
記者に特化した音声認識モデル(Whisper)を作った話

こんにちは、メディア研究開発センターの山野陽祐です。
先日、朝日新聞の記者に特化したWhisper (音声認識モデル)を構築し、3月末から社内向けツール「YOLO」にて運用を開始しました。それに至るまでの道のりをこちらの記事でご紹介します。
なお、学習データとして活用するファイルは、社内会議や公の記者会見とし、個人情報やセンシティブな情報が含まれるファイルは使用しておりません。
データ
「YOLO」は音声や動画の文字起こしをする社内向けのサービスで、約2年前にリリースしました。この間にアップロードされた音声ファイルや動画ファイルは数千時間におよび、そのうち学習に使えるデータも多くあります。
ここでは、YOLOで蓄積されたデータを紹介し、続いて学習データや評価データについても述べます。
YOLOデータ
アップロード時、ユーザーにファイルの"ジャンル"を指定してもらうようなサービス設計をしています。
ここで、朝日新聞デジタルの記事分類表を参考に9つの選択肢からなるものを”ジャンル”としています。
これまでにYOLOでアップロードされたデータの内訳を以下に示します。

社会やスポーツ、政治に関するファイルが多くアップロードされていることがわかりました。
学習データ
学習データは上述した”YOLOデータ”から作成しており、現時点(2023/5月)で数百時間分のラベル付きデータを蓄積しています。作成方法は以下のテックブログで紹介しているので興味があれば一読ください。
学習データの内訳は以下の通りです。

YOLOデータと学習データは異なる分布になっているようです。これは、ユーザーが指定した”学習提供可のデータのみ”を学習データとしているため、このような分布の違いが生じたのだと考えられます。
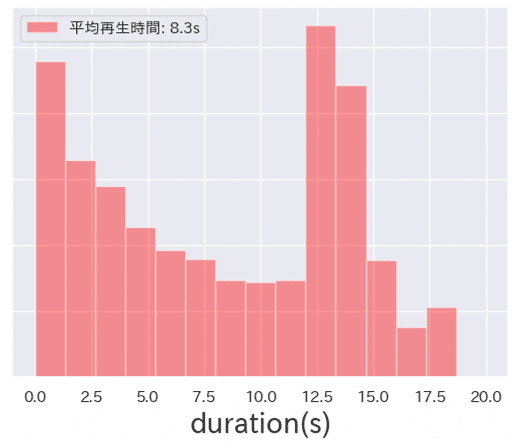
また学習データの再生時間は以下のような分布となりました。
0sから1s、12.5sから15sまでが最も多い平均8.3sのデータセットとなりました。
評価データ
評価データは主に3つのデータセットを使用しています。順に説明していきます。FLEURSやcommonvoiceなども評価データセットとして活用していますが、今回は割愛させていただきます。
YOLO
まずはYOLOデータで構築した評価データセットです。総再生時間は40分ほどからなる、データセットとなります。
内訳は以下の通りとなります。

実データに分布が近づくようにジャンルを選定しつつアノテーションをしたため、YOLO評価データセットはYOLOデータと似たような内訳になっています。
一方で再生時間は12.5-15.0sで多くが構成されています。これは短すぎる音声を評価データセット作成時に意図的に排除しているためです。理由は、短すぎる音声は「はい」や「こんにちは」など意味をなさない言葉で多く占めており、不要だと判断したためです。

YouTube
YouTube動画から音声コーパスを構築することができるjtubespeechを活用して収集したデータに対して、さらに人手でアノテーションを行い評価データセットを作成しました。総再生時間が1.5時間からなる評価データセットです。また、YOLOの評価データセットのように意図的に短い音声を排除することはなく、ランダムサンプリングによるアノテーションを行なっています。

