
寝ている間に対話形式の解説動画を生成してくれるツールの作り方

こんにちは!あずさです。
生成AIとプログラミングを活用して、皆さまの副業を応援する自動化ツールや画像生成・ツイート生成などに使えるプロンプトを作っています。
今回はウワサのNoLangに対抗して、、、じゃないですが、対話形式のVOICEVOX解説動画を生成できるツールを作ってみました。
実際の挙動
まず所定のフォーマットで台本を作ります。見慣れない形式かと思いますが、ベタ打ちテキストから所定の形式に変換するエクセルと、ChatGPTが台本を生成してくれるプロンプトが付属するので簡単に作れます。(これらの台本もChatGPTです。)

後はコマンドを1行実行するだけです。(2行目以降は実行ログです)
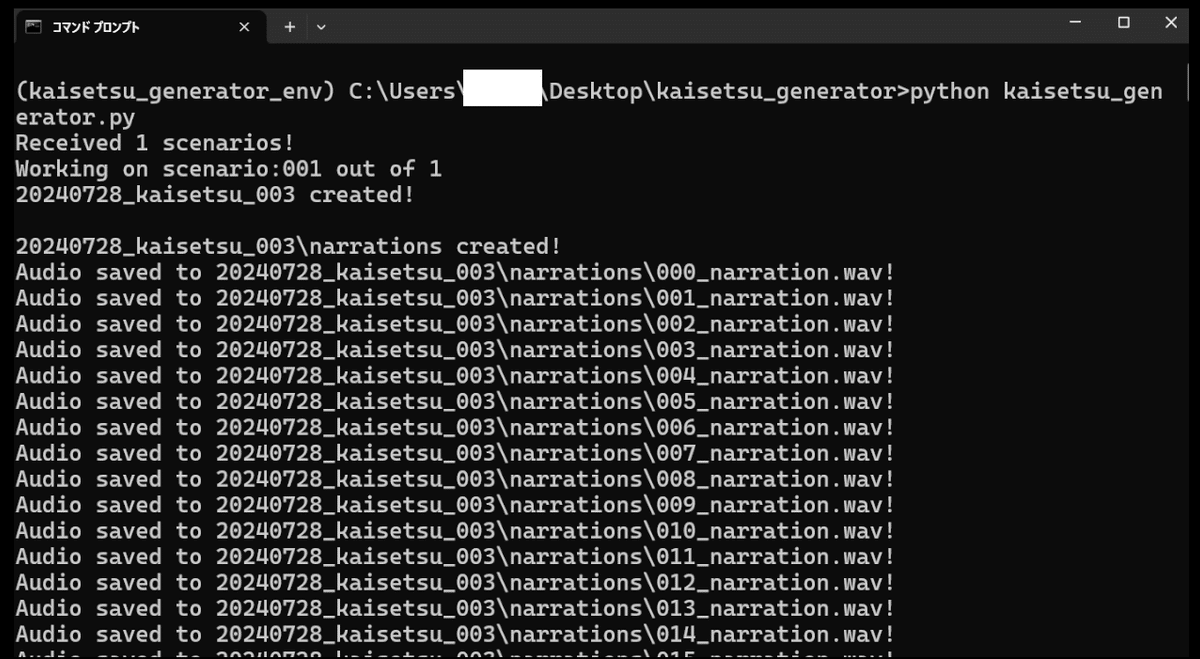
こちらが実際に生成した動画です。ナレーション、テロップ、立ち絵、フリー画像付きの全部入りです。音声はVOICEVOXから選ぶことができ、キャラクターの立ち絵、BGM、背景は任意のものをセットできます。
1つ目の動画は簡易な記事を書いて、それをChatGPTに与えて対話形式の台本に書き換えさせました。
2つ目の動画はタイトルだけChatGPTに与えて台本生成させたので、内容もChatGPTです。AIは長めの創作にまだまだ弱いイメージですが、そこそこ見れる感じになってませんか?手直しなしでこれなので、うまく使えば動画作成がかなり楽になるかと思います。
複数の台本を一括で読み込ませられるので、寝ている間に解説動画を量産してくれます。(台本は1つのファイルに複数記述できるので、ファイルを大量に作ったりする必要もありません。)
フリー画像なしやアバター画像なしで出力したり、グリーンバックで出力することも可能です。
AIツールに精通している優秀な皆さんならわかると思いますが、AIを使ってクオリティの高い成果物を作るには、AIにすべてを投げるのではなく、AI任せる部分と手作業でクオリティを上げる部分をしっかり決めることが大切ですよね。そんなニーズにもお応えできます。
アップデート
アップデート情報です。アップデートの適用は「構築手順>アップデートの適用」から手順をご確認ください。
20240807:画像は自動取得orなしだったのを、任意のローカルの画像をセットできるようにしました。これで任意の画像を使いたいときは画像なしで出力→手作業で編集、だったのが、最初から台本で使う画像を指定できます。
いらすとやの画像を使って動画を作ってみました。
アニメの反応集なんかも作れちゃいますね。(アニメのスクショと反応はChatGPTに適当に架空のものを作ってもらったので微妙です笑)。ChatGPTのプロンプトを作りこめばまとめサイトをコピペして投げるだけで台本をたたき台は作れそうです。
増えていく“回数制限”付きのAIサブスク

近年世の中のサービスがどんどんサブスク化していくだけでなく、特にAIを使ったサービスでは、月額を払っても使い放題にならず、ポイントのようなものが付与されてそれを消費してサービスを使う形式のサブスクが増えています。
