『Aidemy-AIアプリコース』受講記:12日目(性能評価指標、7章添削問題、機械学習(分類)の基礎)

プログラミングスクール「Aidemy」を受講し、その体験記をコツコツ書いていこうと思います。
「Aidemy」の受講を検討している方、どんなことをするかイメージを持っていただければ幸いです。
自己紹介:
大卒。ITに関して無知識。
新卒で造船業:現場管理。転職を目指し「Aidemy」を受講。
7/30
<12日目>
<今日の学習内容>
7-3 : 性能評価指標(1h)
7章添削問題(0.5h)
8-1: 教師あり学習(分類)の基礎(2.5h)
<7-3 性能評価指標>
ここでは結果をどのように評価するのかについて学びました。
正解率(accuracy)、適合率(precision)、再現率(recall)、F値(F-value)というものがあります。
それぞれについて説明します。
・正解率
全体の中でどれだけ正しい判断ができているか
・適合率
予測がどれだけ合っているか
・再現率
どれだけ正しく予測できるか
・F値
適合率、再現率を組み合わせ、調和平均をとったもの
です。下の図を見てください。

この場合、正解率は55/100で55%です。
また適合率は、15/30 で50%、再現率は 15/45 33%
となります。イメージが難しいのですが、上の例で言うと買う前に買う買わないを予想するのが適合率、買った後に買う買わないを当てるのが再現率です。
そしてこの表自体を混合行列と言います。
また、縦軸を適合率、横軸を再現率としてグラフをかいたものをPR曲線と言います。
添削問題は空欄を埋めるもので学んだ言葉の意味を理解できているかを図るものでした。
この章では言葉や概念の説明でしたね!
<8-1: 機械学習(分類)の基礎>
ここでは機械学習(分類)の主な手法について学びました。
下記6つです。
・ロジスティック回帰
・線形svm
・非線形svm
・決定木
・ランダムフォレスト
・k-NN
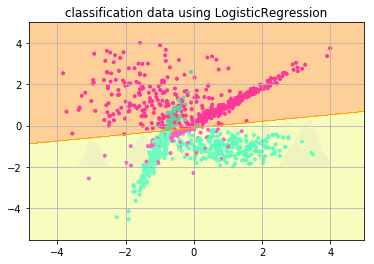
ロジスティック回帰は線形分離可能なデータの境界線を学習によって見つけてデータの分類を行なう手法です。
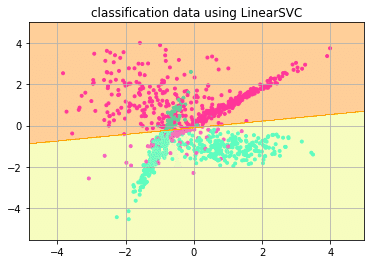
線形svmはロジスティック回帰と同じように線形分離可能なデータの境界線を学んで分類を行う方法ですが、サポートベクターと言う他の集合と距離の近いデータ群を基準にそれとの距離が一番大きくなる位置に境界線をひきます。
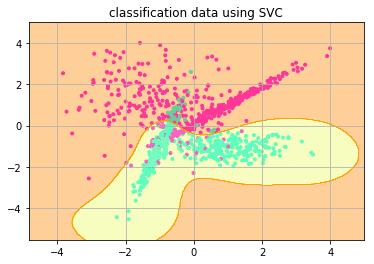
非線形svmは直線(線形)で分割できない時も使用できる線形svmの拡張版です。
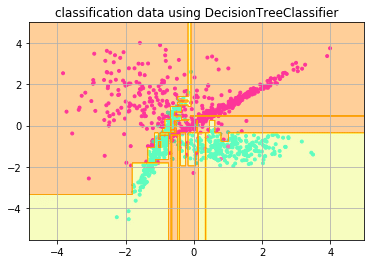
決定木はデータの要素(説明変数)の一つ一つに着目し、その要素内でのある値を境にデータを分割していくことでデータの属するクラスを決定しようとする手法です。
ランダムフォレストは決定木の簡易版です。決定木は一つ一つ全ての値を見ていきますが、ランダムフォレストでは値をランダムに選び見ていきます。
k-NNはk近傍法とも呼ばれ、予測をするデータと類似したデータをいくつか見つけ、多数決により分類結果を決める手法です。
非常にざっくりですが、こんなことを学びました。
その一つ一つにプログラムが合ったのですが、まとめ問題がよくまとまっていたので、まとめ問題を書きます。
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
X, y = make_classification(n_samples=1000, n_classes=2, n_features=2, n_redundant=0, random_state=42)
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2, random_state=42)
model_list = {'ロジスティック回帰': LogisticRegression(),
'線形SVM': LinearSVC(),
'非線形SVM': SVC(),
'決定木': DecisionTreeClassifier(),
'ランダムフォレスト': RandomForestClassifier(),
'k-NN': KNeighborsClassifier() }
model_title = ["classification data using LogisticRegression", "classification data using LinearSVC", "classification data using SVC", "classification data using DecisionTreeClassifier", "classification data using RandomForestClassifier", "classification data using KNeighborsClassifier"]
i = 0
for model_name, model in model_list.items():
model.fit(train_X,train_y)
print(model_name)
print('正解率: '+str(model.score(test_X, test_y)))
plt.scatter(X[:, 0], X[:, 1], c=y, marker=".",
cmap=matplotlib.cm.get_cmap(name="cool"), alpha=1.0)
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, 0.02),
np.arange(x2_min, x2_max, 0.02))
Z = model.predict(np.array([xx1.ravel(), xx2.ravel()]).T).reshape((xx1.shape))
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=matplotlib.cm.get_cmap(name="Wistia"))
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
plt.title(model_title[i])
plt.grid(True)
plt.show()
i += 1ロジスティック回帰
正解率: 0.88
線形SVM
正解率: 0.88
非線形SVM
正解率: 0.915
決定木
正解率: 0.925
ランダムフォレスト
正解率: 0.94
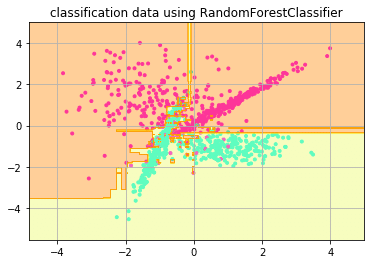
k-NN
正解率: 0.935
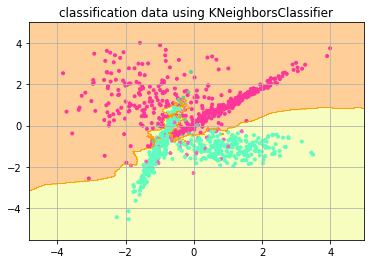
これがプログラム自身が学んで、未知数のデータに対して予測した結果だと思うとなんか不思議な気分ですね。
ライブラリによって簡単にモデルを作ることができ、詳しい中身は分かりませんが、機械学習をコンピューターにさせている実感はあり少し感動です。
今日はこんなところです。
また明日!
この記事が気に入ったらサポートをしてみませんか?