モデル構築
さてここからはモデル構築について説明していきます。
2022年9月ごろにOpenAIからWhisperというモデルとそれに関する論文が公開されました。アーキテクチャーはシンプルなEncoder DecoderのTransformerで構成されており、webから収集した68万時間という巨大なデータセットから学習したものとなっています。wav2vec 2.0のように、ラベル付きデータをもとにFine-tuningすることなく、あらゆる音声を高い精度で認識することができるものです。詳しくはこちらの論文で書かれています。
ここでは、OpenAIが提供しているWhisperの性能を検証するとともに、自社データセットでFine-tuningしたモデルの性能評価の結果などを説明します。
実験 ~OpenAI Whisperの性能検証~
まずはOpenAI Whisperモデルが朝日の評価データセットでどれぐらいの性能が出るのか検証してみました。条件は以下の通りです。
Whisper Largeモデル
num_beams: 5
do_sample: False
no_repeat_ngram_size: 10ここで、no_repeat_ngram_sizeを設定したのはrepetitionが起こることが事前の実験でわかっていたためです。
評価結果は以下の通りとなりました。

ここで、すでに構築済みであったwav2vec 2.0との比較結果を載せています。なお、wav2vec 2.0モデルの結果はshallow fusion と呼ばれる方法で、wav2vec 2.0から得られる確率に、KenLMで構築した外部言語モデルの確率を対数次元で重み付き(音響モデル:言語モデル=4:1)で足し合わせる形で推論しています。また、図中の"xlsr"や"xls-r"は多言語の事前学習済みモデルを指しており、YOLOデータをFine-tuningしたモデルとなっています。
評価結果としては、OpenAI Whisperよりもxls-rを元にした25.5hのデータセットで構築したwav2vec 2.0のFine-tuningモデルの方がよりよい性能となりました。
ではWhisperをFine-tuningしたらどうなるのでしょうか。
実験 ~自社データでFine-Tuning~
データセットは自社データの25.5時間分と141時間分の2つを使い、データ量に応じた性能比較を行います。
また、Whisperのsmall/medium/largeサイズで比較することによりパラメータサイズによる性能比較も行います。
以下のパラメータと設定でモデル構築を行いました。
HuggingFaceのパラメータ
per_device_train_batch_size=32
gradient_accumulation_steps=4
learning_rate=1.75e-4
weight_decay=0.01
warmup_ratio=0.1
gradient_checkpointing=True
fp16=True
group_by_length=False
per_device_eval_batch_size=16
predict_with_generate=True
generation_max_length=300Deep Speedのconfig
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"last_batch_iteration": -1,
"total_num_steps": "auto",
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto"
}実験結果
パラメータ・データセットの大きさによる違い

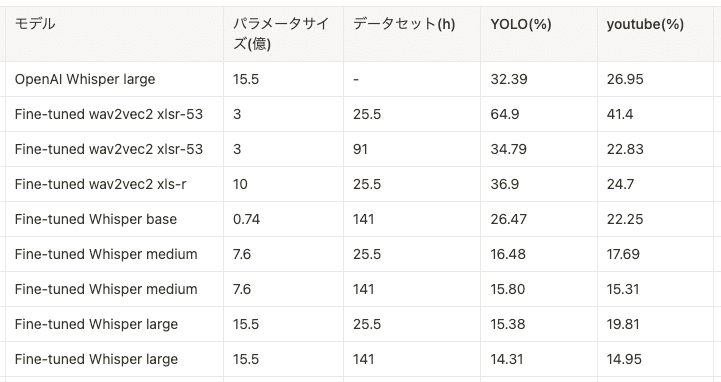
ここで、パラメータサイズ0.74がsmall、7.6がmedium、15.5がlargeのモデルとなっています。Fine-tuningすることでOpenAIのWhisperとwav2vec 2.0よりもいい性能となりました。さらに、パラメータとデータセットのサイズが大きくなるにつれて性能が上がっていくこともわかりました。
また、異なる評価データセット間で性能差が生まれていることもわかりました。OpenAI Whisper largeではYoutubeの方がYOLOよりCERが低い結果が出ていますが、Fine-tuningモデルは逆転しています。学習データのドメインと量が大事だということもこの結果から考えられます。
YOLO評価データセットに対する141hモデルの性能
141hのモデルの詳細な評価結果です。


