
LLMは本当になんでも得意なの?TSUNAの文字数コントロールを検証

朝日新聞社メディア研究開発センター 田森です。
ゴールデンウィークがいよいよ始まりますね。メディア研究開発センターも4月には新年度を迎えワチャワチャしていましたが、月末になりようやく落ち着きを見せてきました。
ようやく、ようやく、要約。ということで、今回のテックブログは自然言語処理における要約タスクとLLMの最近について書いてみたいと思います。このブログは、NLP2024のワークショップ「生成AI時代の自然言語処理における産学官の役割と課題」で発表するにあたり、調査した内容について書いています。
このワークショップでは、LLMの特定のタスクに対する影響について「産」の立場から報告する場をいただきまして、今回は「要約タスク」における影響について報告しました。
なお、実験にあたっては以前、弊社・田口が発表した「ChatGPTを活用した見出し作成支援の検証」にならい、利用するモデルを変えて再実験をしたものです。
自動要約生成API「TSUNA」
弊社はLLM時代の前、2020年春から自動要約生成API「TSUNA」を公開・販売してきました。自動要約生成に関する研究は2017年ころから始め、3年をかけて公開に至りました。社内や社外からも反響があり、数社には有償でご利用いただいておりました。
TSUNAの大きな特徴の一つに出力の文字数をコントロールできることがあげられます。これはメディアにとっては非常に重要な要素です。例えば朝日新聞デジタルにおいては見出しは32文字が上限となっています。いろいろな観点において、見出しには過不足なく情報を載せておくのが重要で、おのずと32文字ギリギリまで文字を詰め込むことになり、「32文字ピッタリで」というコントロールができなければAIで自動で見出しが付けられる!としても役には立ちません。他のメディアでも同じような制限があり、我々としてはこの出力文字数のコントロールができることを「メディアならではの差別化ポイント」として研究を進めてきました。

TSUNAの現在位置
社内においては開発当初から現在に至るまで引き続き活用がなされています。現在では、電光掲示板配信用のニュース要約作業に利用されたり、ショート動画の作成に利用されています。

YouTubeにおける朝日新聞デジタルのショート動画「NEWS 1minute」
一方で、社外に目を移すと、LLM、特にChatGPTの発表後は問い合わせが徐々に減っているのが現実です。LLMが原因、ということだけではないとは思いますが、2023年は問い合わせが非常に少なかったのは事実です。「ChatGPTでできるようになったから」という明確な理由で解約されるお客様もおられました。
現状は、自動要約生成のR&Dは進めていますが、大々的に販売していこう、というよりは、社内およびメディア向けに焦点をあて性能向上を目指しています。やはりTSUNAの特徴である文字数コントロールは引き続き大事な要素である、という方向性も変わっておりません。
そんなにすごいの?
では、TSUNAの文字数コントロールってそんなにすごいの?あるいはLLMでもできちゃうんじゃないの?というところが疑問点としてあるかと思います。そこで、比較実験をしてみました。
実験設定(1) 評価対象のモデル
以下の5つのモデルに、2023年2月の100記事の本文を入力し、見出しを出力させて評価をしました。
TSUNA(過去の記事を数百万件学習させ、記事から要約を出力するseq2seqモデル)
gpt-35-turbo-16k (Azure OpenAI Service, Japan East Region)
gpt-4-32k (同上)
Claude-3 opus(Anthropic社製 Claude-3ファミリで一番パラメータサイズが大きいモデル)
OpenAI Fine-tuning機能によって gpt-3.5-turbo-0613をファインチューニングしたモデル
実験設定(2) 評価項目
ROUGE-1/2(正解=人間が作った見出しと出力との語彙のオーバーラップ率)
詳細はこちらに譲ります
長さコントロール(正解の見出しとの文字数の差)
APIとしての処理速度
出力の言語比率(LLMはたまに英語で答えたりするので念のため測定。日本語が多いほど良い)
実験設定(3) LLMの設定
LLMの設定は temperature=0.0 を設定した以外はデフォルト値としました。temperatureについてはこちらをご参照ください。
LLMに入力するプロンプトは
以下の記事を読んで、{文字数}文字の見出しを書いてください。
記事:
{記事}のようにし、 {文字数} には正解見出しの文字数を入れています。
OpenAI Fine-tuning機能では、2022年12月以前の700記事を学習データ、130記事を検証(Validation)データを利用して学習しました。記事データの量は、TSUNAの約1万分の1程度となります。また、学習データは下記のようなJSONフォーマットとしました。
{"messages": [{"role": "user", "content": "以下の記事を読んで、23文字の見出しを日本語で書いてください。\\n記事:\\n県ホームページ(HP)が2月1日から、5年ぶりに全面リニューアルされる。写真やイラストをふんだんに使い、栃木の魅力を動画で紹介。スマートフォンで見やすいページを新たに設け、大規模災害時に災害情報をきちんと届けられる工夫もとりいれる。\\n 新しい画面の上部には、県内を象徴する風景や建物の写真を掲載。各部署のフェイスブックやブログと連携して最新情報を届ける。大地震や豪雨などの災害時には、HPへのアクセスが集中して閲覧できない事態を防ぐため、トップページを災害情報に特化した文字だけの「軽量版」に切り替える。\\n 音声読み上げ機能とふりがな機能もあり、高齢者や障害者に配慮。「THIS IS 栃木」として県内の一押しの魅力を厳選し、写真だけでなく動画も充実させて発信する。\\n 広報課の担当者は「親しみやすい、分かりやすい、魅力が伝わる、の三つにこだわった。イベントや講座・講演なども検索しやすくなります」とPRする。(坂田達郎)"}, {"role": "assistant", "content": "栃木県HP、動画で魅力発信へ_あすリニューアル"}]}ちなみに、Fine-tuning中の損失はグラフ化されて見られます。便利ですね。なんか振動している感じがして嫌ですが、結果をみると正しく学習できているっぽいです。学習パラメータは自動設定に任せています。

