
【機械文芸入門】GPT-2でTwitter小説を呟くbotを作ってみた

※本記事はほぼ全て無料公開にして、「11. おまけ」部分だけを有料にしています。ご支援頂ける方に購入して頂ければ嬉しいです。
本記事では、GPT-2を使って、140字のTwitter小説を呟くTwitterのbotを作ってみます。全部無料(!)で試せます。なるべく分かりやすいように情報をまとめてみたので、色んな方に作ってみて欲しいです。やろうぜ、機械文芸!
ざっくりと全体の流れを説明すると、gpt2-japaneseのコードを改変してGitHubに置き、それをGoogle Cloud Platform(GCP)に連携します。
GCPの利用にはクレジットカード登録が必要ですが、90日間、$300までは無料で使うことができます(2020年11月3日時点)。もし無料枠を超えた場合でも自動的に課金されることはないので、お試しで使うのに良さそうです。
クレジットカードが無くてGCPを使えない場合でも、2章までの内容を使えばローカルで試しに文章を書いてもらうことはできるので、気軽にトライしてみてください。
(もし何か載せたらヤバイ情報があったら、葦沢まで教えて頂けると助かります)
0. 開発環境
Windows
Python3.7
PyCharm(コミュニティ版)
1.GPT-2とは
GPT-2とは、OpenAIが開発した文章生成モデルで、高い精度で文章が生成できることで話題になりました。今はより強いモデルGPT-3が発表されていますが、個人で扱える代物ではなさそうです。。。
GPT-2を利用して日本語で小説を書かせる取り組みは既に行われています。例えばTwitterのbot「ひびのべる」や「BunCho」という小説執筆支援ツールがあります。本記事で覚えたことをベースにして、こうしたサービスの開発に取り組んでみるのも面白そうです。
2.学習済みモデルの利用
今回は、日本語の学習済みモデルを提供してくれているgpt2-japaneseを使います。ありがたい。小説を学習させたモデルも用意されているので、ちょうどいいですね。
本章ではローカルにクローンして、試しに動かしてみます。README.mdを読んでできる方は、この章は読まなくて大丈夫です。
2-1. モデルはv1の小説モデルを使います。新しいv2もありますが、短い入力にはv1が良いらしいので、何も考えずにv1を選択。

2-2. ダウンロードしたら解凍しておきます。Windowsなので、解凍用のフリーソフト(7-Zipなど)を使います。

2-3. GitHubからgpt2-japaneseをcloneします。
PyCharmの場合は、VCS>Checkout from Version Control>Gitを選択。

URLには、GitHubのページの「Code」をクリックして出てくるURLをコピー。

これで「Clone」すればOK。

2-4. 解凍したモデル「ja-117M_novel」をgpt2-japanese直下にコピー。ついでに.gitと.ideaも削除しておきます。
2-5. 足りないライブラリがあればFile>Settings>Project Interpreterの右上の「+」マークから追加。

2-6. とりあえず動くか試します。
gpt2-genetrate.pyの14~19行目にパラメータがあるので、デフォルト値を適宜変更します。
modelは'ja-117M_novel'、contextは'こんにちは。'、top_kは40、top_pは0にします。(デフォルトだと、v2に合わせてtop_kが0、top_pが1になってます)
PyCharmで実行するには、gpt2-generate.pyのタブの上で右クリックして、「Run 'gpt2-generate' 」(右向きの緑矢印)を選択。

うまくいくと、こんな感じで出力されます。Web小説っぽい文章になってますね。

3. コードの追加
Twitterのbot用のコードを追加していきます。gpt2-japaneseはMIT Licenseで公開されているので、改変は自由です。「著作権表示」と「MITライセンスの全文」の記載はLICENSEファイルに記載されているので、このファイルさえ残しておけば大丈夫だと思います。
3-1. gpt2-japanese直下にファイルを作成します(今回はgpt2_novel.pyという名前にしました)。とりあえずgpt2-generate.pyの内容をコピペします。
3-2. 関数にするために、全体をgenerate_novelという関数の下に入れます(13行目)。