AIサービスを普段から活用されている皆さんならわかると思いますが、AIは何度も試行錯誤をしないと意図した結果を出すのは難しいので、回数制限はかなりネックです。数十回程度の生成しかできない場合、何の成果も得られないままポイントを使い切ってしまうことなんかざらです。
AIサブスクの中身はほとんどChatGPT

ユーザーが入力したテキストからパワポ資料を作ってくれるAIサブスクや、テロップや画像などの素材を使って動画を生成してくれるAIサブスク(Luma AIやSoraのような素材を使わずゼロから動画生成するものではなく)は、実はどちらも中身はChatGPTのようなテキストを生成するタイプのAIであることが多いです。
どういうことかと言うと、それらのサービスは以下のような手順で動いています。
ユーザーがテキストを入力する
ChatGPTのようなAIが、ユーザーが入力したテキストを解釈して、プログラムで処理できる形のデータに変換する
データをプログラムで処理して成果物を生成する
実はAIが使われているのは2のデータ変換の部分のみで、実際の成果物の生成はプログラムによって行われています。
つまり3のプログラムを自作できてしまえば、ChatGPTのサブスクだけで多くのAIサブスクを代替できるんです。そして勘のいいひと、私の自動化ツールを既にお使いの方ならもうお気づきかと思いますが、私の自動化ツールはまさに3のプログラムです。ChatGPTで生成した台本データを読み込んで、動画を生成します。
AIサブスクは”本当の自動化”じゃない

そして多くのAIサブスクは”本当の自動化”とは言えません。というのも多くのAIサブスクは、結局はGUIアプリ(一般的なボタンをクリックして操作するアプリ)なので、
「テキストをセットして、、、仕様を選んで、、、生成ボタンを押して、、、生成されるのを待って、、、生成されたら書き出しボタンを押して、、、書き出されたら新しいプロジェクトを作って、、、」
という操作が必要な、パソコンの前にずっと座っていないといけない単純作業です。
私のツールはCLI(コマンドラインインターフェース)アプリと言って、コマンドプロンプトという黒い画面にコマンドを入力することで実行します。
GUIアプリのようなわかりやすい操作画面がない代わりに、書き出しまでの一連の操作が自動化されているので、台本を用意すればコマンド1つで寝ている間に大量の動画を生成することができます。ずっとパソコンの前に座ってなくていい、本当の自動化です。
「プログラミングよくわからない」「黒い画面怖い」という気持ちはわかりますが、この記事を見てくださっている皆様は動画編集やAI画像生成にチャレンジしたことがある方々だと思います。
そのような経験のある皆様ならCLIアプリを使いこなせると思いますし、Stable Diffusionをインストールできたレベルの人には丁寧すぎてクドいかもしれないくらい詳細な手順を解説しています。
一緒に本当の自動化を始めませんか?
