
Notion DBを参照するQAボットをLangChainで作成

はじめに
以前書いたこちらの記事を一部変更してNotion DBを参照するQAボットを作成しました。データソースをテキストからNotion DBとするとともにVectorDBもオンメモリのchromaからPineconeに変更しました。
Google Colabで実行
環境変数にOpenAIとGoogle Search APIのトークンを設定
# OpneAIとGoogle Search APIキー
%env OPENAI_API_KEY = sk-
# https://note.com/npaka/n/nd9a4a26a8932
%env GOOGLE_CSE_ID =
%env GOOGLE_API_KEY = パッケージのインストール
!pip install langchain
!pip install openai
!pip install gradio
!pip install -U pinecone-client
!pip install tiktoken
!pip install gradioNotion DBをロード
Notion DBのロードは、LangChainのドキュメントを参照しました。
Notion DBはLangChainのデモリポジトリに含まれるBlendle Employee Handbookを使用しました。
from langchain.document_loaders import NotionDirectoryLoader
loader = NotionDirectoryLoader("Notion_DB")
documents = loader.load()Pineconeのindexを作成
アカウントを作成してapi_keyとenvironmentを取得します。
https://dev.classmethod.jp/articles/dive-deep-into-modern-data-saas-about-pinecone/
import pinecone
from langchain.vectorstores import Pinecone
pinecone.init(
api_key="xxxxxxxxxxxxxxxxxx",
environment="xxxxxxxxxx"
)
index = 'sample'
if index not in pinecone.list_indexes():
pinecone.create_index(index, dimension=1536)Notion DBをEmbeddingしてPineconeに格納
# Embedding用
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
db = Pinecone.from_documents(docs, embeddings, index_name=index)Tool、Agent、GUIのパッケージをインポート
# Google Search API
from langchain.utilities import GoogleSearchAPIWrapper
# Memory
from langchain.memory import ConversationBufferMemory
# ChatOpenAI
from langchain.chat_models import ChatOpenAI
# VectorDB
from langchain.chains import RetrievalQA
# agentとtool
from langchain.agents import Tool, initialize_agent
# prompt
from langchain.agents import ZeroShotAgent, Tool, AgentExecutor
from langchain import LLMChain
# UI
import gradio as grAI に使用させるツール (Google検索とNotion DB) を定義
# GoogleSearchAPIとvectorDB
search = GoogleSearchAPIWrapper()
notion = RetrievalQA.from_chain_type(llm=ChatOpenAI(), chain_type="map_reduce", retriever=db.as_retriever())
tools = [
Tool(
name = "Search",
func=search.run,
description="useful for when you need to answer questions about current events"
),
Tool(
name = "Notion DB",
func=notion.run,
description="useful for when you need to answer question about Blendle's Employee Handbook."
)
]
# agent が使用する memory の作成
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)Promptを定義
どのツールを使用したか、回答の末尾に追加してもらいます。
prefix = """Answer the following questions as best you can. You have access to the following tools and indicate which tool you used:"""
suffix = """Begin! Use lots of tools, and please answer finally in Japanese. Please indicate which tool you used in parentheses at the end of your answer.
