
アセンブラとスタック

こちらで、スタックについて書いてみました。
アセンブラにとってスタックは欠かせません。
何故でしょうか。
アセンブラを書いてみましょう。
ARM でメモリコピーの関数を書いてみます。
こんな感じ。
.globl mem_cpy
.p2align 2
.type mem_cpy,@function
mem_cpy:
# x0 : コピー先アドレス
# x1 : コピー元アドレス
# w2 : コピーサイズ
mov w9, 0
loop:
ldrb w8, [x1] @ コピー元アドレスのデータをw8に取り出す。
strb w8, [x0] @ w8をコピー先のアドレスに設定する。
add x1, x1, #0x1 @ コピー元アドレスをインクリメントする。
add x0, x0, #0x1 @ コピー先アドレスをインクリメントする。
add w9, w9, #0x1 @ コピーしたサイズをカウントする。
cmp w9, w2 @ コピーしたサイズとコピーサイズを比較する。
b.lt loop @ コピーしたサイズがコピーサイズに達するまで繰り返す。
retコメントに詳しく書いたのであまり説明はいらないと思います。
が。
やはり少し説明しましょう。
ldrb w8, [x1] @ コピー元アドレスのデータをw8に取り出す。
strb w8, [x0] @ w8をコピー先のアドレスに設定する。ここでは、アドレス「x1」のデータを「w8」に取ってきて、それをアドレス「x0」に設定します。
アドレス「x1」のデータを
アドレス「x0」に
コピーしているわけですね。
add x1, x1, #0x1 @ コピー元アドレスをインクリメントする。
add x0, x0, #0x1 @ コピー先アドレスをインクリメントする。
add w9, w9, #0x1 @ コピーしたサイズをカウントする。これはコメント通りですね。
コピー元のアドレス
コピー先のアドレス
コピーしたサイズ
これに1を加算しています。
cmp w9, w2 @ コピーしたサイズとコピーサイズを比較する。
b.lt loop @ コピーしたサイズがコピーサイズに達するまで繰り返す。この2行で、指定されたサイズ分をコピーしたかどうかを確認しています。
「cmp」命令は比較するだけで、ジャンプはしません。
ステータスレジスタのフラグが更新されるだけです。
次の「b.lt」命令でジャンプします。
「lt」は「より小さければ」という条件。
この条件が成立した時にラベル「loop」の位置へジャンプします。
アセンブラのループは独特ですね。
でも、この「cmp」と「b」命令だけで、様々なループや条件を表現できます。
「switch」も「for」も「while」も「break」も「continue」もありません。
比較してジャンプする。
これだけで実現できるものなんです。
これはこれで面白かったりします。
さて。
上記のアセンブラは、求めているコピー機能は確かに動くのですが、少々問題があります。
レジスタ x0,x1,w8,w9 を書き換えてしまっているのです。
アセンブラにおいてレジスタは非常に重要です。
ARM は詳しくありませんが、レジスタでないと演算できないというアセンブラもあります。
add するにも、 sub するにも、 cmp するにも、レジスタでないとできません。
メモリの値を加算しようとすると、一度レジスタに持ってきて加算し、レジスタを再びメモリに格納する、そういう手順を踏まなければなりません。このため、どの関数もレジスタをアクセスしていると考えるべきです。
サブルーチン「mem_cpy」ですが、もしかすると呼び出し側でレジスタ x0,x1,w8,w9 を使っていたかもしれません。そして、「mem_cpy」が、まさかこれらのレジスタを書き換えてしまうだなどとは思いもしなかったのかもしれません。それはとりもなおさず不具合につながることを意味します。では、どうすればいいでしょうか。
レジスタを一切使わないというのは不可能です。とすると、使用するレジスタの値を一旦どこかに待避しておいて、関数が終了する直前に戻しておくということをする以外にはないでしょう。
いったい、どこに待避すればいいでしょう。
グローバルな領域に待避するということも考えられないではありません。ですがグローバルな領域というのは1つしかありません。1つしか待避できないとなると、マルチスレッドなどのように複数から同時に実行されたような場合には破綻します。
そうすると、待避する領域は動的に確保する必要があるのですが、複数を記憶する場合は、だれが、どこに待避したのかも管理しなければならず、いよいよ複雑になります。
そこで、スタックです。
関数の始めでスタックにpushして、
関数の終りでスタックからpopする。
それだけで済むのです。
この、「レジスタの待避」と「スタック」は、実に素晴らしい関係にあります。だからこそ、今でもなお使われているのでしょう。
例えば、
関数A→関数B、関数Cを呼び出した後、さらに
関数A→関数Cを呼び出す
とします。
関数A、B、Cはそれぞれ
4バイト、8バイト、4バイトのデータをpushします。
ここに空のスタックがあります。