必要な環境
まず私のマシン環境は以下の通りです。ご自身のPCスペックと比べてご判断ください。生成する動画が長くなるとメモリを食うので、メモリは16gb以上あった方がいいと思います。
■メインPC(2020年製)
OS:Windows11 Home
CPU:AMD Ryzen 5 4600H
GPU:GTX 1650 mobile
メモリ:16gb
■サブPC(2018年製)
OS:Windows11 Home
CPU:Intel Core i7-8650U
メモリ:16gb
また、以下の3つのツールがインストールされた状態である必要があります。
Python:私の場合は3.10.6
FFMPEG:私の場合は6.1-essentials_build-www.gyan.dev
VOICEVOX:私の場合は0.19.2
多少バージョンが前後しても動くと思いますが、不安な方や異なるバージョンで動かなかった場合は同じバージョンをインストールしてみてください。
20240817追記:Python3.12.5だとプログラムの書き換え(トラブルシューティングを参考にしてください)が必要でした。できれば3.10.6をインストールしてください。
Pythonは以下の手順が参考になります。
https://www.python.jp/install/windows/install.html
FFMPEGはこちらが参考になります。
https://jp.videoproc.com/edit-convert/how-to-download-and-install-ffmpeg.htm
私は試したことがないのですが、FFMPEGはこちらのようなより簡単なインストール方法もあるようです。
https://roboin.io/article/2024/02/25/install-ffmpeg-to-windows/
インストールが完了したら、コマンドプロンプト(windowsの検索窓で「cmd」と検索)でそれぞれ「Python」「ffmpeg」と入力してみて、バージョン情報が表示されれば完了です。(「Python」と入力するとPythonの対話モードが起動するので、バージョンが確認できたらコマンドプロンプトを閉じるか、「exit()」と入力して対話モードを抜けてください。)
VOICEVOXは以下が参考になります。ちょっと重めなソフトなので、スムーズに動作するか事前にご確認ください。
https://sosakubiyori.com/voicevox-introduction/
ここまでできていれば、ツール構築の50%は完了したと言ってもいいでしょう。
その他必要な準備
フリー画像の取得にpexelsというフリー画像サービスのAPIを使用するので、APIキーと言うものが必要になります。
APIというのは(一面的な説明ですが)アプリを作るときに、別のアプリの機能を使うために連携するための手法で、例えば美容室アプリに地図機能を付けたいときは、GoogleマップのAPIを使うことで、地図機能を作るのではなく、Googleマップの地図機能を流用することができるようになります。
今回は背景動画を生成するためにpexelsのAPIを使って画像を取得するという形でAPIを使用しています。
APIキーは以下の手順で取得できます。
まず、pexelsにアクセスし、右上の「参加」からアカウントを作成します。(Googleアカウントでログインもできます。)
次にアカウントにログインした状態で、以下のURLにアクセスします。
https://www.pexels.com/ja-jp/api/
そうすると以下のような画面になるはずなので、「APIキー」というボタンを押してください。

