
NBAでシュートファールをもらうのが上手い選手を見つける
概要
NBAでシュートファールをもらうのが上手い選手を見つけるための手法を検討した
予測されるFTAと比較して実際のFTAが多い選手を、上述の選手と捉えるというアプローチを採用した
結果として、一般的にシュートファールをもらうのが上手いと言われている選手(Joel EmbiidやDeMar DeRozan)以外にも、Lonnie Walker ⅣやBojan Bogdanovicも上手である可能性が示唆された
本文
背景・分析アプローチ
こちらは以前の投稿の改善版となります。
全試合の映像を観るのは途方もなく時間がかかるので、スタッツからシュートファウルもらうのが上手い可能性が高そうな選手をある程度ピックアップしようというコンセプトです。
以前の投稿では、被ファウル数(PFD)に対してFTAが多い選手を、シュートファールもらうのが上手い選手としていましたが、今回はそれを発展させて、予測されるFTAに対して実際のFTAが多い選手を見つけることにします。
基本的な分析アプローチは同じですが、その中で利用する数字を高度にした形になります。
詳細な分析アプローチは下記になるので、ご興味あればご覧ください。
今回は予測されるFTAと比較して実際のFTAが多い選手を、シュートファールをもらうのが上手な選手と捉えるというアプローチを採用します。
FTAを予測する際の特徴量には、FTAと相関が強いと考えられる出場時間、FGA、Personal foul drawn(以下PFD)を利用します。
予測モデルや特徴量の前処理はそれぞれ2パターン作成し、それらを組み合わせて最も予測精度の高かったモデル及び前処理を採用します(Cross Validationでの汎化性能も確認しています)。
ここまでで作成したモデルや処理を踏まえてデータセット全体で予測を行い、予測されるFTAに対して、実際のFTAがどの程度の比率でずれているかを算出し、その比率が高い選手を、シュートファールをもらうのが上手な選手と捉えます。
今回の分析で利用するデータはNBAの2021–22レギュラーシーズンです。公式サイトから手動でコピペしているので、raw dataに興味がある方は下記のスプレッドシートを御覧ください。
https://docs.google.com/spreadsheets/d/1gdlAOctQXfM1M99gQIvjsTxzSQ_JJX-x62ai0CvoDEE/edit?usp=sharing
※サンプルのデータフレームは下記画像になります。もともと英語版で作っていたので、画像の文字などが英語になっています。予めご容赦ください。

結果
まずは今回利用するデータの関係性などを見てみます
※今回の分析ではRを利用してます。分析コードの詳細を見たい方はこちらのGithubをご参照ください。
pairs.panels(df %>% select(-Player))
これらを見ると、どの変数も一定程度の相関係数があり、特にPFDとFTAの相関係数が極めて高いことが分かります。
MinとFGAについては、FTAとの関係性が二次曲線的になっているように見え、これは興味深い傾向です。
それでは予測モデルを作成しましょう。
コードは下記になります。
seed = 1031
set.seed(seed)
folds <- df %>%
vfold_cv(v = 5, strata = FTA)
folds
# define recipe
fta_recipe_base <- df %>%
recipe(formula = FTA ~ .) %>%
update_role(Player, new_role = "id variable") %>%
step_zv(all_predictors()) %>%
step_center(all_predictors())
fta_recipe_yj <- fta_recipe_base %>%
step_YeoJohnson(Min, FGA)
# define model
lm_spec <-
linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
xgb_spec <-
boost_tree() %>%
set_engine("xgboost") %>%
set_mode("regression")