3-3. その他もろもろ変更。「# 変更ここから」から下が主に変えたところ(だと思う)。140字以内になるようにテキストを(無理やり)調整しています。
import json
import os
import numpy as np
import tensorflow as tf
import requests
import argparse
from tqdm import tqdm
import sentencepiece as spm
from encoder import get_encoder
from model import default_hparams
from sampling import sample_sequence
def generate_novel():
parser = argparse.ArgumentParser()
parser.add_argument('--model', type=str, default='ja-117M_novel')
parser.add_argument('--context', type=str, default='こんにちは。')
parser.add_argument('--num_generate', type=int, default=1)
parser.add_argument('--top_k', type=int, default=40)
parser.add_argument('--top_p', type=float, default=0)
parser.add_argument('--temperature', type=float, default=1)
args = parser.parse_args()
sp = spm.SentencePieceProcessor()
sp.Load(args.model+"/stm.model")
model_params = '117M'
if '-' in args.model:
model_params = args.model.split('-')[1]
if '_' in model_params:
model_params = model_params.split('_')[0]
if not os.path.isfile(args.model+'/encoder.json'):
for filename in ['encoder.json', 'vocab.bpe', 'hparams.json']:
r = requests.get("https://storage.googleapis.com/gpt-2/models/" + model_params + "/" + filename, stream=True)
with open(args.model+'/'+filename, 'wb') as f:
file_size = int(r.headers["content-length"])
chunk_size = 1000
with tqdm(ncols=100, desc="Fetching " + filename, total=file_size, unit_scale=True) as pbar:
# 1k for chunk_size, since Ethernet packet size is around 1500 bytes
for chunk in r.iter_content(chunk_size=chunk_size):
f.write(chunk)
pbar.update(chunk_size)
batch_size=1
length=None
temperature=args.temperature
top_k=args.top_k
top_p=args.top_p
enc = get_encoder(args.model)
hparams = default_hparams()
with open(args.model+'/'+'hparams.json') as f:
hparams.override_from_dict(json.load(f))
if length is None:
length = hparams.n_ctx // 2
elif length > hparams.n_ctx:
raise ValueError("Can't get samples longer than window size: %s" % hparams.n_ctx)
with tf.Session(graph=tf.Graph()) as sess:
context = tf.placeholder(tf.int32, [batch_size, None])
output = sample_sequence(
hparams=hparams, length=length,
context=context,
batch_size=batch_size,
temperature=temperature, top_k=top_k, top_p=top_p
)
saver = tf.train.Saver()
ckpt = tf.train.latest_checkpoint(args.model)
saver.restore(sess, ckpt)
generated = 0
while True:
printed = 0
raw_text = sp.EncodeAsPieces(args.context) if args.context!= '<|endoftext|>' else '<|endoftext|>'
raw_text = ' '.join([r for r in raw_text if r!='▁'])
text = ''
while True:
context_tokens = enc.encode(raw_text)
out = sess.run(output, feed_dict={
context: [context_tokens for _ in range(batch_size)]
})[:, len(context_tokens):]
splitted = enc.decode(out[0]).split('<|endoftext|>')
# 変更ここから
text += splitted[0].replace(' ','')
end_list = ["。","」","?","!"]
text_list = []
sentence = ""
for w in text:
sentence += w
if w in end_list:
text_list.append(sentence)
sentence = ""
tweet = ""
for tx in text_list:
if len(tweet + tx) > 140:
break
else:
tweet += tx
break
break
return tweet
if __name__ == '__main__':
novel = generate_novel()
print(novel)3-4. 続いて、gpt2-japanese直下にツイート用のファイルを作成(main.py)。各認証情報は、TwitterのAPIの情報に入れ替えます。
import twitter
import gpt2_novel
def tweet(request):
auth = twitter.OAuth(consumer_key="*****",
consumer_secret="*****",
token="*****",
token_secret="*****")
text = gpt2_novel.generate_novel()
t = twitter.Twitter(auth=auth)
status=text
t.statuses.update(status=status)Twitter APIについては、bot用にTwitterのアカウントを取得して、Twitter Developerの開発者申請をしておきましょう。
複数のTwitterアカウントを作る場合は、以下のサイトが分かりやすいです。
また複数のメールアドレスがなくても、Gmailのアドレスが一つあれば、「.」や「+」を組み合わせて使い分けることができます。
Twitter Developerの開発者申請と認証情報の作成は、こちらのサイトを参考にしました。
3-5. requirements.txtに「twitter」を追記。

