
初心者のための強化学習入門(実装編)

株式会社エリアルの太田です。
私は今年(2021年)の2月から機械学習の勉強を始めました。普段は大学院で機械学習とは縁のない研究をしているので、機械学習初心者です!
今回は機械学習の中でこれから伸びてくるであろう技術として強化学習について学びましたので記事にしていきたいと思います。私も初心者ですので、初心者の方がレベルアップできるような記事を目指したいと思います。
本記事について
強化学習のシミュレーション環境「OpenAIGym」で公開されているプログラムをローカル環境で実装しました。自分の勉強を兼ねてコードについて読み解いた内容をまとめました。自分の勉強用でもあるので、不要かなと思うところも積極的に書いています。
そもそも強化学習とは何かということについてはこちらのページで解説していますので、参考にしていただければと思います。
今回のPC環境は、Macbook Air(M1, 2020)、macOS Big Sur 11.6です。また実装対象は「OpenAIGym」の中から、CartPole v0を選んでいます。棒(Pole)がくっついた車(Cart)が左右に動くことでバランスを取って棒を倒さないように学習させることが目標です。
それでは始めましょう。
環境構築
まずは本記事で実装するOpemAIGymを実行するための環境構築です。
最初に以下のリンクに従ってKerasをインストールしましょう。
私の場合途中で、以下のエラーが出たのですがその解決策もリンクのページに書いてあり、説明通り実行することで解決できました。
ERROR: Command errored out with exit status 1 : ...うまく実行できたと思ったらリンクの最後にも明示されていますが、以下のコードで環境の状態を確認してみましょう。似たような出力が出たら成功です。
#environment test
# What version of Python do you have?
import sys
import tensorflow.keras
import pandas as pd
import sklearn as sk
import tensorflow as tf
print(f"Tensor Flow Version: {tf.__version__}")
print(f"Keras Version: {tensorflow.keras.__version__}")
print()
print(f"Python {sys.version}")
print(f"Pandas {pd.__version__}")
print(f"Scikit-Learn {sk.__version__}")
gpu = len(tf.config.list_physical_devices('GPU'))>0
print("GPU is", "available" if gpu else "NOT AVAILABLE")
出力:
Init Plugin
Init Graph Optimizer
Init Kernel
Tensor Flow Version: 2.5.0
Keras Version: 2.5.0
Python 3.9.7 | packaged by conda-forge | (default, Sep 2 2021, 17:55:16)
[Clang 11.1.0 ]
Pandas 1.3.2
Scikit-Learn 0.24.2
GPU is available続いて、keras-rl2というライブラリのコードを引っ張ってきましょう。
git clone https://github.com/wau/keras-rl2.gitkeras-rl2があるので当然keras-rlもあるのですが、そちらでは色々とエラーが出てうまくいきませんでした。なので必ずkeras-rl2の方を使うようにして下さい!
最後に不足しているライブラリがあるのでインストールして下さい。(GitHubに書いてくれればいいのに…)
conda install pyglet以上で環境ができました!
その状態で本記事で読み解いていくコード、examplesファイル内に入っているdqn_cartpole.pyを実行してみましょう。リンクに従ってJupyter Notebookを使用している場合はipynbファイル内で以下のコードを実行しましょう。
%run examples/dqn_cartpole.py以下のように、CartPoleが動く動画が表示されたら成功です!