{chat_history}
Question: {input}
{agent_scratchpad}"""
prompt = ZeroShotAgent.create_prompt(
tools,
prefix=prefix,
suffix=suffix,
input_variables=["chat_history","input", "agent_scratchpad"]
)Agentを定義
promptとLLMをLLMChainで組み合わせる
llm_chain = LLMChain(llm=ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.75), prompt=prompt)
# エージェントの準備
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, memory=memory)
# AgentExecuterで実行
agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True, memory=memory)
GUIの定義
responseでagent_executorを使用することを指定
def chat(message, history):
history = history or []
try:
response = agent_executor.run(input = message)
except Exception as e:
response = f"予期しないエラーが発生しました: {e}"
history.append((message, response))
return history, history
chatbot = gr.Chatbot()
demo = gr.Interface(
chat,
['text', 'state'],
[chatbot, 'state'],
allow_flagging = 'never',
)会話の開始
demo.launch(share=False, debug=True)feedback processについて聞いてみる
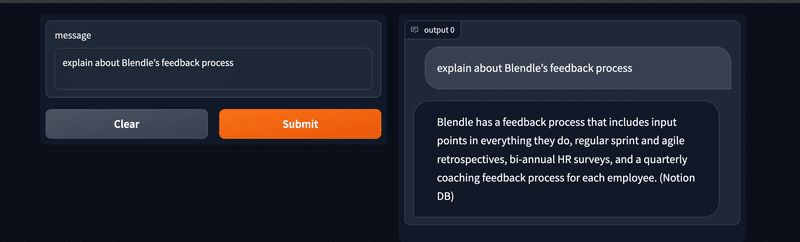
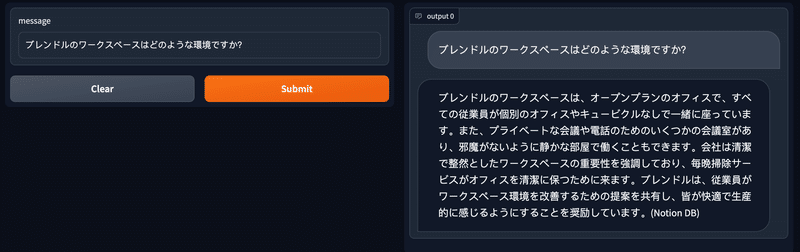
同じ質問に対して使うツールが変わったり、回答に掛かる時間も数十秒とまだ実用には及ばないように思いました。LLMにgpt-3.5-turboを使用していますが、gpt-4が利用できればもう少し精度は上がるかもですね。
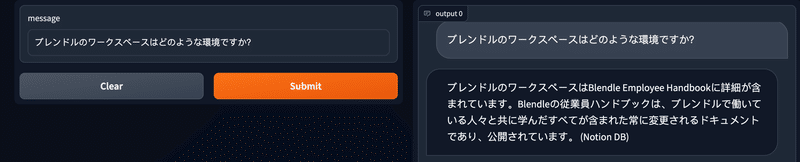
本日GPT-4 APIの招待が届いたので、以下はGPT-4で試しました。
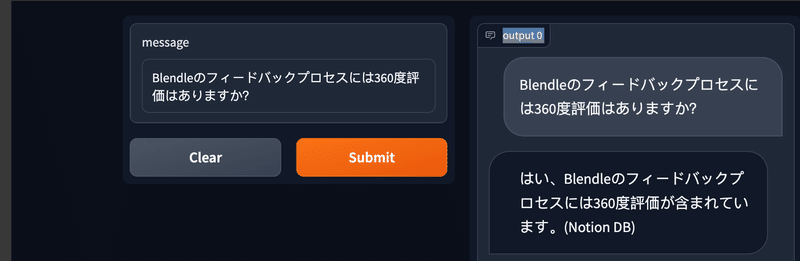
フィードバックプロセスの中身について、問い合わせてみます。
フィードバックプロセスの中に360度評価に関する記述があるので、チャットボットに360度が評価が含まれるのかを問い合わせてみます。
ちゃんと360度評価が含まれることを教えてくれました。gpt-4にした方が、suffixで指定した通り日本語で回答してくれるようになった気がします(英語で聞いても)。
Gradioのタイムアウト
gradioのデフォルトのtimeout時間は60秒で、それまでに回答が生成できないことがたまにあります。その時はキューイングが可能のようです。
https://gradio.app/key-features/#queuing
demo = gr.Interface(
chat,
['text', 'state'],
[chatbot, 'state'],
allow_flagging = 'never',
).queue()実行するときは、Share=Trueとする必要があるようです。
demo.launch(share=True, debug=True)2分以上回答に時間を要しましたが、タイムアウトにならずに答えが返ってきました。
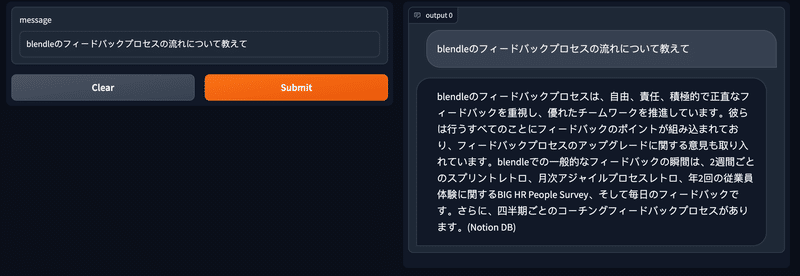
GPT-4とGPT-3.5-turboの比較
GPT-4にしても、回答が返ってくるまでに少し時間は掛かりますが、精度的にはGPT-3.5-turboより改善しているように思いました(個人の感想です)。
この記事が気に入ったらサポートをしてみませんか?