政治がCER/WERが最も低く、社会や災害犯罪のCER/WERが最も高いことがわかります。学習データには社会が多く含まれていました。原因としては扱うテーマの幅広さが音声認識性能に影響しているのでしょうか。
いずれも今後深掘りしていければと思います。
従来の音声認識エンジンとの比較と今後の方向性
上記の結果から色々と考察はできますが、それまでYOLOで使っていた大手クラウドエンジンと比較してFine-tuned Whisper Largeモデルは相対的に37%ほど性能が向上したことがわかりました。そのため、141hのデータセットで構築したWhisper LargeモデルをYOLOにデプロイすることにしました。
リリースまで 〜Whisper Largeモデルのデプロイをどうするか問題〜
Whisper Largeモデルをどのようにデプロイをしていくか考えていく必要があります。
YOLOはAWSで構築しているため、選択肢としてはEC2やSagemakerなどが挙げられます。
結論から言えば、whisper.cppを使った、Pythonバインディングによるlambdaで推論をするエンドポイントを構築しました。その過程を説明します。
Sagemaker
以下のデシジョンツリーをもとにデプロイパターンを考えると、Async Inference(非同期推論)になります。

「もう悩まない!機械学習モデルのデプロイパターンと戦略」を解説する動画を公開しました! | Amazon Web Services
ちょうどWhisperで非同期推論を試しているブログがありました。素晴らしい記事なのでぜひ一読ください。
非同期推論はGPUが使える上、リクエストがない時にインスタンスを0にスケールダウンできるのでこの点もGoodです。
whisper.cpp
SageMakerでのデプロイを考えて実装に着手しようと思っておりましたが、大変優れたレポジトリが爆誕しました。そうです、whisper.cppです。CPUのみでWhisper largeモデルでも推論をすることができるとのことで話題になりました。
Githubで公開されているメモリ使用量はこのような感じです。