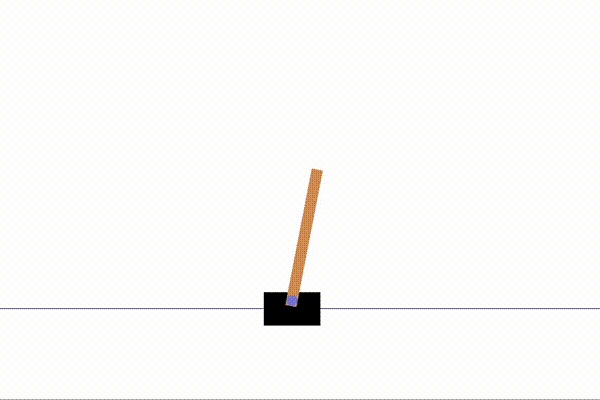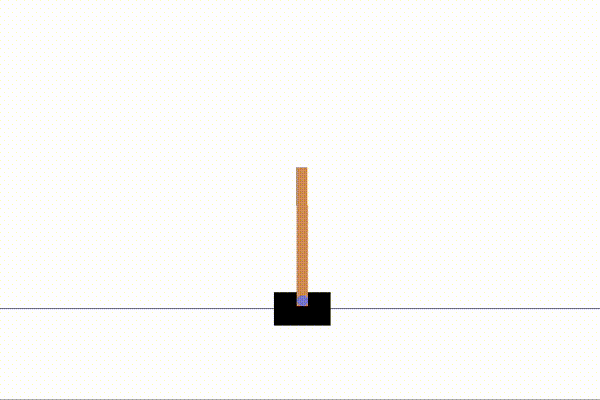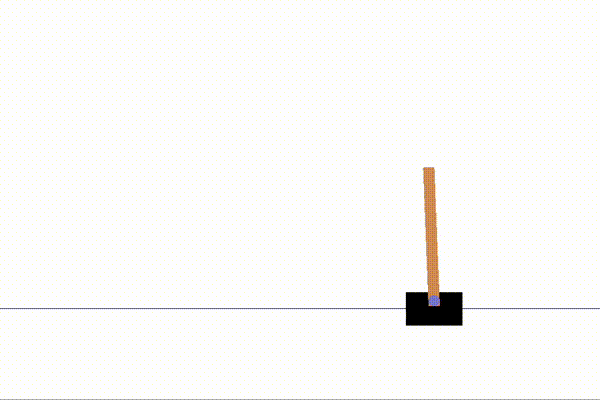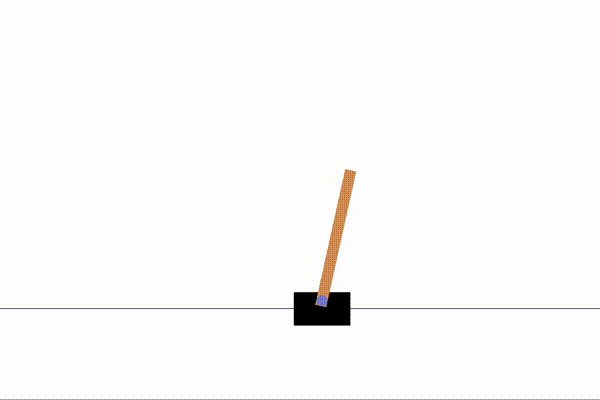
それでは実際のコードを読み解いていきましょう。
ライブラリの準備
まずは必要なライブラリを準備します。
import numpy as np
import gym
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation, Flatten
from tensorflow.keras.optimizers import Adamtensorflow.kerasと書くことで、tensorflow内のkerasを使用しています。私の場合、tensorflowとkerasのバージョンの違いによるエラーでしばらく手間取ったのですが、このように書いてしまえば問題ないと学びました。
続いてkeras-rl2で引っ張ってきたコードの中から、強化学習に必要なプログラムを収納したrlファイルから、強化学習で動く主体であるエージェント、エージェントが意思決定に使う戦略、情報を格納するメモリーを読み込んでいます。
from rl.agents.dqn import DQNAgent
from rl.policy import BoltzmannQPolicy
from rl.memory import SequentialMemory以上でライブラリの準備が整いました。
環境の取得と行動数の読み込み
次は環境の取得と行動数の読み込みです。
ENV_NAME = 'CartPole-v0'
# Get the environment and extract the number of actions.
env = gym.make(ENV_NAME)
np.random.seed(123)
env.seed(123)
nb_actions = env.action_space.ngym(OpenAI Gym)を使うことで'Cartpole-v0'用の環境を勝手に用意してくれます。超便利ですね!環境の情報はこちらにありました。
乱数発生の条件を固定させた後、行動数を環境から取得しています。実際、nb_actionsを出力させてみると2という整数値が出力されます。これは右に進もうとするか左に進もうとするかの2つの行動のことを表しています。
print(nb_actions)
出力:2Kerasを用いたDNNの構築
次にKerasを用いて深層ニューラルネットワーク(DNN)を構築しています。DNNの詳しい説明はここでは割愛しますが、エージェントであるCartPoleが取る行動を決めるための脳みそ部分です。入力にはCartPoleの状態、出力にはCartPoleが取る行動を決めるための各行動の価値が対応します。このDNNで入力にかける値(パラメーター)をどうするかによってCartPoleの行動が変わります。
