
AIを作るまでに何をすれば良いの?

全体の流れ
こちらの海外記事によると、データサイエンスを行う工程は以下。
・データの収集
・ビッグデータの処理
・ビジネスインテリジェンス(BI)の解析
・統計分析・機械学習
特に機械学習はAIに密接に関わっているので、単語だけは聞いたことがあるのではないでしょうか?
主に、AIを作るのに強く関わる部分は「データ収集」、「統計分析・機械学習」となります。今回は、この部分に着目して解説していきたいと思います
①データ収集
昨今のAIは機械学習と呼ばれるアルゴリズムを使うのが主流です。
最近よくニュースになるディープラーニングも機械学習の一種です。
そして機械学習には必ずデータが必要となります(理由は後述)
データを集める方法としては、以下が挙げられます。
・ webページやweb APIをスクレイピングする
・アプリを通してユーザ行動のログを集める
・ データを購入する
特にサービスを運営している方々でAIを取り入れることも想定している場合は、できるだけ幅広くデータを集めましょう
例えばユーザー行動ログからユーザ情報を取っていて、「これいらないな」と思っているデータでも実はAIにとっては重要な情報かもしれません。
集めるのも時間が必要ですので、取り逃がした場合は手戻りのコストが非常に高いです。ユーザー行動ならなおさら取り逃がしたら二度と取得出来ません。
②データをアノテーションをする
今使われている機械学習の主流なアルゴリズムは、教師あり学習と呼ばれています。
教師あり学習の方法ですが、要は小学生が算数のドリルの問題を何度も解くようにAIに正解までの計算方法を覚えさせるようなアルゴリズムです。
そのため、問題(データ)と答えが必要となり、データには正解となる情報を付け加える必要があります。この作業をアノテーションと呼びます。

アノテーションが何かと言うと、上のイメージ図のように、画像データなら画像データが何かをデータに与えることです。
例えば、犬と猫の画像を見分るAIを作りたいとなった場合、犬の画像には犬、猫の画像には猫と人手で正解をつける必要があります。
アノテーションの工程は質も量もこなす必要がありますので、アノテーション要員を外注したり雇ったりしてお願いする企業も多いです。
③AIにデータを学習させる
機械学習はアルゴリズムによって、与えられたデータを自動的に解析する手法となります。
例えば犬と猫の画像を機械学習で見分けたい場合を下図で説明します。
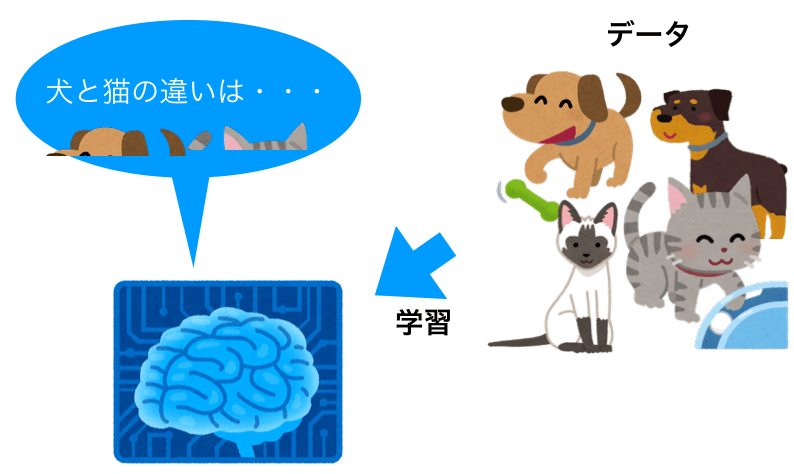
例えば、図の場合だと、与えたデータの内容によって「犬は耳が垂れている、猫が耳が立っている」というパターンが目立ちますね。
すると学習するAIは動物の耳に犬か猫を識別する要素の一つだと覚えます。
当然、柴犬のように耳が立っている犬もありえるので、現実的にありうるデータを可能な限り集める必要があります。
データを幅広く集めた方がいいというのは、AIの判断基準を柔軟にさせるためなのです。

また、データ品質も重要で、「犬」と「猫」を間違えてしまったデータが混在していた場合、AIが間違った学習をしてしまいます。
データは量が大事と言われますが、質も大事です。間違えてアノテーションしてしまったら後で探すのも大変です。
④AIの性能を評価する
AIの学習が終わった後も、本当に間違えが少ないかを定期的に評価・確認する必要があります。
よくあるケースとしては、学習したデータを正解率の良し悪しだけで判断することがあります。
しかし、本当にそれで大丈夫でしょうか?
機械学習の世界では、学習用データとテスト用データの2つに分けてAIを学習させます。
(厳密には、学習用・テスト用・検証用データで3つに分けるのが基本ですがここでは割愛)
名前の通り学習用データがAIの学習に使うデータで、テスト用データがAIが正しく予測出来るかを確認するためのデータとなります。

テストデータでの予測ができたら、どのような間違え方をするか確認して見ましょう。
例えば名刺管理アプリSanSanも機械学習ベースのAIを使っています。
しかし機械学習も完全ではないので人手でのチェックが入っています。
引用元:https://imitsu.jp/matome/business-card/2003520883811107
これによりAIはほとんど間違えないので作業も早いですし、万が一間違えても人がカバーしてくれます。
どれだけ予測できればいいか、あるいはどんな間違え方なら許せるかを事前に決めておくことをオススメします。
これからAIを作りたいあなたへのオススメ
以上が簡単な説明にはなりますが、データを集めるのもAIの学習も時間もお金もかかって大変なケースが多いです。
しかし、そのような問題が提起されているのもあって、最近は高性能ですぐ使えるAIが公開されていることが多いです
企業のAPIを使う
最近はGoogleの画像認識や自然言語処理のAPIが公開されていて、大抵の場合、データを集めたりAIの学習の過程が不必要になることが多いです
お値段が気にならないのであれば、まずはこのような企業が公開しているAPIで試してみるのをオススメします。
AutoMLを使う
それでも満足が行かない場合はAutoMLというAIがAIのアルゴリズムを開発するサービスがあります。
自分たちで集めたデータを与えると自動で高性能なAIアルゴリズムを開発して学習します。AIを作るエンジニアがいない場合でも効果的ですし、ひとまず試しに使ってみるという使い方もできます。
APIで至らない結果になった場合にオススメです。
またAutoMLはSaaSのサービスになっていることが多いです。
少し古い情報ですがこちらにAutoMLサービスがまとまっている記事があるので興味のある方は参考にすると良いと思います。
データを集めるならharBestがオススメ
ここまでAIを作るのが楽になっていることを説明しましたが、データの方はいかがでしょうか?
特に収集したデータのアノテーションは特に大変で、筆者の実体験として以下のような理由で、AIを作るのに苦労なさっている企業様も多く見られました。
・間違ったアノテーションをしていないか確認する必要がある
・アノテーション作業員のマネジメントをする必要がある
・アノテーションのために使いやすいツールを探すか作る必要がある
harBestは一番大変なデータの「アノテーションを解決するプロダクト・ソリューション」を提供します。
【会社情報】
株式会社APTO
Mail:info@apto.co.jp
HP:https://apto.co.jp/
この記事が気に入ったらサポートをしてみませんか?