素晴らしいですね、このメモリ使用量ならAWS lambdaでも十分に載せられそうな予感がしてきました。
というわけで、早速HunggingFaceで構築したFine-tuningモデルをwhisper.cppで紹介されている通りに変換していきます。
以下のスクリプトを使うことで、whisper.cppで動作するモデルに変換することができます。
変換後のモデルで推論をしたところ、CPUでの推論時のメモリ使用量が2681MBとなりました。HuggingFaceでは7075MBであったことを考えると、だいぶメモリが削減されたことが分かります。
HuggingFace
CPUメモリ使用量: 7075.9MB
C++
CPUメモリ使用量: 2681.1MB
Pythonバインディングという選択肢
文字起こしサービス全体の運用・保守・監視も自分達で行なっているため、障害が起きた時に素早く対応できるか、担当者が変わった時もスキルトランスファーができるか、そこまで考えた上で実装しなくてはなりません。
whisper.cppを使ってC++によるエンドポイントを構築した時に、C++での運用経験がないことから、運用・保守が大変になることが想像できます。
そこで、C++の共有ライブラリを呼び出すことができるPythonの標準モジュールであるctypesを導入し、Pythonのエンドポイントとして実装することで、運用・保守のハードルを下げることにしました。
Pythonバインディングによるデメリットもあります。推論時間です。
Pythonバインディング
合計メモリ使用量: 2681.1MB
推論実行時間(10回試行の平均): 19.67s
C++
合計メモリ使用量: 2681.1MB
推論実行時間(10回試行の平均): 7.7s
※13秒の音声ファイルに対する推論時間の違い。サンプル数=1の簡易な実験であることに注意。
サンプル数が1の簡易実験ですが、このように推論時間がC++に比べて長くなることがデメリットとして挙げられます。
AWS lambda + Python
上述のように推論時間は遅くなりますが、推論に使用するメモリも2.6GBであるため、AWS lambdaで実装することができそうです。
最終的にWhisper LargeモデルをAWS lambdaで動かしているスクリプトは以下の通りとなりました。
def whisper_init():
class WhisperFullParams(ctypes.Structure):
_fields_ = [
("strategy", ctypes.c_int),
("n_threads", ctypes.c_int),
("n_max_text_ctx", ctypes.c_int),
("duration_ms", ctypes.c_int),
("translate", ctypes.c_bool),
("no_context", ctypes.c_bool),
("single_segment", ctypes.c_bool),
("print_special", ctypes.c_bool),
("print_progress", ctypes.c_bool),
("print_realtime", ctypes.c_bool),
("print_timestamps", ctypes.c_bool),
("token_timestamps", ctypes.c_bool),
("thold_pt", ctypes.c_float),
("thold_ptsum", ctypes.c_float),
("max_len", ctypes.c_int),
("max_tokens", ctypes.c_int),
("speed_up", ctypes.c_bool),
("audio_ctx", ctypes.c_int),
("prompt_tokens", ctypes.c_int * 16),
("prompt_n_tokens", ctypes.c_int),
("beam_search", ctypes.c_int),
]
libname = os.path.join(os.path.dirname(__file__), "cpp/libwhisper.so")
whisper_model = os.path.join(os.path.dirname(__file__), "cpp/model.bin")
whisper = ctypes.CDLL(libname)
whisper.whisper_init.restype = ctypes.c_void_p
whisper.whisper_full_default_params.restype = WhisperFullParams
whisper.whisper_full_get_segment_text.restype = ctypes.c_char_p
ctx = whisper.whisper_init(whisper_model.encode("utf-8"))
params = whisper.whisper_full_default_params(0)
return whisper, ctx, params
def infer(wav_file: str) -> str:
whisper, ctx, params = whisper_init()
try:
wav_array = _preprocess(wav_file, retry)
_ = _predict(wav_array, whisper, ctx, params)
n_segments = whisper.whisper_full_n_segments(ctypes.c_void_p(ctx))
txt = "".join(
[
whisper.whisper_full_get_segment_text(ctypes.c_void_p(ctx), i).decode(
"utf-8", errors="replace"
)
for i in range(n_segments)
]
)
whisper.whisper_free(ctypes.c_void_p(ctx))
return txt
except Exception:
raise
def _preprocess(wav_file: str) -> np.ndarray:
speech_array, sampling_rate = torchaudio.load(wav_file)
resampler = torchaudio.transforms.Resample(sampling_rate, 16000)
speech_array = resampler(speech_array)
return speech_array[0].detach().numpy()
def _predict(wav_array, whisper, ctx, params):
try:
result = whisper.whisper_full(
ctypes.c_void_p(ctx),
params,
wav_array.ctypes.data_as(ctypes.POINTER(ctypes.c_float)),
len(wav_array),
)
if result != 0:
exit(1)
return result
except Exception:
whisper.whisper_free(ctypes.c_void_p(ctx))
raise Exception("predict Error")
infer("path/to/wav_file")Whisperモデルを推論の度にロードするような実装となっていますが、理由は連続で推論を行うと、メモリリークが起きてしまうことへの対策です。
毎度モデルをロードせずとも、推論ができるように改修していければと思います。
(もし詳しい人がいればコメントいただけると嬉しいです)
リリースまで 〜推論速度と精度のトレードオフに関して〜
ここまでで、Whisper LargeモデルをPythonバインディングでかつLambdaで動くようになりました。
ここからは、WhisperFullParamsのdecode時のパラメータを、推論速度と音声認識精度の二つの観点から調整していきます。
Optunaと多目的最適化
推論速度をより早く、かつ精度を落とさず提供するために、推論速度と音声認識精度の多目的最適化問題と捉えて、その2つのパレートフロントを求めるよう、Optunaを使って計算していきます。
多目的最適化問題に関しては以下の記事が読みやすかったです。
ここで、音声認識精度に関係がありそうなパラメータは以下の2つに絞りました。
no_speech_thold
temperature
一方で速度に関係のありそうなパラメータは以下の2つに絞りました。
speed_up
n_threads
なお、beam_searchが最も性能に寄与しそうですが、whisper.cppでは当時beam_searchが実装されていなかったため、パラメータには含んでいません。
これらのパラメータを変化させながら、処理時間とCERのパレートフロントを求めていきます。
なお、Optunaではこのように得られた解の可視化もできたりするのでとても便利です。