# Next, we build a very simple model.
model = Sequential()
model.add(Flatten(input_shape=(1,) + env.observation_space.shape))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(nb_actions))
model.add(Activation('linear'))
print(model.summary())
出力:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 4) 0
_________________________________________________________________
dense (Dense) (None, 16) 80
_________________________________________________________________
activation (Activation) (None, 16) 0
_________________________________________________________________
dense_1 (Dense) (None, 16) 272
_________________________________________________________________
activation_1 (Activation) (None, 16) 0
_________________________________________________________________
dense_2 (Dense) (None, 16) 272
_________________________________________________________________
activation_2 (Activation) (None, 16) 0
_________________________________________________________________
dense_3 (Dense) (None, 2) 34
_________________________________________________________________
activation_3 (Activation) (None, 2) 0
=================================================================
Total params: 658
Trainable params: 658
Non-trainable params: 0
_________________________________________________________________
NoneDNNの構造自体はとてもシンプルで、入力を1次元化した後(Flatten)、全結合層(Dense、行列の掛け算)と活性化関数(Activation、今回はReLu関数)による処理を3回重ねています。最後にそれぞれの行動に対応する価値を出力にしています。printで表示させたモデルの情報を見ると確かに出力が2になっていて行動数の次元と一致しています。
入力の4は車の位置、車の速度、棒の角度、棒の先端速度の4つの情報に対応しています(こちらのObservation参照)。この4つの情報で定義されたCartPoleの状態に対して右、左それぞれの行動価値を算出して、どちらに進む方がより棒を倒さないようにできるか判断するということですね。
強化学習の骨子となる要素の定義
続いて強化学習の骨子となる要素を定義しています。
# Finally, we configure and compile our agent. You can use every built-in tensorflow.keras optimizer and
# even the metrics!
memory = SequentialMemory(limit=50000, window_length=1)
policy = BoltzmannQPolicy()
dqn = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=10,
target_model_update=1e-2, policy=policy)
dqn.compile(Adam(learning_rate=1e-3), metrics=['mae'])まず情報を格納するメモリーを定義しています。
memory = SequentialMemory(limit=50000, window_length=1)情報の格納や引き出しは以下のコードで行われていました。
rl>agents>dqn.py>class DQNAgent>def forward
state = self.memory.get_recent_state(observation)rl>agents>dqn.py>class DQNAgent>def backward
self.memory.append(self.recent_observation, self.recent_action, reward, terminal,
training=self.training)次のpolicyは文字通り戦略のことです。
policy = BoltzmannQPolicy()戦略の情報があるpolicy.pyには様々な戦略がコーディングされていますが、その中で今回はBoltsmannQPolicyを使っています。
class BoltzmannQPolicy(Policy):
"""Implement the Boltzmann Q Policy
Boltzmann Q Policy builds a probability law on q values and returns
an action selected randomly according to this law.
"""
def __init__(self, tau=1., clip=(-500., 500.)):
super().__init__()
self.tau = tau
self.clip = clip
def select_action(self, q_values):
"""Return the selected action
# Arguments
q_values (np.ndarray): List of the estimations of Q for each action
# Returns
Selection action
"""
assert q_values.ndim == 1
q_values = q_values.astype('float64')
nb_actions = q_values.shape[0]
exp_values = np.exp(np.clip(q_values / self.tau, self.clip[0], self.clip[1]))
probs = exp_values / np.sum(exp_values)
action = np.random.choice(range(nb_actions), p=probs)
return actionselect_action関数に行動決定のアルゴリズムが書かれています。qvalueというのがDNNで出力されるそれぞれの行動の価値のことで、それを指数関数で変換した値から行動の確率分布を算出し、その確率を元に行動を選んでいます。価値が高いほど確率が高くなってその行動を取りやすくなります。
※qvalueという名前はQ学習と呼ばれている強化学習の代表的な方法から来ていますが、Q学習は最大価値のを持つ行動を必ず選ぶことが特徴なので今回は当てはまりません。
そしてdqnには強化学習全体の情報を入れています。
dqn = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=10,
target_model_update=1e-2, policy=policy)引数の意味は次の通りです。
model:事前に構築したDNN。DNNは状態を入力にして行動価値を出力します。
nb_actions:行動の数。すなわち今回は右か左の2つなので2が入ります。
memory:状態や取った行動、その時の報酬といった情報の保存を行う格納庫です。直前のコードで定義しました。
nb_steps_warmup:メモリーに情報を記録し始める最低「ステップ」数。
target_model_update:パラメーターの更新割合を表す数値。学習率。
policy:戦略。直前のコードで定義しました。
わかりにくいところを補足します。
nb_steps_warmupはメモリーに情報を記録し始める最低「ステップ」数を表しています。これは僕の考えですが、ある程度の学習が進んだところから情報を記録し始めることで、学習が進んでいない時点で発生する不安定な要素が減り、局所最小値に落ち込んで変な挙動を起こすことを防げるのではないでしょうか。
target_model_updateはDNNのパラメーターの更新割合を示しています。パラメーターの更新箇所について以下の但し書きがありました。
rl>agents>dqn.py>Class AbstractDQNAgent
# Soft update with `(1 - target_model_update) * old + target_model_update * new`.この式からtarget_model_updateが、新しく得られたパラメーターをパラメーターの更新にどの程度反映させるかを表した数値であることがわかります。target_model_updateは強化学習の用語でいうと学習率です。ちなみに、target_model_updateが1を超えていた場合、keras.modelに実装された関数を使って完全に置き換えるようになっています。
最後は最適化アルゴリズムとモデルの精度の高さを判定する指標を指定しています。
dqn.compile(Adam(learning_rate=1e-3), metrics=['mae'])Adamは最適化アルゴリズムの一つで、AdaGradとMomentumという2つのアルゴリズムの融合バージョンです。 metrics=['mae']というのはモデルの精度の高さを判定する指標、精度指標(Metrics)として平均絶対誤差(MAE)を指定するという意味です。ここでは説明を参考ページに譲りたいと思います。
↑Adam含めた最適化アルゴリズムについて
↑MAE含めた精度指標について
いよいよ学習!
