『Aidemy-AIアプリコース』受講記:13日目(ハイパーパラメーターとチューニング1、2)

プログラミングスクール「Aidemy」を受講し、その体験記をコツコツ書いていこうと思います。
「Aidemy」の受講を検討している方、どんなことをするかイメージを持っていただければ幸いです。
自己紹介:
大卒。ITに関して無知識。
新卒で造船業:現場管理。転職を目指し「Aidemy」を受講。
7/31
<13日目>
<今日の学習内容>
8-2 : ハイパーパラメーターとチューニング1(1.5h)
8-3 : ハイパーパラメーターとチューニング2(1.5h)
機械学習のモデルがもつパラメーターにおいて、人が調整しないといけないパラメーターをハイパーパラメーターと言います。
今回はそれぞれのモデルにおけるハイパーパラメーターとそのチューニング方法を学びました。
・ロジスティック回帰、線形SVMのハイパーパラメーター
C、penalty、multi_class、random_stateの四つあります。
C : モデルが学習する識別境界線が教師データの分類間違いに対してどのくらい厳しくするのかという指標
penalty : モデルの複雑さに対するペナルティ
multi_class : 多クラス分類を行う際にモデルがどういった動作を行うかということを決めるパラメーター
random_state : データをランダムに処理していくのですが、その順番を制御するパラメーター
例えばCの値を変えることによってどのような違いが出てくるのかを示すプログラムが次の通りになります。
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.datasets import make_classification
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
%matplotlib inline
X, y = make_classification(
n_samples=1250, n_features=4, n_informative=2, n_redundant=2, random_state=42)
train_X, test_X, train_y, test_y = train_test_split(X, y, random_state=42)
C_list = [10 ** i for i in range(-5, 5)]
svm_train_accuracy = []
svm_test_accuracy = []
log_train_accuracy = []
log_test_accuracy = []
for C in C_list:
model1 = LinearSVC(C=C, random_state=42)
model1.fit(train_X, train_y)
svm_train_accuracy.append(model1.score(train_X, train_y))
svm_test_accuracy.append(model1.score(test_X, test_y))
model2 = LogisticRegression(C=C, random_state=42)
model2.fit(train_X, train_y)
log_train_accuracy.append(model2.score(train_X, train_y))
log_test_accuracy.append(model2.score(test_X, test_y))
fig = plt.figure()
plt.subplots_adjust(wspace=0.4, hspace=0.4)
ax = fig.add_subplot(1, 1, 1)
ax.grid(True)
ax.set_title("SVM")
ax.set_xlabel("C")
ax.set_ylabel("accuracy")
ax.semilogx(C_list, svm_train_accuracy, label="accuracy of train_data")
ax.semilogx(C_list, svm_test_accuracy, label="accuracy of test_data")
ax.legend()
ax.plot()
plt.show()
fig2 =plt.figure()
ax2 = fig2.add_subplot(1, 1, 1)
ax2.grid(True)
ax2.set_title("LogisticRegression")
ax2.set_xlabel("C")
ax2.set_ylabel("accuracy")
ax2.semilogx(C_list, log_train_accuracy, label="accuracy of train_data")
ax2.semilogx(C_list, log_test_accuracy, label="accuracy of test_data")
ax2.legend()
ax2.plot()
plt.show()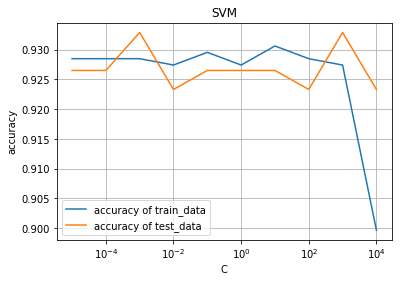
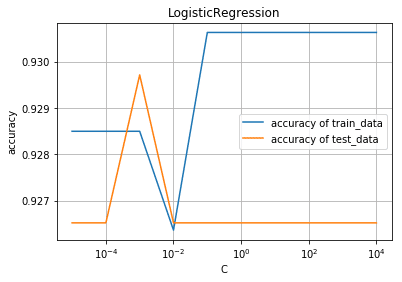
この二つのモデルのCは分類間違いの許容度を示すものです。
許容度を変えるとトレーニングデータの正解率、テストデータの正解率が変化しているのが見て取れると思います。
このような感じで各モデルに対するハイパーパラメーターとチューニング方法を8-2、8-3を通じて学びました。
8章添削問題に取り組んでいますが、めちゃめちゃ時間がかかりそう(現にかかっている笑)なので今回はここまでです。
それではまた明日!
この記事が気に入ったらサポートをしてみませんか?