3-6. .gitignoreファイルを作成します。このファイルに記載したファイルやフォルダは、次章で説明するGitHubへの連携の際に連携されなくなります。
エクスプローラでgpt2-japaneseを開き、「.gitignore.」という名前でファイルを作成します。

PyCharmで.gitignoreを開いて、以下のように記載します。モデルは大きいので、直接アップロードしません。後述しますが、モデルの置き場所にはGoogle Cloud PlatformのCloud Storageを使います。
ja-117M
ja-117M_novel
__pycache__
.idea4. GitHubと連携
続いてGitHubにプライベートリポジトリを作成して、pushします。GitHubはバージョン管理サービスです。コードの変更を記録しておいたり、複数人で開発する時によく使われます。GitHubにアカウントが無い方は登録してください。
4-1. 新規リポジトリを作成。特に理由が無ければ、Privateを選択します。

4-2. PyCharmの画面下のTerminalタブを選択して、gpt2-japaneseの直下にいることを確認して「git init」をします。
git init4-3. GitHubにて、作成したリポジトリのページの「Code」をクリックして出てくるURLをコピー(SSHの方)。
4-3. PyCharmのTerminalで、「git remote add origin (作成したリポジトリのURL)」を実行。
git remote add origin *****4-4. PyCharmのTerminalで、「git config --get remote.origin.url」を実行して、自分のリポジトリが設定されていることを確認してください(元のリポジトリに連携しないように注意してください)。
git config --get remote.origin.url4-5. PyCharmのTerminalで、「git add .」。
git add .4-6. PyCharmのTerminalで、「git commit -m "***"」(「***」部分はコミットの内容が分かるようにコメントを入れてください)。
git commit -m "first commit"4-7. PyCharmのTerminalで、「git push -u origin master」。上手くいくと、GitHubへのアップロードが始まります。
git push -u origin master4-8. GitHubのリポジトリのページを見てみると、ちゃんとpushされているのが確認できます。

5. Cloud Source Repositoriesへのミラーリング
GitHubで管理するコードをGoogleのCloud Source Repositoriesにミラーリングします。初めからCloud Source Repositoriesに連携してもいいのですが、エラーなどあった時にGitHubの方がネットに情報が多いので、GitHubを使った方がいいかなと個人的には思います。
5-1. 「Google Cloud Platform」のメニューから「Source Repositories」をクリック。

5-2. やりたいのはGitHubとの接続ですが、最初は空のリポジトリを作らないと接続できないので、新しいリポジトリを作成します。

5-3. 適当にリポジトリ名を入力して、プロジェクトを作成して、リポジトリを作成。

5-4. リポジトリが作成できるとこんな画面になるので、一旦Cloud Source Repositoriesのトップに戻ります。

5-5. 画面右上の「リポジトリを追加」をクリック。
![]()
5-6. 今度は「外部リポジトリの接続」を選択。(※初めから「外部リポジトリの接続」を選択するとエラーになるので、先に空のリポジトリを作りました)