参考までにOptunaを使った多目的最適化のコードを以下に載せておきます。
def objective(trial):
n_threads = trial.suggest_int("n_threads", 1, 10)
speed_up = trial.suggest_categorical("speed_up", [True, False])
beam_search_beam_size = trial.suggest_int("beam_search_beam_size", 0, 10)
temperature = trial.suggest_float("temperature", 0.0, 3.0)
no_speech_thold = trial.suggest_float("no_speech_thold", 0.0, 1.0)
asr_predictions = []
asr_references = []
processing_time = []
for wav_file, text in dataset:
start_time = time.time()
asr_result = infer(
wav_file=wav_file,
n_threads=n_threads,
speed_up=speed_up,
beam_search_beam_size=beam_search_beam_size,
temperature=temperature,
no_speech_thold=no_speech_thold
)
asr_predictions.append(asr_result)
asr_references.append(text)
end_time = time.time() - start_time
processing_time.append(end_time)
cer_score = cer.compute(predictions=asr_predictions, references=asr_references)
return cer_score, statistics.mean(processing_time)
study = optuna.multi_objective.create_study(directions=["minimize", "minimize"],
sampler=optuna.multi_objective.samplers.NSGAIIMultiObjectiveSampler())
study.optimize(objective, n_trials=100)パレートフロント
最終的に以下のパラメータを獲得することができました。

結果を眺めていると一点疑問が発生します。temperature高すぎ…?音声認識にtemperatureってこんなに必要なの…?
temperatureはいっても0.3ぐらいかと思っていましたが、なぜ今回の実験結果ではこのようにtemperatureが高くなってしまったのでしょうか。実際の出力文を見てみます。
temperature高すぎ問題の正体
多目的最適化実験でCERが高かったものを見てみます。すると、またもやrepetitionが起こっていたことがわかりました。
おうちのスタッフも一緒にはいはいはいはいかあるいはうちのスタッフの方がええええあの学校の紹介ってえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえーえー
やばいですね。そこでtemperatureを変えて出力がどう変わるのか確認してみました。


temperatureを高くするとrepetitionがなくなることがわかります。こちらは以下のURLでも解説されています。
Optunaで最適化する際に、repetetionにより高くなったCERに引っ張られてtemperatureが低くなってしまったことが考えられます。
そこでtemperatureの値によってどのように性能が変わるのか、実験してみました。
temperatureの値を変えた時の性能検証
ここでは、whisper.cppではなくHuggingFaceで実験を進めていきます。理由としては、HuggingFaceの推論時に設定することができる、no_repeat_ngram_sizeやbeam_searchにより、repetetionする可能性を減らすことができると考えたからです。ここでは、純粋にtemperatureとCERの関係についてみていければと思います。
YOLO評価データセットに対して以下の条件で実験しました。
Whisper Large Fine-Tunedモデル
GPUで推論
num_beams: 1
do_sample: True
no_repeat_ngram_size: 10
temperature: [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 2.0]
num_beams: 1
do_sample: False
no_repeat_ngram_size: 10
temperature: 0.0実験結果は以下の通りです。

