
プロンプトエンジニアリングに経路探索アルゴリズムの思考法を応用してみる

はじめに
本noteの想定読者は以下の通りです。
・なんとなく、プロンプトエンジニアリングとはどういうものか知っている。
・自分でCoTなどの手法を試したことがある。
・プロンプトエンジニアリングに興味がある。
・間違いがあっても優しく訂正してくれる。
このnoteでは、CoTやToTという名称で知られるプロンプトエンジニアリングの手法からヒントを得て、経路探索アルゴリズムを利用したGPT-4で使えるプロンプトを作ってみよう!という実践記録です。
必ずしも論文のように再現性のある確実な結果について言及しているわけではないのと、一部論理的な間違いが含まれている可能性があることについて、予めお詫び申し上げます。
著者はプロンプトエンジニアリングのハッカソン(プロンプトソン)で優勝するくらいプロンプト大好きですが、元来AI研究をしていたわけでも、数学をやっていたわけでもない人間なので、ロジックのところは穴がある可能性があります。ご注意ください。
CoT(Chain of Thought)とは
CoT(Chain of thought、思考の連鎖)は、大規模言語モデル(LLM)のプロンプトエンジニアリング手法であり、問題解決のためのロジカルな思考を助けるための手法です。
LLMに対して多段階の問題の最終回答に至るまでの一連の中間ステップを生成するように促すことで、その推論能力を向上させます。
例えば、
今の冷蔵庫の中身は鶏肉、卵、レタス、トマト、チーズです。
全て昨日購入したものですが、まずは、この中から賞味期限の観点から優先的に使うべき食材をリストアップして下さい。
次に、これらの食材を用いて作れるお惣菜を10種類リストアップして下さい。
次に、お惣菜リストの全てのレシピを箇条書きで完結に記述して下さい。
次に、各レシピの想定調理時間を概算してリストに書き加えて下さい。
お惣菜のリストのうち、想定調理時間が30分未満のもののみに絞り込んでください。
絞り込まれたお惣菜リストのうち、カロリーと塩分量の低いレシピを絞り込んで表示して下さい。
最後に、和食好きの私の夕食を想定して一つのレシピを紹介して下さい。
こんな感じで、思考プロセスを明確に指示&思考させることで、狙った出力を得やすいという特徴があります。
ToT(Tree of Thought)という新手法
2023年の5月17日にTree of Thoughtという論文が発表されました。
CoTの概念を更に拡張した推論プロンプトエンジニアリングの手法だと考えられます。
※本稿では、この論文をベースに独自の解釈を交えながら新しいプロンプトエンジニアリングの手法について言及します。
必ずしも論文の趣旨に沿っているわけではないことをご了承下さい。
[2305.10601] Tree of Thoughts: Deliberate Problem Solving with Large Language Models (arxiv.org)
簡単にToTを解説すると、一連の思考連鎖であったCoTと比べて、複数の思考ルートを考慮し、それを探索アルゴリズム(を模倣したアルゴリズム)によって探索するというところがポイントになると思います。
探索アルゴリズムは主に幅優先探索(BFS)と深さ優先探索(DFS)が使い分けられており、それぞれプロンプトにすると以下のような例でイメージ出来ると思います。
幅優先探索(BFS)の例:
ゴール:「ChatGPTについてのユニークな記事タイトルを考える」
▼プロンプト
Step1 : ChatGPTについて考えると、どのような記事のタイトルが思い浮かびますか?最もユニークなタイトルを5つ提案して下さい。
Step 2 : これらのタイトルそれぞれについて、そのユニークさを1~10までのスケールで評価して下さい。
Step 3 : 最も高い評価を受けたタイトルについて、さらに改善する方法はありますか?それともそのままで最適だと思いますか?
深さ優先探索(DFS)の例:
ゴール:「ChatGPTについてのユニークな記事タイトルを考える」▼プロンプト
Step1 : ChatGPTについて考えると、どのような記事のタイトルが思い浮かびますか?最もユニークなタイトルを1つ提案して下さい。
Step 2 : 提案されたタイトルについて、そのユニークさを1~10までのスケールで評価して下さい。
Step 3 : 提案されたタイトルが10点満点でない場合、そのタイトルをどのように改善できるか提案して下さい。それともそのままで最適だと思いますか?