5-7. 先程作ったプロジェクトを選択。プロバイダにGitHubを選択して、GitHubにサインインした後、接続したいリポジトリを選択して接続。
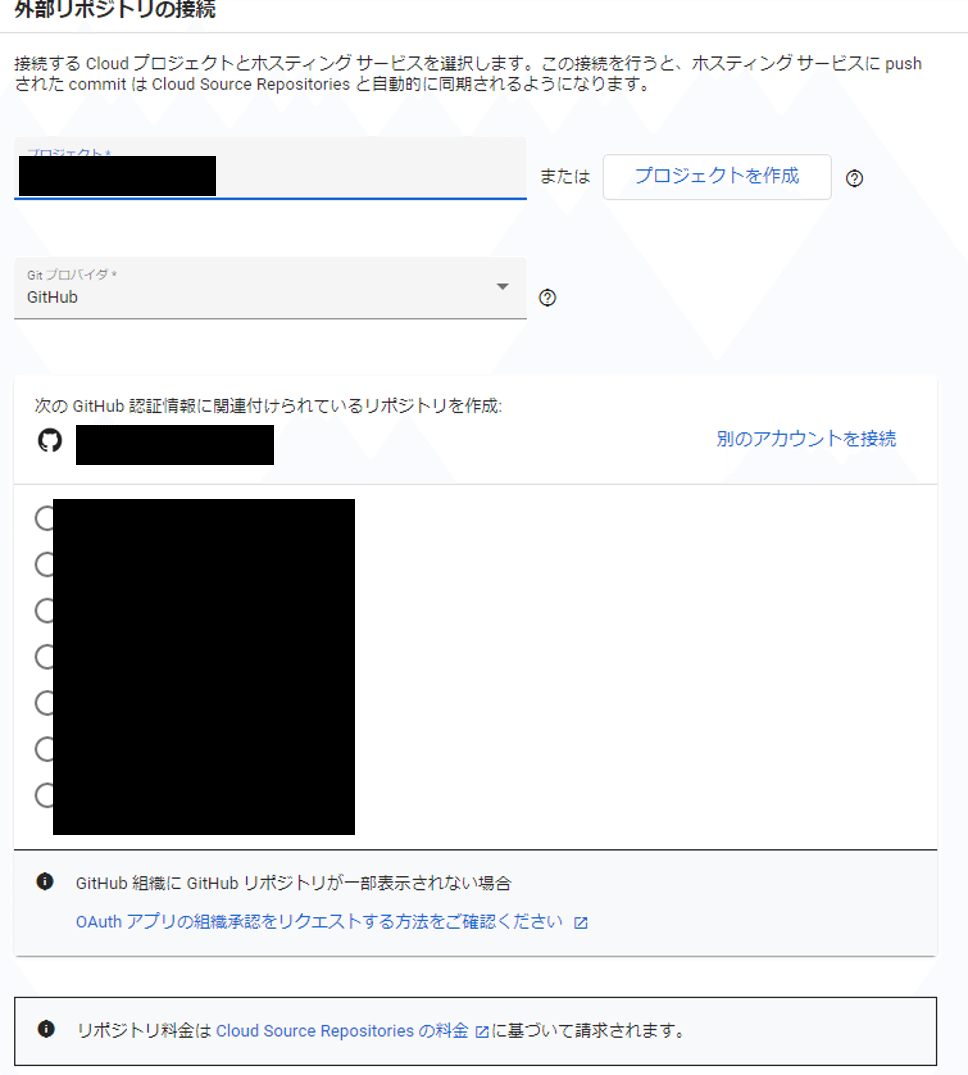
5-8. うまくいけば、Cloud Source Repositoriesでこのように表示されます。選択すると、ちゃんと中身も表示されます。