すると以下のような画面になります。「WebサイトのURL、アプリなど(該当する場合)」以外の部分をすべて入力して、「APIキーを生成」を押してください。
「Canvaの写真や~」のAPIの利用用途説明の部分は50文字以上の入力が必要です。
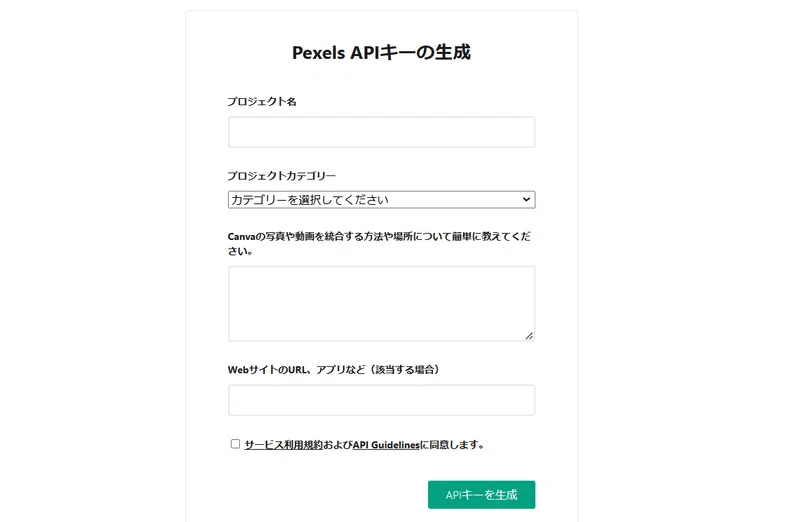
私は以下のような感じにしました。
私個人が使用する、テキストから動画を作成するためのプログラムの中で、動画の背景に使う画像を、検索ワード用いて検索し、取得するためにAPIを使います。
そうすると、以下の黒帯部分に長い文字列が表示されます。それがAPIキーなので、メモしておいてください。(一度生成したAPIキーはPexelsからいつでも確認できます。)

諸注意
・この記事はあくまで作り方を指南する記事です。サンプルとしてそのまま実行できるスクリプトファイルを添付し、できるだけ再現性が高くなるよう丁寧に書いたら2.5万字、画像70枚を超えた実行手順と解説を記載していますが、動作の保証や返金保証、サポート等はできません。(ですが、Python導入からAPIキーの取得までの準備が完了していて、おそらく動画編集やAI画像生成の経験もお持ちの自己解決能力の高い皆さまなら、詰まることなくツールを構築できると思っています。また、コメント欄でのお問い合わせにはできる限りお答えします。)
・ナレーションにVOICEVOX、背景画像の取得にPexelsを使用しています。ご利用の際はそれぞれの規約を遵守するようにお願いします。
VOICEVOX:https://voicevox.hiroshiba.jp/term/
Pexels:https://www.pexels.com/ja-JP/license/
PexelsAPI:https://www.pexels.com/ja-jp/api/documentation/#guidelines
以下私の解釈ですがVOICEVOXはクレジット表記必須、Pexelsは画像利用に関しては基本不要ですが、例えばAPIを使って背景をリアルタイムで変更しているWebサイトなどではクレジット表記が必要みたいです。当ツールでの使い方はそれに該当しないと思いますが、念のためVOICEVOXと同じようにクレジット表記するのが安パイかなと思います。
・台本生成のプロンプトはGPT4o、GPT4向けです。(出力された台本のファクトチェックは各自で行ってください。)また、対話を通して台本を生成するプロンプトになっているので、1つの台本を生成するのに20回前後のやり取りが発生します。無料枠だけだと厳しいかもしれません。
また、プロンプトはずんだもん×四国めたん用です。(彼女らの口調で出力されます。)
・台本作成用エクセルはMicrosoft 365または無料で使えるWeb版Officeの最新バージョンのエクセル向けです。TEXTSPLIT関数を使っているのでGoogleスプレッドシートや異なるバージョンのエクセルでは動作しないのでご注意ください。(スプレッドシートではTEXTSPLIT関数をSPLIT関数に置き換えればいいので、慣れている人なら少しいじれば同じシートをすぐ作れると思います)
エクセルで行っているテキストの台本形式への変換はChatGPTでも可能なので、エクセルがなくても問題はありません。エクセルなしでの台本の作り方は「エクセルを使わずに台本を途中修正する」をご参照ください。
・その他の仕様
■BGM
お好きなBGMをセットできます。(MP3推奨)ご自身でご用意ください。
■背景画像
お好きな画像をセットできます。(動画のアスペクト比と同じPNG画像推奨)サンプルが付属しています。
■背景動画