# This time, I skip hyper parameter tuning.
# learning
fta_models <-
workflow_set(
preproc = list(
base = fta_recipe_base
,yj = fta_recipe_yj
)
,models = list(
lm = lm_spec
,xgb = xgb_spec
)
,cross = TRUE
)
set.seed(seed)
fta_models <- fta_models %>%
workflow_map(
resamples = folds
,metrics = metric_set(mae)
,verbose = FALSE
)
fta_models
fta_models %>%
rank_results(
rank_metric = "mae"
,select_best = TRUE
) %>%
select(rank, mean, model, wflow_id, .config)
# base recipe and lm is the best modelモデルの作成が終わったので、これを利用してFTAの予測値を選手ごとに算出して、実際の値に対する予測値の割合が高い選手と低い選手、ついでにFTAが多い選手も抽出してみましょう。
(実際のFTAが100本以上の選手に限定しています。)

最初の5選手が比率が高い選手、次の5選手が比率が低い選手、残りの10選手がFTAが多い選手となります。
FTAが多い選手の中でも、James HardenやJimmy Butler、Joel EmbiidやDemar DeRozanのように比率が高い選手でファールをもらうのが上手いと言われている選手がいる一方で、Nikola JokicやKATは比率が低い傾向にあります。
※ちなみに、Lebron Jamesはこの表には乗っていませんが、real_pred_ratioは89.8%と、想定されるFTAより少なめの結果となっています。彼にはあまりファールが吹かれない傾向にあるのかもしれません。
今回のテーマである、実はシュートファールもらうのが上手いと考えられる選手としては最初の5選手になります。 実際にもらうのが上手いかは映像分析などが必要になるでしょうが、候補を探すという観点では悪くない分析結果ではないでしょうか。
予測値と実際の値の散布図についても見てみましょう
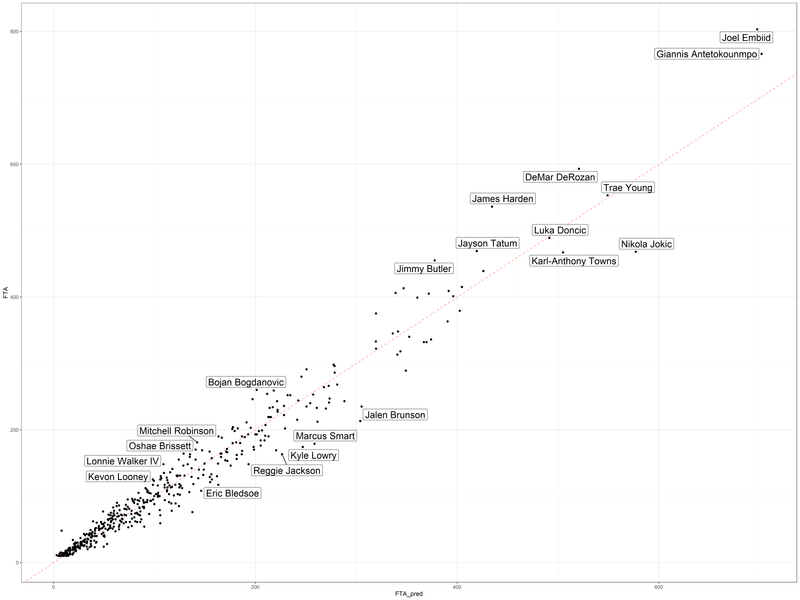
比率が高い選手、低い選手は、一般的にシュートファールをもらうのが上手いと言われる選手と比べてFTAが少ない傾向にあるので目立ちづらいというのがこのグラフから分かるかと思います。
結論
NBAでシュートファウルをもらうのが上手な選手をデータから見つけるという分析を行った
結果として、これまでは議論に上がらなかったと思われる選手を見つけることができた
一方で、実際の値に対して予測値が大きい選手を、シュートファールをもらうのが上手い選手と言い切れるかに関しては議論が必要と考えられる
例えば、Q終わりでチームファールが溜まってる時の出場が多く、通常のファールがFTAに繋がってしまっている可能性
他にも、特徴量としてトラッキングデータやポジションを入れることでより改善が見込まれるかもしれない
最後に、ここまでお読みいただきありがとうございました!
この選手もファールもらうのが上手いと思う!この選手はちょっと違うかも。。。などなどあれなコメントお待ちしております!
もしよければTwitterのフォローもよろしくお願いいたします。
サポートしていただけるとありがたいですが、 SNS等で広めていただけるともっとありがたいです。 一緒にバスケを盛り上げていきましょう!