count20 = sum(count20_value, na.rm = TRUE)/sum(count20_denom, na.rm = TRUE) ,
count21 = sum(count21_value, na.rm = TRUE)/sum(count21_denom, na.rm = TRUE) ,
count22 = sum(count22_value, na.rm = TRUE)/sum(count22_denom, na.rm = TRUE) ,
count30 = sum(count30_value, na.rm = TRUE)/sum(count30_denom, na.rm = TRUE) ,
count31 = sum(count31_value, na.rm = TRUE)/sum(count31_denom, na.rm = TRUE) ,
count32 = sum(count32_value, na.rm = TRUE)/sum(count32_denom, na.rm = TRUE))
#dfには2017-2020のstatcastのデータが入っている
df <- df %>%
select(game_year,game_pk,at_bat_number,pitch_number,pitcher,pitcher_name,player_name,balls,strikes,
pitch_type,pfx_x,pfx_z,release_speed,estimated_woba_using_speedangle,description,type,delta_run_exp)
#試合順、打席準、投球順に並べ替える
df <- df %>%
arrange(game_pk,at_bat_number,pitch_number)
#投球結果つの列を作る
df <- df %>%
mutate(count = paste(balls,"-",strikes),
lead_count = lead(count),
pitch_result = case_when(
description == "swinging_strike" ~ "strike",
description == "swinging_strike_blocked" ~ "strike",
description == "called_strike" ~ "strike",
description == "foul_tip" ~ "strike",
description == "bunt_foul_tip" ~ "strike",
description == "foul" ~ "foul",
description == "foul_bunt" ~ "strike",
description == "ball" ~ "ball",
description == "blocked_ball" ~ "ball",
description == "pitchout" ~ "ball",
description == "hit_by_pitch" ~ "HBP",
type == "X" ~ "X"))
#あらかじめ計算したカウント別wOBAvalueのdfを作成して結合
count <- c("0 - 0","0 - 1","0 - 2","1 - 0","1 - 1","1 - 2","2 - 0","2 - 1","2 - 2","3 - 0","3 - 1","3 - 2")
count_wOBAvalue <- c(0.331,0.281,0.207,0.374,0.313,0.233,0.444,0.372,0.282,0.588,0.488,0.387)
Count_wOBAvalue <- data.frame(count = count ,count_wOBAvalue = count_wOBAvalue)
df <- left_join(df,Count_wOBAvalue)
lead_Count_wOBAvalue <- Count_wOBAvalue %>%
rename(lead_count = count,
lead_count_wOBAvalue = count_wOBAvalue)
df <- left_join(df,lead_Count_wOBAvalue)
#カウント別得点価値を計算
df <- df %>%
mutate(xPV_value = case_when(
strikes == 2 & pitch_result == "strike" ~ (0 - count_wOBAvalue)/1.15 ,
balls == 3 & pitch_result == "ball" ~ (0.7 - count_wOBAvalue)/1.15,
description == "hit_by_pitch" ~ (0.7 -count_wOBAvalue)/1.15,
pitch_result == "strike" ~ (lead_count_wOBAvalue - count_wOBAvalue)/1.15,
pitch_result == "ball" ~ (lead_count_wOBAvalue - count_wOBAvalue)/1.15,
pitch_result == "foul" ~ (lead_count_wOBAvalue - count_wOBAvalue)/1.15,
pitch_result == "X" ~ (estimated_woba_using_speedangle - count_wOBAvalue)/1.15))
#年度間相関用の計算データ
pitch_type_value <- df %>%
group_by(game_year,pitcher_name,pitch_type) %>%
filter(pitch_type == "SL")%>%
dplyr::summarise(N=n(),
value = - sum(xPV_value , na.rm = TRUE),
xPV_100 = - mean(xPV_value,na.rm=TRUE)*100,
RV = - sum(delta_run_exp,na.rm=TRUE),
RV_100 = - mean(delta_run_exp,na.rm=TRUE)*100)%>%
filter(N >= 500)
pitch_type_value_lag <- df %>%
group_by(game_year,pitcher_name,pitch_type) %>%
filter(pitch_type == "SL")%>%
dplyr::summarise(N=n(),
value = - sum(xPV_value , na.rm = TRUE),
xPV_100_lag = - mean(xPV_value,na.rm=TRUE)*100,
RV = - sum(delta_run_exp,na.rm=TRUE),
RV_100_lag = - mean(delta_run_exp,na.rm=TRUE)*100)%>%
mutate(game_year = game_year + 1)%>%
filter(N >= 500)%>%
select(game_year,pitcher_name,pitch_type,xPV_100_lag,RV_100_lag)
PV_xPV <- inner_join(pitch_type_value,pitch_type_value_lag)
cor(PV_xPV$xPV_100,PV_xPV$xPV_100_lag)
cor(PV_xPV$RV_100,PV_xPV$RV_100_lag)
ggplot(PV_xPV,aes(x= xPV_100,y = xPV_100_lag))+
geom_point()+
scale_x_continuous(breaks = seq(-4.0,4.0,1.0) , limits = c(-4.00,4.00)) +
scale_y_continuous(breaks = seq(-4.0,4.0,1.0) , limits = c(-4.00,4.00)) +
geom_hline(yintercept = 0) +
geom_vline(xintercept = 0) +
annotate("text",x=2.00 , y =-2.00,label = "r == 0.49")+
labs(title = "スライダー xPV/100 MLB 17-20 N=72",
x = "xPV/100",
y = "翌年xPV/100",
caption = "Source: Statcast.")この記事が気に入ったらサポートをしてみませんか?