その名の通り、幅方向に優先的に探索するか、深さ方向に優先的に探索するかの違いですね。
実際にGPT-4で実行してみると、BFSのプロンプト例は一度の探索で「そのままでも最適」に行きつきやすく、DFSの方は一度のみ改善提案をしてくれることが多いことが分かります。
これは、GPT-4においてトークン数の制限や、無限に回答を引き延ばそうとしないような特性が作用している可能性が高く、あまり適切な検証とは言えなさそうです。
また、このプロンプトはあくまでイメージ例であり、実際に論文で用いられているGame of 24やMini Crosswordsの例とは異なる点も多いです。ご注意ください。
実際にToTを実装するためには、以下のようなフェーズを定義するプロンプトをそれぞれ記述し、アルゴリズムとしてループ内に組み込むような設計が必要かもしれません。
提案フェーズ:言語モデルは、問題解決のための可能なステップやアイデアを提案します。これは一度だけではなく、複数回行われ、複数の提案が生成されます。
評価・選択フェーズ:次に、言語モデルは、それぞれの提案を評価します。評価は、提案が問題解決にどれだけ貢献するか、または提案が目標にどれだけ近づけるかに基づいています。評価も一度ではなく、各提案に対して行われます。評価が終わったら、最も評価が高かった提案が選択され、次のステップとして採用されます。
反復フェーズ:選択された提案が目標の達成に十分でない場合、このプロセスは新たな提案フェーズから再度始まります。これは、新たな提案が生成され、評価され、選択されるまで繰り返されます。

A*アルゴリズム
経路探索といえば個人的にはA*アルゴリズムも有名ですね。
簡単に解説すると、
A* アルゴリズムは、「グラフ上でスタートからゴールまでの道を見つける」というグラフ探索問題において、 ヒューリスティック関数 h(n) という探索の道標となる関数を用いて探索を行うアルゴリズムである。
A*における主要な要素をプロンプトエンジニアリング的に書き表すと以下の様になるのではないでしょうか。
ノード(Node): 特定の思考ステップやアイデアであり、Chain of Thoughtでいう"Thought"の部分。開始ノードは問題解決の初期状態、目標ノードは問題解決の最終目標、その間の任意のノードは中間の思考ステップやアイデアを表します。
エッジ(Edge): 一つの思考ステップから次の思考ステップへの遷移。エッジのコスト(重み)は、その遷移がどれだけ効果的であるかとして捉えることが出来ます。
ヒューリスティック関数(Heuristic Function): 特定の思考ステップから目標までの推定コストを提供する関数。この推定コストは、その思考ステップが目標達成にどれだけ寄与するか、またはその思考ステップから目標達成までにどれだけの労力が必要であるかを表すことができます。
g(n): 開始ノードから特定のノードnまでの実際の最小コスト。
h(n): 特定のノードnから目標ノードまでのヒューリスティック推定コスト。
f(n): g(n)とh(n)の和。
オープンリスト(Open List): まだ評価されていないノードのリストを表します。潜在的な解決策として考えられます。
クローズドリスト(Closed List): これはすでに評価されたノードのリストを表します。
ここから更に、魔改造します。
元々、コスト(経路の移動距離)をベースに作成されているA*アルゴリズムですが、プロンプトエンジニアリングでは違う物差しを用意する必要があります。
なぜなら、思考自体は(ある程度)AIが行うので、その労力は限りなく無視して良く、むしろ成果物の完成度ないし質の方が重要視されるべきだからです。
試しに以下の様なプロンプトを考えてみます。
実行はShow Me PlugInを入れたGPT-4環境を想定しています。
プロンプトエンジニアリングにおける思考プロセスを、A*アルゴリズムを応用して当てはめて考えてみます。
開始ノードは「ChatGPTを社内利用する際の利用規約を記述して下さい。」であり、目標ノードは「利用規約の提出(目標は本問題空間上に複数点存在すると仮定する)」として、A*アルゴリズムを日本語で以下の様に実行して下さい。
###変数や関数の定義
・ノード番号{n}:数字
・ノードのフェーズ{Phase}:"仮想" or "提案" or "思考"
・コンテンツ{Content}:文章
・コンテンツ思考結果{Thought Result}:Contentの思考結果の文章