さてここまでで事前準備の設定は完了しまして、いよいよ学習です。実行するとエピソードごとの結果が順に出力されるようになっています。
# Okay, now it's time to learn something! We visualize the training here for show, but this
# slows down training quite a lot. You can always safely abort the training prematurely using
# Ctrl + C.
dqn.fit(env, nb_steps=10000, visualize=True, verbose=2)
出力例:
30/10000: episode: 1, duration: 1.246s, episode steps: 30, steps per second: 24,
episode reward: 30.000, mean reward: 1.000 [ 1.000, 1.000], mean action: 0.467 [0.000, 1.000],
loss: 0.485434, mae: 0.538129, mean_q: 0.214934dqn.fit()となっていますが、DNNのパラメーターをフィッティングにより最適化していくといった意味が込められた名付け方だと思います。
ここで少しややこしかったのが、ステップとエピソードの違いでしたので、書いておきます。
ステップ:その時の状態を取得して、行動を決定し、その結果を保存する一連の行為を含む。 1ステップでは取る行動は一回だけ。
エピソード:複数のステップが集まったもので、ある終了条件を満たすと次のエピソードに進む。
エピソードの終了条件はOpenAIGymで元々規定されており、3種類ありました。(こちらのEpisode Termination参照)以下のいずれかが満たされると次のエピソードに移るようになっています。
エピソード終了の条件
1:棒の 角度が±12°を超える
2:車の位置が規定の画面外に出る
3:ステップ数が200を超える
学習結果の保存
学習後は学習結果のDNNのパラメーターを保存します。
# After training is done, we save the final weights.
dqn.save_weights(f'dqn_{ENV_NAME}_weights.h5f', overwrite=True)最終テスト
最後に学習結果のDNNのパラメーターを使ってテストです。
# Finally, evaluate our algorithm for 5 episodes.
dqn.test(env, nb_episodes=5, visualize=True)
出力:
Testing for 5 episodes ...
Episode 1: reward: 195.000, steps: 195
Episode 2: reward: 180.000, steps: 180
Episode 3: reward: 182.000, steps: 182
Episode 4: reward: 186.000, steps: 186
Episode 5: reward: 169.000, steps: 169以下で10000ステップの学習を経たCartPoleの動きと学習前の動きを表示させました。
↑学習前
↑学習後
棒の安定感が一目瞭然です!ものすごい成長ですね!一生懸命棒を倒さないようにしている姿がなんとも愛らしいです。笑
まとめ
今回はOpenAIGymの公開環境CartPole v0を利用したプログラムを実装をして、そのコードの意味を読み解きました。機械学習は理論と実装両面から勉強してみることで、理解が深まっていきますね。
また機会があれば、何かしらの実装に挑戦してみたいと思います。
参考文献
Keras環境構築:https://morioh.com/p/9229d2aa655b
使用したソースコード:https://github.com/muoncollider/keras-rl2
OpenAIGymの解説記事:https://qiita.com/ishizakiiii/items/75bc2176a1e0b65bdd16
CartPole v0の環境情報:https://github.com/openai/gym/wiki/CartPole-v0
最適化アルゴリズムについて:https://tech-lab.sios.jp/archives/21823
精度指標について:https://atmarkit.itmedia.co.jp/ait/articles/2008/17/news031.html