まず、関数Aがpushします。
関数Aがpushしたデータがスタックに積まれます。

次に関数Bが呼び出されてデータをpushします。

そして最後に関数Cがpushします。

関数Cが処理を終えると、pushしたデータをpopしてリターンします。

同じように関数Bもpopしてリターンします。

ここで関数Aに戻ってきたわけですが、関数Aはこの後、更に関数Cを呼び出します。
関数Cは再びpushします。
pushする値は、前回と同じとは限りません。
pushする場所も違います。
それでも、今回も前回と同じようにpushします。
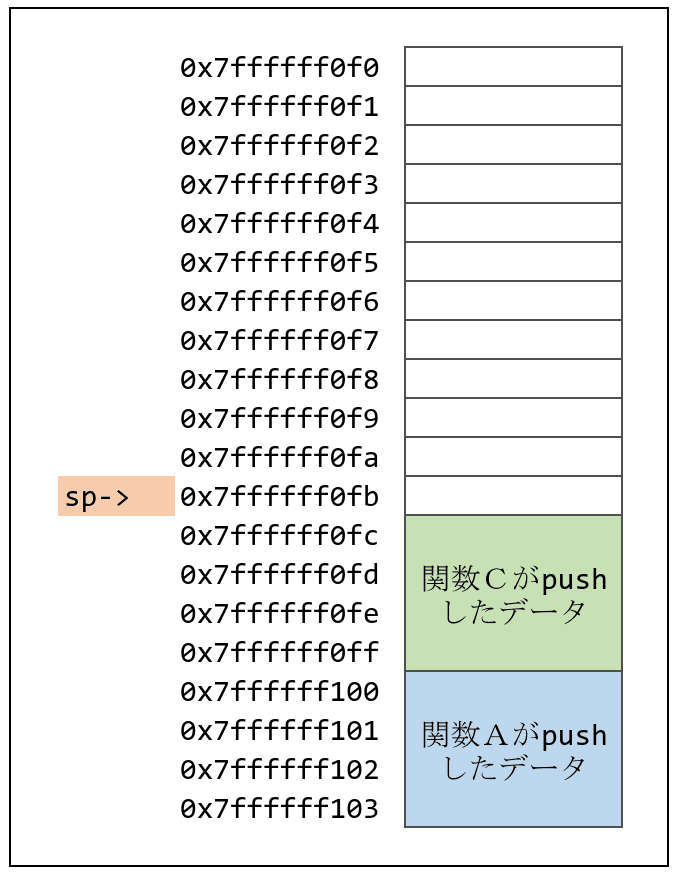
処理が終わればpopしてリターンします。

すると再び関数Aにきちんと戻れるのです。
どこに、いつ、誰が、などは気にする必要はありません。
好きなだけpushして、確実にpopすればいいだけです。
関数が順に呼び出される仕組みと
スタックが順に積まれる仕組み
これが見事にマッチしています。
マッチしていればこそ、今に至っても同じ仕組みが使われて続けるのでしょう。
考え出した人はすごい。
最後に、レジスタをスタックに待避したコードです。
push、popしたかったけど、スマホのARMにはなかった。
「stp」と「ldp」を使ってます。
「stp」はプレインデックスで。
「ldp」はポストインデックスで。
どちらも、インデックスとなるレジスタの更新を含むようです。
16バイトは、少し景気よく取りすぎたかもしれません。
昔は、1つのニーモニックで1つのレジスタしかpush、popできないということもありました。
レジスタの数が増えてくると、push、popするレジスタも増え、それだけでなんだかそれなりのステップ数になってしまう。そのうちに、全レジスタまとめてpush、popというニーモニックもでてきた。
これは2つずつpush、popしています。
.globl mem_cpy
.p2align 2
.type mem_cpy,@function
mem_cpy:
# x0 : コピー先アドレス
# x1 : コピー元アドレス
# w2 : コピーサイズ
stp x0, x1, [sp, #-16]!
stp w8, w9, [sp, #-16]!
mov w9, 0
loop:
ldrb w8, [x1]
strb w8, [x0]
add x0, x0, #0x1
add x1, x1, #0x1
add w9, w9, #0x1
cmp w9, w2
b.lt loop
ldp w8, w9, [sp], #16
ldp x0, x1, [sp], #16
ret