『Aidemy-AIアプリコース』受講記:20日目(CNNを用いた画像認識:応用、11章添削問題)

プログラミングスクール「Aidemy」を受講し、その体験記をコツコツ書いていこうと思います。
「Aidemy」の受講を検討している方、どんなことをするかイメージを持っていただければ幸いです。
自己紹介:
大卒。ITに関して無知識。
新卒で造船業:現場管理。転職を目指し「Aidemy」を受講。
8/7
<20日目>
<今日の学習内容>
11-2 : CNNを用いた画像認識の応用(2h)
11章添削問題
ここではデータのかさ増し、正規化、転移学習について学びました。
データのかさ増しは以前も行いました。
今回はKerasのImageDataGeneratorを使ってかさ増しを行いました。
import matplotlib.pyplot as plt
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
%matplotlib inline
# 画像データの読み込み
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# 画像の表示
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(X_train[i])
plt.suptitle('original', fontsize=12)
plt.show()
# 拡張する際の設定(自由に設定してください)
generator = ImageDataGenerator(
rotation_range=90, # ○°まで回転
width_shift_range=0.3, # 水平方向にランダムでシフト
height_shift_range=0.3, # 垂直方向にランダムでシフト
channel_shift_range=70.0, # 色調をランダム変更
shear_range=0.39, # 斜め方向(pi/8まで)に引っ張る
horizontal_flip=True, # 垂直方向にランダムで反転
vertical_flip=True # 水平方向にランダムで反転
)
extension = generator.flow(X_train,shuffle=False)
X_batch = extension.next()
X_batch *= 127.0 / max(abs(X_batch.min()), X_batch.max())
X_batch += 127.0
X_batch = X_batch.astype('uint8')
# 拡張した画像の表示
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(X_batch[i])
plt.suptitle('extension', fontsize=12)
plt.show()

こんな感じに1枚の画像をずらしたり回転させたりズームしたりしてかさ増しが行えます。
正規化には標準化と白色化があり、データを処理し使いやすくすることを言います。
import matplotlib.pyplot as plt
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(X_train[i])
plt.suptitle('base images', fontsize=12)
plt.show()
#標準化
datagen = ImageDataGenerator(samplewise_center=True, samplewise_std_normalization=True)
g = datagen.flow(X_train, y_train, shuffle=False)
X_batch, y_batch = g.next()
# 生成した画像を見やすくしています
X_batch *= 127.0 / max(abs(X_batch.min()), X_batch.max())
X_batch += 127.0
X_batch = X_batch.astype('uint8')
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(X_batch[i])
plt.suptitle('standardization results', fontsize=12)
plt.show()
#白色化
datagen = ImageDataGenerator(featurewise_center=True, zca_whitening=True)
datagen.fit(X_train)
g = datagen.flow(X_train, y_train, shuffle=False)
X_batch, y_batch = g.next()
X_batch *= 127.0 / max(abs(X_batch.min()), abs(X_batch.max()))
X_batch += 127
X_batch = X_batch.astype('uint8')
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(X_batch[i])
plt.suptitle('whitening results', fontsize=12)
plt.show()
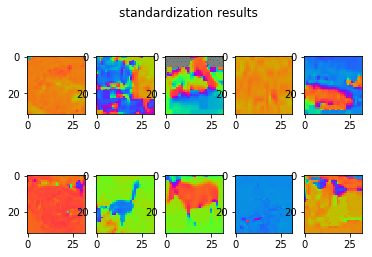
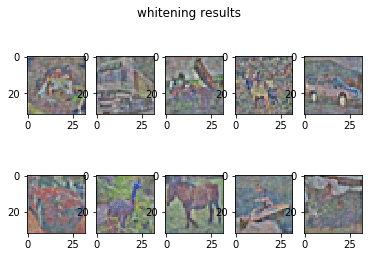
人間には見辛くなっていますが、パソコン的には標準化(2枚目)や白色化(3枚目)した方がみやすいのでしょうね!
転移学習とは公開されている学習済みモデルを用いて新たなモデルの学習を行うことです。
普通ではかなり厳しいようなデータ数でモデル構築が行われているため、最初から頭のいいものを使うことができます。
では添削問題です。
from keras import optimizers
from keras.applications.vgg16 import VGG16
from keras.datasets import cifar10
from keras.layers import Dense, Dropout, Flatten, Input
from keras.models import Model, Sequential
from keras.utils.np_utils import to_categorical
import matplotlib.pyplot as plt
import numpy as np
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
input_tensor = Input(shape=(32, 32, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='sigmoid'))
top_model.add(Dropout(0.5))
top_model.add(Dense(10, activation='softmax'))
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
for layer in model.layers[:15]:
layer.trainable = False
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
# model.load_weights('param_vgg_15.hdf5')
model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=32, epochs=3)
model.save_weights('param_vgg_15.hdf5')
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])転移学習を用いたモデルの作成でした。
今回も細かいところでなぜがいっぱいでしたが、ひとまず作ることはできました笑
こちらが解答例です。
from keras import optimizers
from keras.applications.vgg16 import VGG16
from keras.datasets import cifar10
from keras.layers import Dense, Dropout, Flatten, Input
from keras.models import Model, Sequential
from keras.utils.np_utils import to_categorical
import matplotlib.pyplot as plt
import numpy as np
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
X_train = X_train[:300]
X_test = X_test[:100]
y_train = to_categorical(y_train)[:300]
y_test = to_categorical(y_test)[:100]
input_tensor = Input(shape=(32, 32, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = vgg16.output
top_model = Flatten(input_shape=vgg16.output_shape[1:])(top_model)
top_model = Dense(256, activation='sigmoid')(top_model)
top_model = Dropout(0.5)(top_model)
top_model = Dense(10, activation='softmax')(top_model)
model = Model(inputs=vgg16.input, outputs=top_model)
for layer in model.layers[:15]:
layer.trainable = False
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
# model.load_weights('param_vgg_15.hdf5')
model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=32, epochs=3)
model.save_weights('param_vgg_15.hdf5')
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])書き方がちょっと違いますね。
これも使えるようにならねば!
それではまた!
この記事が気に入ったらサポートをしてみませんか?