5-9. ここからはGCP向けにコードを改変します。
PyCharmにて、requirements.txtに「google-cloud-storage」を追加。
tqdm
numpy
sentencepiece
tensorflow-gpu==1.15.4
twitter
google-cloud-storage5-10. gpt2_novel.pyにCloud Storageからファイルをダウンロードする関数を追加。
def get_from_storage(filename):
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket('ja-117m_novel')
blob = bucket.get_blob(filename)
blob.download_to_filename("/tmp/" + filename)5-11. 合わせてgpt2_novel.pyのgenerate_novelも改変。
def generate_novel():
parser = argparse.ArgumentParser()
parser.add_argument('--model', type=str
, default='/tmp') #/tmpに変更
parser.add_argument('--context', type=str, default='こんにちは。')
parser.add_argument('--num_generate', type=int, default=1)
parser.add_argument('--top_k', type=int, default=40)
parser.add_argument('--top_p', type=float, default=0)
parser.add_argument('--temperature', type=float, default=1)
args = parser.parse_args()
# storageからダウンロードするコードを追加
model_filenames = ['checkpoint','encoder.json','hparams.json','model-7028700.data-00000-of-00001'
,'model-7028700.index','model-7028700.meta','stm.model','stm.vocab','vocab.bpe']
for f in model_filenames:
get_from_storage(f)
sp = spm.SentencePieceProcessor()
sp.Load(args.model+"/stm.model")
model_params = '117M'
# コメントアウト
# if '-' in args.model:
# model_params = args.model.split('-')[1]
# if '_' in model_params:
# model_params = model_params.split('_')[0]
if not os.path.isfile(args.model+'/encoder.json'):
for filename in ['encoder.json', 'vocab.bpe', 'hparams.json']:
r = requests.get("https://storage.googleapis.com/gpt-2/models/" + model_params + "/" + filename, stream=True)
with open(args.model+'/'+filename, 'wb') as f:
file_size = int(r.headers["content-length"])
chunk_size = 1000
with tqdm(ncols=100, desc="Fetching " + filename, total=file_size, unit_scale=True) as pbar:
# 1k for chunk_size, since Ethernet packet size is around 1500 bytes
for chunk in r.iter_content(chunk_size=chunk_size):
f.write(chunk)
pbar.update(chunk_size)
batch_size=1
length=None
temperature=args.temperature
top_k=args.top_k
top_p=args.top_p
enc = get_encoder(args.model)
hparams = default_hparams()
with open(args.model+'/'+'hparams.json') as f:
hparams.override_from_dict(json.load(f))
if length is None:
length = hparams.n_ctx // 2
elif length > hparams.n_ctx:
raise ValueError("Can't get samples longer than window size: %s" % hparams.n_ctx)
with tf.Session(graph=tf.Graph()) as sess:
context = tf.placeholder(tf.int32, [batch_size, None])
output = sample_sequence(
hparams=hparams, length=length,
context=context,
batch_size=batch_size,
temperature=temperature, top_k=top_k, top_p=top_p
)
saver = tf.train.Saver()
ckpt = tf.train.latest_checkpoint(args.model)
saver.restore(sess, ckpt)
generated = 0
while True:
printed = 0
raw_text = sp.EncodeAsPieces(args.context) if args.context!= '<|endoftext|>' else '<|endoftext|>'
raw_text = ' '.join([r for r in raw_text if r!='▁'])
text = ''
while True:
context_tokens = enc.encode(raw_text)
out = sess.run(output, feed_dict={
context: [context_tokens for _ in range(batch_size)]
})[:, len(context_tokens):]
splitted = enc.decode(out[0]).split('<|endoftext|>')
# 変更ここから
text += splitted[0].replace(' ','')
end_list = ["。","」","?","!"]
text_list = []
sentence = ""
for w in text:
sentence += w
if w in end_list:
text_list.append(sentence)
sentence = ""
tweet = ""
for tx in text_list:
if len(tweet + tx) > 140:
break
else:
tweet += tx
break
break
return tweet6. Cloud Storageへのモデルのアップロード
gpt2-japaneseのモデルは、Cloud Storageに置いておきます。
6-1. GCPのStorageにアクセスして「バケットを作成」を選択。

6-2. バケットの名前は「ja-117m_novel」(get_from_storage関数内で指定しているフォルダ)にします。バケット名に大文字は使えないようです。

6-3. 保存場所は、分からないので「Region」と「東京」を選択しておきました。

6-4. 「Standard」を選択。

6-5. アクセス制御はIAMで良いかと思って「均一」にしました。これで「作成」をクリック。

6-6. バケットが作成されたので、「ファイルをアップロード」からローカルの「ja-117M_novel」フォルダに入っているファイルを全てアップロードします。少し時間がかかります。

6-7. 続けて、サービスアカウントを作成します。メニューの「IAMと管理」から「サービスアカウント」を選択し、上の「+サービスアカウントを作成」をクリック。

6-8. サービスアカウントの名前を入れます。後で見た時に、何に使っているか分かりやすい名前にした方がいいと思います。サービスアカウント名とサービスアカウントIDは後で使うので控えておくと便利。できたら「作成」をクリック。