・コンテンツの思考に必要だが現時点で不足している情報リスト[Missing Info List]:文章または語彙のリストですが、個数は0個でも構いません。
・疑似ヒューリスティック関数h(n):現在のノードから見て、目標ノードが複数存在する仮説に基づき、その中でも最善の解を導出できる確率(%)
###プロセス
1. 以下のノード定義を用いてn=1である開始ノードの提案フェーズをmermaid記法のクラス図で描画して下さい。
2. 提案フェーズのノード内にあるMissing Info Listを参照します。あなた自身で解決できるものは除き、ユーザの好みや意見が必要なもののみ、ユーザに質問して下さい。このとき、必ず解答例を併記すること。
3. (回答を待機)
4. ユーザの回答を元にn=1の思考フェーズをクラス図で描画して下さい。
5. 思考フェーズにて決定されたn+1のノードの提案フェーズに対して1を実行し、ループする。
###ノードの定義
ノードには3つのフェーズを定義します。
####提案フェーズ
n, Phase, Content, Missing Info List, h(n)をオブジェクト内に持つ
提案フェーズのノードには、次に検討が必要だと考えられるいくつかの仮想フェーズのノードが依存状態で紐づきます。
####思考フェーズ
n, Phase, Thought Result, h(n)をオブジェクト内に持つ
提案フェーズにて依存で紐づいていた仮想フェーズのノードの中からh(n+1)が最も大きいノード1つのみを依存する
####仮想フェーズ
n, Phase, Content, h(n)をオブジェクト内に持つ
###ループ
...→ノードnの提案フェーズ→現時点で不足している情報リストからユーザに質問→ノードnの思考フェーズ→...
この時、h(n+1)<h(n)であったならば、再度ノードnを提案フェーズから実行する。
###ループ終了条件
思考フェーズのコンテンツが目標ノードと一致したらループを終了。ポイントは、ヒューリスティック関数の概念をまるで違うものに置き換えている点です。
ここまでくると、A*がベースなのかBFSがベースなのかDFSがベースなのか分かりません。アルゴリズムの専門家では無いので、その辺はお許し下さい…&優しく訂正して下さい…。
実行すると、以下のようなクラス図を吐いてくれます。

「とりあえず、書きたいトピックの優先順位とか教えてや」
「あ、でも、このまんま答え出そうとすると、良い回答が出る確率は50%やで」
「次はこういうの考えると良いと思うで」
「特に未来の話について考えると良い回答出す確率80%まで上がるで」
的なことを教えてくれます。

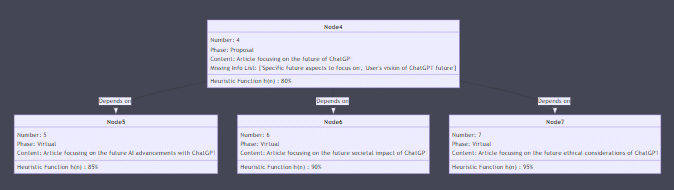
質問に答えたりしていくと、こうやって自動でループ進行してくれます。
途中で書いたBFSやDFSのプロンプト例とかと比べると、まだゆったり?じっくり?検討してくれている感じがします。
どういう結果になるかは….
ぜひお試しください!
さいごに
なんかいい感じな気もするし、なんか違う感じもする、よく分からない時点での思考の共有でした。
そもそもプロンプトエンジニアリングの基本はCoTだと思っていて、問題空間における思考ノードをいくつか経由しつつこれが解にたどり着くというイメージのもっともシンプルな形状だと考えている為です。(IO Promptは除く)
Tree of ThoughtもCoTの拡張系として非常に素晴らしい発見だと思う反面、実態はもっと三次元空間のネットワーク状態として捉えることも出来るんじゃないかと思っているわけです。
Network of Though(NoT)みたいな感じでしょうか。
人間もそうですが、いくつかの思考間をいったり来たりしながら相互補完しつつ、急な外部要因などによって思考が飛躍したりしながら解決へ思考連鎖を続けると思うのですが、ToTではそこまでを再現していません。
ニューロンとかが連想されるんで結局機械学習に戻ってきそうな気もします。良く分かりません。
個人的には、Thoughtの形式がもうちょっといい感じに定義出来たらもっといい感じになるんじゃないかな~とかふわふわしたことを考えています。
え、もうちょっとまとまってから書けって?
それだと誰か先に書いちゃうかもしれないじゃないですか…
(もしニーズあるかも?と思ったら、もうちょっと頭を整理しつつ、方法としてまとめてnoteに書きます。のでぽちっとぜひ!)
この記事が気に入ったらサポートをしてみませんか?