結果発表〜!
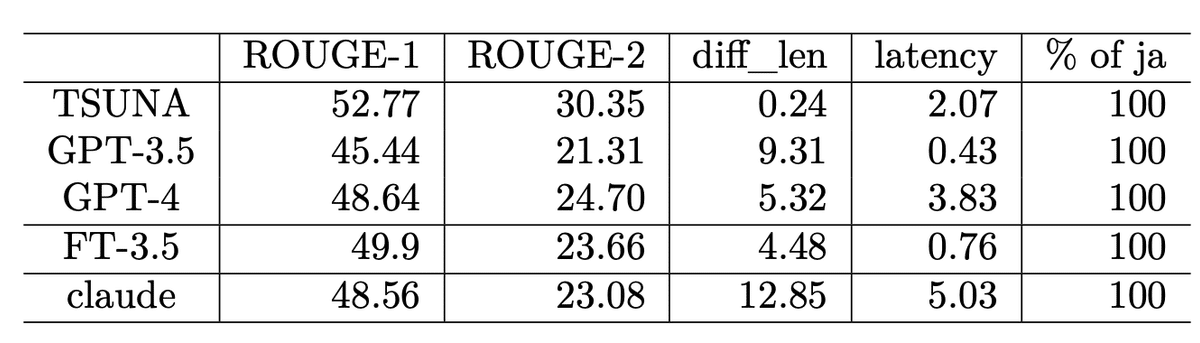
まず肝心の文字数コントロールの性能は「diff_len」で見ていきます。指示した文字数との差の絶対値を、テストデータ全体で平均をとったものです。0に近いほうが指示通りの文字数で出力しています。TSUNAは0に近く、限りなく差がなくコントロールができていることがわかります。LLMにおいては、GPT-3.5のファインチューニングモデルが最もいいですが、それでも4文字以上ずれてしまうことがわかります。
出力の良さを見る客観指標であるROUGE(高いほうが正解に近い)もTSUNAが最も高いですが、おしなべて高く、人間の目で見るとそこまで大きな差ではないと思います。
処理速度はlatencyの項目です。APIコールをしてから応答が返るまでの時間です。単位は秒で、小さいほどすぐに返事が返ってきます。GPT-3.5が現在は恐ろしく速いですね。また、Claudeは大人気のときに実験したので、現在ではもう少し速いかもですし、Claude-3ファミリの他のモデル(haikuとか?)だともっと速いと思います。
日本語比率はすべてのモデルで100%でした。以前の実験では数%は英語がまじりましたが、そのあたりは解決されているようです。
まとめ
LLMはzero-shotあるいはfew-shotで要約の生成が可能ですが、タスクを解決する性能としては事前学習済モデル+ファインチューニングのほうが良い、という結果で、論文[1]の報告にならうものでした。LLMは文字数コントロールは未熟ですが、生成の性能自体はどれも及第点と言えますし、もしかしたら人間による主観評価はLLMのほうがいいかもしれません。論文[2]でもそのような報告があります。それでもなお、TSUNAのROUGE値が最も高く、品質の高さを物語っています。
一方でLLMの良さもあります。プロンプトに「◯◯風に」と記載するとバリエーションに富んだ出力をしてくれたり、ものすごく長い入力でも要約をしてくれたりします。LLMの良さとファインチューニングモデルの良さを併用できる可能性もあります。
宣伝になってしまい恐縮ですが、文字数コントロールが必須な要約生成には是非、TSUNAをご検討ください。
(メディア研究開発センター 田森秀明)
参考文献
[1]C. Qun+2023, Is ChatGPT a General-Purpose Natural Language Processing Task Solver?
[2]T. Zhang+2023, Benchmarking Large Language Models for News Summarization