6-9. 続けて、作成するサービスアカウントにロール(権限)を付与します。ここでは「Cloud Scheduler 管理者」と「Cloud Functions 起動元」を選択します。ロールを追加したら「完了」をクリック。

6-10. 次は、サービスアカウントに、Storageを使う権限を付与します。メニューからStorageにアクセスし、「ja-117m_novel」のチェックボックスにチェックを入れて、右端の「メンバーを追加」をクリック。
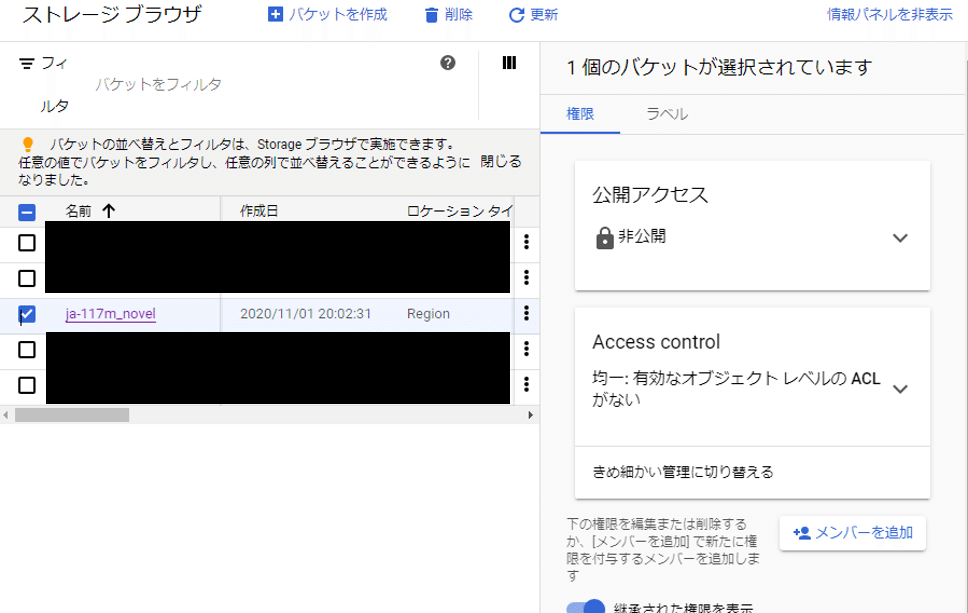
6-11. 「新しいメンバー」に、6-8.で作成したサービスアカウントIDを選択。「Storage レガシー バケット読み取り」、「Storage オブジェクト 閲覧者」を追加して「保存」をクリック。

