タイタニック号生存者予測

はじめに
こんにちは!
今回はKaggleチュートリアルの「タイタニック号生存者予測」を行ってみました。
簡単にKaggleとは、機械学習・データサイエンスに関わる人のコミュニティーです。Kaggleの特徴の一つにコンペがあります。
様々なコンペがあるのですが、今回行うのはその中でもチュートリアルとして常設されているものになります。
Kaggleの始め方については下記URLの記事がわかりやすかったため、参考にしてください。
https://aizine.ai/kaggle-01-0905/
それでは、考えたことや、コード等説明します。
考え方
次のような流れで考えました。
1:データの確認
2:相関を調べる
3:データを整理する
4:モデルの選択
データは以下のようになっています。

それぞれが何を表しているかは次の通りです。
・PassengerID:乗船者のID
・Survived:0=死亡、1=生存
・Pclass:部屋のランク(1:高級、2:一般、3:安い)
・Name:名前
・ Sex: 性別
・Age: 年齢
・Sibsp: 一緒に乗船していた兄弟、配偶者の数(横のつながり)
・ Parch: 一緒に乗船していた親、子ども、孫の数(縦のつながり)
・Ticket: チケットの乗船番号
・ Fare: 乗船費用
・Cabin: 部屋番号
・Embarked: 出発した港の名前
C = Cherbourg, Q = Queenstown, S = Southampton
次に欠損値、データの重複についてみてみましょう。以下のコードで確認できます。
import pandas as pd
train_df = pd.read_csv("/kaggle/input/titanic/train.csv")
test_df = pd.read_csv("/kaggle/input/titanic/test.csv")
print(train_df.info())
print(test_df.info())
print(train_df.describe(include=["O"]))<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 332 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 417 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
None
Name Sex Ticket Cabin Embarked
count 891 891 891 204 889
unique 891 2 681 147 3
top Sage, Mr. Douglas Bullen male CA. 2343 G6 S
freq 1 577 7 4 644
訓練用には全部で891個のデータがあり、Age、Cabin、Embarkedに欠損があります。
テスト用ではAge、Fare、Cabinにあります。
そしてNameの部分、countとuniqueが等しいのでデータの被りがないことがわかります。
続いて、Pclass、Sex、Parch、SibSpとSurvivedの関係をみていきます。
例えばSexに関しては男性、女性と分けてSurvivedの平均を取っています。
これをそれぞれについて行いました。
import pandas as pd
train_df = pd.read_csv("/kaggle/input/titanic/train.csv")
test_df = pd.read_csv("/kaggle/input/titanic/test.csv")
pclass_pivot = train_df[["Pclass", "Survived"]].groupby(["Pclass"], as_index=False).mean().sort_values(by="Survived", ascending=False)
print(pclass_pivot)
Sex_pivot = train_df[["Sex", "Survived"]].groupby(["Sex"], as_index=False).mean().sort_values(by="Survived", ascending=False)
print(Sex_pivot)
parch_pivot = train_df[["Parch", "Survived"]].groupby(["Parch"], as_index=False).mean().sort_values(by="Survived", ascending=False)
print(parch_pivot)
sibsp_pivot = train_df[["SibSp", "Survived"]].groupby(['SibSp'], as_index=False).mean().sort_values(by='Survived', ascending=False)
print(sibsp_pivot) Pclass Survived Sex Survived
0 1 0.629630 0 female 0.742038
1 2 0.472826 1 male 0.188908
2 3 0.242363
Parch Survived SibSp Survived
3 3 0.600000 1 1 0.535885
1 1 0.550847 2 2 0.464286
2 2 0.500000 0 0 0.345395
0 0 0.343658 3 3 0.250000
5 5 0.200000 4 4 0.1666675
4 4 0.000000 5 5 0.000000
6 6 0.000000 6 8 0.000000これを見るとPclass、Sexは明らかに関係がありそうです。
またParch、SibSpははっきりとは掴めません。
Ageについてもみてみましょう。
import matplotlib.pyplot as plt
import pandas as pd
train_df = pd.read_csv("/kaggle/input/titanic/train.csv")
test_df = pd.read_csv("/kaggle/input/titanic/test.csv")
Age_se = train_df["Age"].dropna()
train_df["Age"].hist(bins=8)
plt.show()
train_df["Age"].hist(by=train_df["Survived"], bins=10)
plt.show()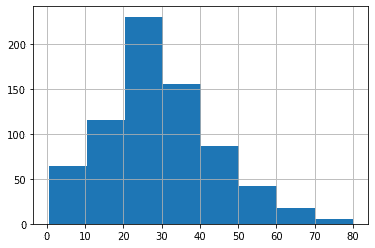
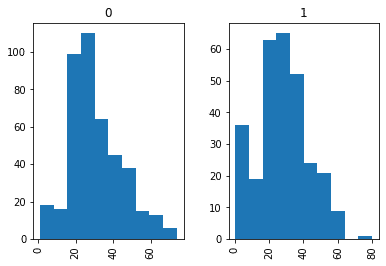
グラフで表してみました。全体の年齢層は20-30代が最も多くなっています。Survivedで分けたときは、だいたい15歳以下の生存率が高く、15-30歳ぐらいの方が多く死亡し、20-40歳ぐらいの方が多く生き残っているように読み取れます。
Fareについてもみてみましょう。
import pandas as pd