x軸はtemperature、y軸CER(%)を示しています。
グラフから分かる通り、temperatureの値が大きくなるほど、CERの値が向上しています。なお、このグラフには載せていませんが、temperatureが2.0の時はCERが100%ほどになっていました。
また、各temperatureごとの推論時間を計測したところ、temperatureに応じて推論時間が変化するような傾向は見られませんでした。
以上の結果から、temperatureは0.0が最適な値であることがわかりました。
リリースまで 〜音声ファイルの分割方法 〜
再生時間が長いファイルは音声認識結果に悪影響を及ぼす可能性があるため、適切な長さに分割するような前処理を行います。どのような分割方法がいいのか、今回簡易な実験を行ったのでその結果を共有します。
分割方法の検討
時間でぶつ切りにする方法と音声区間検出、英語ではVAD(Voice Activity Detection)をもとに分割する方法の2つが考えられます。
VADは、pyannoteのvoice-activity-detectionを使用しました。なお、VADの結果をそのまま適用すると、とても短い区間で区切られた音声ファイルが大量に生成されてしまうため、最大30秒を超さないように、かつより多くの要素を考慮するような区間スケジューリング問題的な観点で、VADの結果を後処理しました。
※ ex. 後処理前:[(10,12), (12,25), (25,32), (32,50),(50,82)]、後処理後:[(10,32), (32,50), (50,80),(80,82)]
実験結果 ~ ぶつ切りのみ ~
まずはサンプル2つのみでぶつ切りで実験してみました。分割後の音声を音声認識したのちに、それらをまとめあげ、人手でつけたラベルとのCERを計算します。

これらの結果から25s-30sで分割するのが最も性能が良くなりそうだということがなんとなくわかりました。
また30秒より長い音声ではTemperature fallbackが多く起こりました。こちらのブログでも言及されています。
実験結果 ~ ぶつ切り vs VAD ~
続いて、25s、30s、VADの性能比較結果はこちらです。

30s > vad = 25sという結果になりました。
というわけで30sでぶつ切りする方法が一番性能がいい結果になりました。
まとめ
サンプル数が少ない簡易な実験ですが、30秒のぶつ切りが最も性能が良い結果が出ました。直感的に、無音区間(=話の途切れ目)で分割した方が性能はいいのかなと思っていましたが、それに反する結果が出て驚いています。サンプル数を多くしたり、VADではなく話者が変わったタイミングで分割するなどの実験を今後はしていければと思います。
また、現状我々が保持している学習データや評価データセットの平均再生時間は10秒未満である一方で、実際は30秒の音声が入力されることになります。その違いによって性能劣化が起きていないか、今後30秒の評価データセットを作っていく必要が出てきました。
リリース
以上のような結果を踏まえ、AWSで音声認識パイプラインを構築しました。
音声認識パイプラインの開発に関してはAWS Dev Day 2023に応募したものの落選してしまったので、どこかのタイミングでまとめていけたらと思います。
運用・保守・監視
リリース後、特に障害は起こっておらず安定稼働しています。
ホッとしています。
使用状況
認識・処理速度の性能が向上したからか、アップロードされたファイルの総再生時間は158%、ファイル数は165%(いずれも前月比)と大幅に増えました。
機械学習を使ったサービスにおける性能・処理速度の向上はやはり正義みたいです。
料金
これまで大手クラウドエンジンを使っていましたが、自社モデルで運用することで、音声ファイル1時間あたりにかかる料金が、1.66ドル/時間から1.03ドル/時間に削減されました。
推論時間
Stepfunctionsでlambdaを並列実行することで、一度に大量の文字起こしを行うパイプラインを構築しました。従来(EC2)と比較して87%の処理時間削減を実現することができました。
まとめ
いかがでしたでしょうか。データを収集し、データセットを作成、音声認識エンジンを構築してユーザーに届けるまでなかなか長い道のりでしたが、一通り経験することができて個人的には達成感を味わうことができました。
これがスタートラインだと思って、継続的に性能向上をしていけたらと思います。
今後ともM研をYOLOしくお願いします。
(メディア研究開発センター・山野陽祐)