7. Cloud Functionsの設定
実行するための関数としてCloud Source Repositoriesに連携したリポジトリを設定します。
7-1. Cloud Functionsにアクセスし、「関数を作成」をクリック。
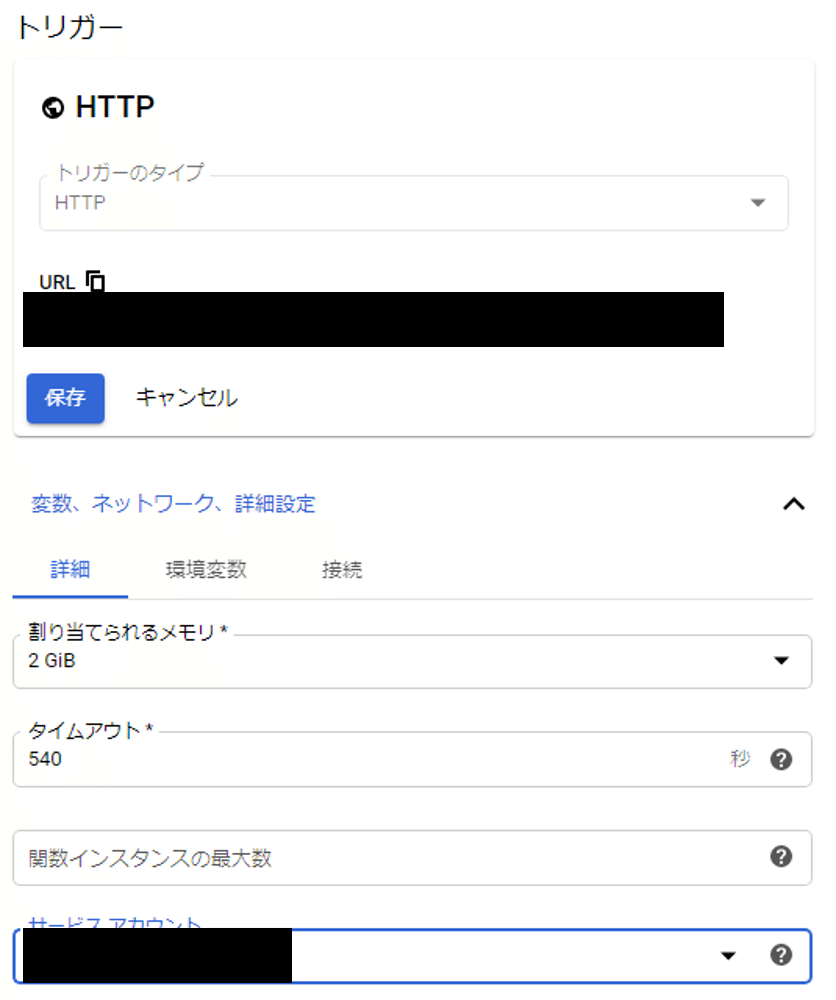
7-2. 「関数名」は適当に。「リージョン」はよく分からないので「asia-northeast1」にしました。トリガーのタイプは「HTTP」。トリガーの下に記載されているURLは、後で使うので控えておくと便利です。
続いて「変数、ネットワーク、詳細設定」を開いて、「割り当てられるメモリ」には「2GiB」、「タイムアウト」には「540」。「サービスアカウント」は、6-8.で作成したサービスアカウントを選択します。「保存」をクリックしたら、画面左下にある「次へ」をクリック。
7-3. 以下のように設定してデプロイ。
ランタイム:Python3.7
ソースコード:Cloud Source Repositries
リポジトリ:(5-8.で表示されている、GitHubと連携させたリポジトリ名)
ブランチ/タグ:ブランチ
ブランチ名:master
ソースコードを含むディレクトリ:/ (※main.pyがあるディレクトリを指定します)
エントリポイント:tweet (※実行したい関数。今回はmain.pyのtweet)

7-4. デプロイが始まると自動的に画面が遷移します。関数名の左のマークがしばらくグルグル回り、緑のチェックになったらOK。「!」マークになったらログを確認してエラー部分を修正してください。私はここで試行錯誤しました。修正は記事中に反映しているので、エラーは出ないと信じたい……。

7-5. デプロイが成功したら、関数の右端にある「操作」から「関数をテスト」をクリック。

7-6. 左下の「関数をテストする」をクリックして、実際に動かしてみます。

7-7. しばらく待っていると、こうなります。一旦閉じます。

7-8. 「ログ」タブをクリックして、ログを表示させます。分かりにくいですが、一番下に「Function execution took 79120 ms, finished with status code: 200」と出ています。実はコード200は、リクエストが成功したことを意味しています。つまり、動作はしている(!)ということです。

7-9. Twitterを確認すると、ツイートができています。(私は2回テストしたので、2回ツイートされています。ちなみにテスト中は鍵垢にしておいた方が無難です)

8. 実行スケジュール設定
ここまでくれば、あと少し。Cloud Schedulerで、定期的にツイートするための設定をします。
8-1. メニューから「Cloud Scheduler」にアクセス。「ジョブを作成」をクリック。