お好きな動画をセットできます。(動画のアスペクト比と同じMP4動画推奨)ご自身でご用意ください。
■アバター画像(立ち絵)
背景透過のPNG画像をセットできます。(立ち絵はパーツ分けされたPSDファイルが多いですが、本ツールで読み込むアバター画像は背景透過の1枚のPNG画像である必要があります。GIMPなどの無料の画像編集ソフトで、PSDファイルの任意のレイヤーを1枚のPNGとして書き出すことが可能です。事前に使いたい立ち絵の背景透過PNG画像を用意できそうかご確認ください。)
ご自身でご用意ください。
■生成時間
私のメインPC環境で、セリフ数56、取得フリー画像枚数26枚、背景動画あり で最終的な動画の尺が約5分の場合で、約13分でした。
解像度は1280×720(YouTubeの720p相当)、FPSは30です。
グリーンバック出力で画像取得も背景動画もない場合は3分程度まで早くなります。
■制限
なし(画像ありで出力する場合、PexelsAPIの利用制限に依存します。公式には1時間で200リクエスト以内なので、つまり画像200枚まで。26枚の画像を取得する動画の生成に13分かかるので1時間で必要な枚数は約120枚となり、私の環境では1時間制限には引っ掛かりませんが、環境・台本によって異なることをご留意ください。また月の取得上限は20000枚までです。この辺りはPexelsAPIの規約に依存するので適宜ご確認ください。画像なしで出力する場合は制限なしです!)
また、基本16:9のアスペクト比の解像度を想定しています。(縦動画を想定していません)
■出力形式
MP4
■利用規約
ソースコードやその他添付物の転載等、作者が不利益を被る利用はお控えください。また、このツールに関連して生じたトラブル等の責任も負いません。動画はバンバン作って好きに使ってください!
・配布ファイルのダウンロードについて
note上のファイルは危険なファイルと誤判定されてしまいダウンロードができないことがあるようです。
危険なファイルと誤判定された場合でも、以下の方法でダウンロードが可能です。(同じくnoteで添付ファイルが危険と判定されてしまった人がダウンロード方法を解説してくれています。)
当然危険なものは入れてませんし、note側でもファイルのウイルス判定は行われているのでご安心ください。
一応ファイルの中身も以下に開示します。念のためお知らせでした。ご了承くださいませ。
data.txt: 台本格納用のファイルです。
kaisetsu_generator.py: メインのスクリプトです。
kaisetsu_generator_README.html: ツールのドキュメントです。
requirements.txt: ツールに必要なライブラリをインストールするためのファイルです。
_variables.py: 設定ファイルです。
解説動画台本作成シート.xlsx: 台本作成用のエクセルシートです。
avatars: 立ち絵を格納するためのフォルダです。
backgrounds: 背景画像・映像を格納するためのフォルダです。
bgms: BGMを格納するためのフォルダです。
fonts: フォントを格納するためのフォルダです。テロップ用のフリーフォントが入っています。
my_modules: モジュールを格納するためのフォルダです。
Python導入からAPIキーの取得まで準備が完了し(完了している前提で話が進みます)、上記ご理解いただいた上で「挑戦したい!」と思ってくださる方は、ぜひ先へお進みください。一緒に頑張りましょう!
構築手順と基本的な実行手順を案内するので、実際に動かしてみるところから始めましょう。
ここから先は
¥ 990
この記事が気に入ったらサポートをしてみませんか?