8-2. リージョンは、東京の「asia-northeast1」を選択しました。

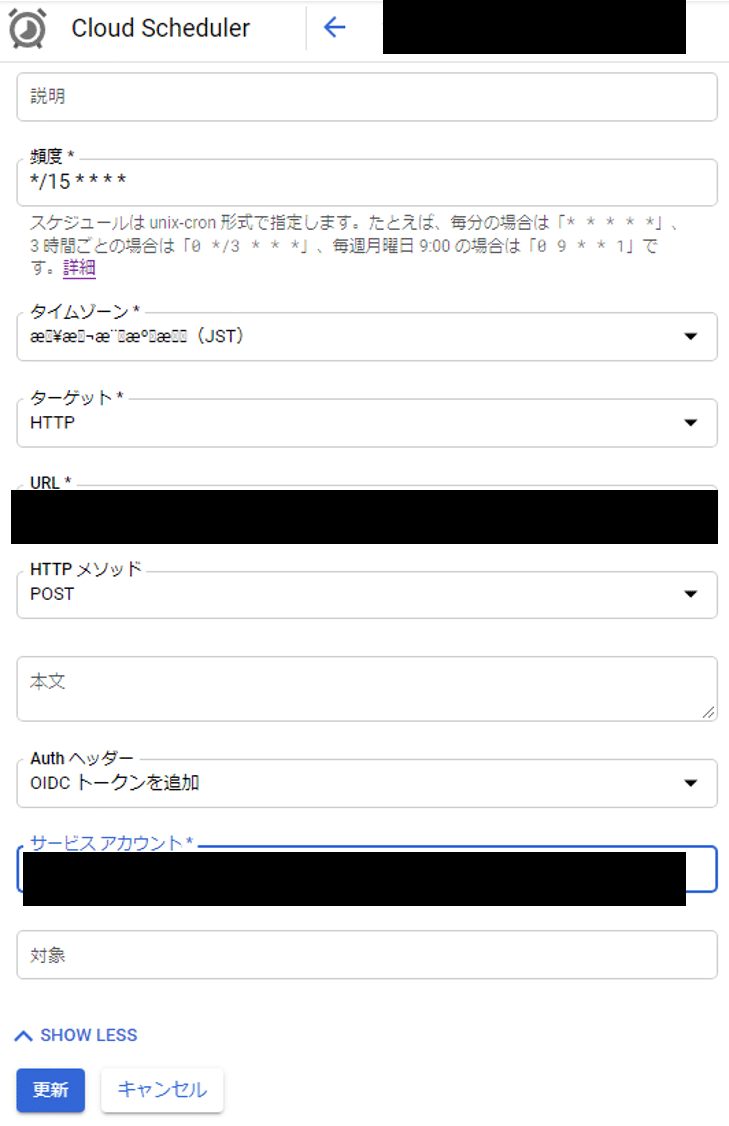
8-3. 1分ほど待つと画面が遷移します。「頻度」はunix-cron形式で入力します。「*/15 * * * *」で15分ごとに実行できるようになります。「タイムゾーン」は文字化けしてましたが、「JST」と入っているので合ってるでしょう。「URL」には、7-2.でトリガーの下に記載されていたURLを入力します。Authヘッダーには「OIDCトークンを追加」。最後に、作成したサービスアカウントを追加。できたら「作成」をクリック。
8-4. これで設定は完了です。右端の「今すぐ実行」をクリックしてみましょう。

8-5. 「成功」と出ていればツイートができているはずです。「失敗」と出ている時は、「表示」からログを見て原因を探りましょう。
![]()
9. 参考にしたサイト様
10. 最後に
今回、私が作成したアカウントは「吟遊作家リャカ(@AI_writer_Ryaca)」です。

記事のままだとデフォルトで「こんにちは。」より後の文章しかツイートされないので、例えばcontextのパラメータも一緒にツイートに含めたり、他のアカウントからのリプライの文章をAPIで取得してcontextのパラメータにしたり、モデルをv2に変えてみたり、色々と工夫できると思います。オリジナルのbotになるようにカスタマイズしてみましょう。
上の画像のように、ハッシュタグをつけた投稿も可能ですが、既存のタグを付けてしまうとbotで埋め尽くしてしまって迷惑になるので、邪魔にならないタグを使ってください。
皆さんもこの記事の内容をマスターして、機械文芸部の仲間入りをしましょう!
ちなみに、次章「11. おまけ」では、「吟遊作家リャカ」の名前の由来を書きました。ご購入頂けると嬉しいです。
ここから先は
¥ 1,000
この記事が気に入ったらサポートをしてみませんか?