import matplotlib.pyplot as plt
train_df = pd.read_csv("/kaggle/input/titanic/train.csv")
test_df = pd.read_csv("/kaggle/input/titanic/test.csv")
pivot = train_df[["Survived", "Fare"]].groupby(["Survived"], as_index=False).mean()
plt.bar(pivot["Survived"], pivot["Fare"])
plt.xlabel('Survived')
plt.ylabel('Fare')
plt.show()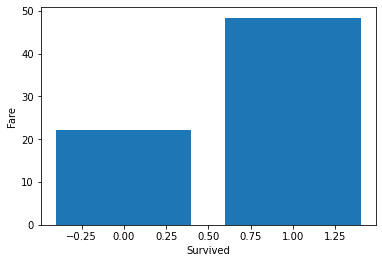
生き残っている人のが高い料金を払っていることがわかります。
最後にEmbarkedについて。
import pandas as pd
import matplotlib.pyplot as plt
train_df = pd.read_csv("/kaggle/input/titanic/train.csv")
test_df = pd.read_csv("/kaggle/input/titanic/test.csv")
pivot = train_df[["Survived", "Embarked"]].groupby(["Embarked"], as_index=False).mean()
plt.bar(pivot["Embarked"], pivot["Survived"])
plt.show()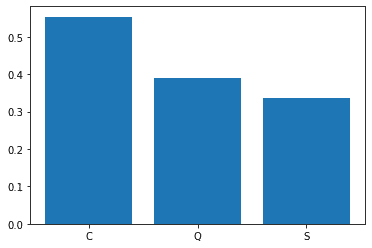
Cherbourgから乗船している人の生存率が高いようです。
これより各項目と生死についての関係性をまとめると、
・Pclass 関係あり
・Sex 関係あり
・Age 関係あり
・Fare 関係あり
・Embarked 関係あり
・Parch/SubSp 不明
となります。チケット番号や欠損の多かった部屋番号は取り除くことにします。
また、名前はMr.やMrs.等の敬称の部分のみ活用したいと思います。
コード編
これが今回書いたコードになります。#1、#2のように部分ごとに番号を振ってあります。
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
train_df = pd.read_csv("/kaggle/input/titanic/train.csv")
test_df = pd.read_csv("/kaggle/input/titanic/test.csv")
#1
train_df = train_df.drop(["Ticket", "Cabin"], axis=1)
test_df = test_df.drop(["Ticket", "Cabin"], axis=1)
combine = [train_df, test_df]
#2
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Capt": 5, "Lady": 6, "Countess": 7, "Col": 8, "Don": 9, "Dr": 10, "Major": 11, "Rev": 12, "Sir": 13, "Jonkheer": 14, "Mlle": 15, "Ms": 16, "Mme": 17}
for dataset in combine:
dataset["Title"] = dataset["Title"].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
train_df = train_df.drop(['Name', 'PassengerId'], axis=1)
test_df = test_df.drop(['Name'], axis=1)
combine = [train_df, test_df]
#3
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int)
#4
guess_ages = np.zeros((2,3))
for dataset in combine:
for i in range(0, 2):
for j in range(0, 3):
guess_df = dataset[(dataset['Sex'] == i) & (dataset['Pclass'] == j+1)]['Age'].dropna()
age_guess = guess_df.median()
guess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5
for i in range(0, 2):
for j in range(0, 3):
dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1), 'Age'] = guess_ages[i,j]
dataset['Age'] = dataset['Age'].astype(int)
for dataset in combine:
dataset.loc[dataset['Age'] <= 10, 'Age'] = 0
dataset.loc[(dataset['Age'] > 10) & (dataset['Age'] <= 20), 'Age'] = 1
dataset.loc[(dataset['Age'] > 20) & (dataset['Age'] <= 30), 'Age'] = 2
dataset.loc[(dataset['Age'] > 30) & (dataset['Age'] <= 40), 'Age'] = 3
dataset.loc[(dataset['Age'] > 40) & (dataset['Age'] <= 50), 'Age'] = 4
dataset.loc[(dataset['Age'] > 50) & (dataset['Age'] <= 60), 'Age'] = 5
dataset.loc[(dataset['Age'] > 60) & (dataset['Age'] <= 70), 'Age'] = 6
dataset.loc[(dataset['Age'] > 70) & (dataset['Age'] <= 80), 'Age'] = 7
dataset.loc[(dataset['Age'] > 80) & (dataset['Age'] <= 90), 'Age'] = 8
#5
freq_port = train_df.Embarked.dropna().mode()[0]
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
#6
test_df['Fare'].fillna(test_df['Fare'].dropna().median(), inplace=True)
for dataset in combine:
dataset.loc[ dataset['Fare'] <= 7.55, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.55) & (dataset['Fare'] <= 7.854), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 7.854) & (dataset['Fare'] <= 8.05), 'Fare'] = 2
dataset.loc[(dataset['Fare'] > 8.05) & (dataset['Fare'] <= 10.5), 'Fare'] = 3
dataset.loc[(dataset['Fare'] > 10.5) & (dataset['Fare'] <= 14.454), 'Fare'] = 4
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 21.679), 'Fare'] = 5
dataset.loc[(dataset['Fare'] > 21.679) & (dataset['Fare'] <= 27.0), 'Fare'] = 6
dataset.loc[(dataset['Fare'] > 27.0) & (dataset['Fare'] <= 39.688), 'Fare'] = 7
dataset.loc[(dataset['Fare'] > 39.688) & (dataset['Fare'] <= 77.958), 'Fare'] = 8
dataset.loc[(dataset['Fare'] > 77.958) & (dataset['Fare'] <= 512.329), 'Fare'] = 9
dataset['Fare'] = dataset['Fare'].astype(int)
#7
X_train = train_df.drop("Survived", axis=1)
Y_train = train_df["Survived"]
X_test = test_df.drop("PassengerId", axis=1)
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
random_pred = random_forest.predict(X_test)
acc_random_forest = round(random_forest.score(X_train, Y_train)* 100, 2)
print(acc_random_forest)
submission = pd.DataFrame({
"PassengerId": test_df["PassengerId"],
"Survived": random_pred
})
submission.to_csv('/kaggle/working/my_submission.csv', index=False)#1
TicketとCabinをデータの中から取り除きます。
操作がしやすいようcombineとしてまとめておきます。
train_df = train_df.drop(["Ticket", "Cabin"], axis=1)
test_df = test_df.drop(["Ticket", "Cabin"], axis=1)
combine = [train_df, test_df]#2
名前の中から敬称の部分を取り出し、Titleという欄を新しく作り敬称を入れていきます。その後それぞれの敬称に対し番号を振っていきます。
最後にNameとPassengerIDを取り除きます。
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Capt": 5, "Lady": 6, "Countess": 7, "Col": 8, "Don": 9, "Dr": 10, "Major": 11, "Rev": 12, "Sir": 13, "Jonkheer": 14, "Mlle": 15, "Ms": 16, "Mme": 17}
for dataset in combine:
dataset["Title"] = dataset["Title"].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
train_df = train_df.drop(['Name', 'PassengerId'], axis=1)
test_df = test_df.drop(['Name'], axis=1)
combine = [train_df, test_df]#3
Sexに番号を振ります。
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int)#4
Ageの欠損値を埋めていきます。
今回は同じ港から乗船し同性の人の年齢の中間値で埋めました。
そして、年代ごとに番号を振りました。
guess_ages = np.zeros((2,3))
for dataset in combine:
for i in range(0, 2):
for j in range(0, 3):
guess_df = dataset[(dataset['Sex'] == i) & (dataset['Pclass'] == j+1)]['Age'].dropna()
age_guess = guess_df.median()
guess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5
for i in range(0, 2):
for j in range(0, 3):
dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1), 'Age'] = guess_ages[i,j]
dataset['Age'] = dataset['Age'].astype(int)
for dataset in combine:
dataset.loc[ dataset['Age'] <= 10, 'Age'] = 0
dataset.loc[(dataset['Age'] > 10) & (dataset['Age'] <= 20), 'Age'] = 1
dataset.loc[(dataset['Age'] > 20) & (dataset['Age'] <= 30), 'Age'] = 2
dataset.loc[(dataset['Age'] > 30) & (dataset['Age'] <= 40), 'Age'] = 3
dataset.loc[(dataset['Age'] > 40) & (dataset['Age'] <= 50), 'Age'] = 4
dataset.loc[(dataset['Age'] > 50) & (dataset['Age'] <= 60), 'Age'] = 5
dataset.loc[(dataset['Age'] > 60) & (dataset['Age'] <= 70), 'Age'] = 6
dataset.loc[(dataset['Age'] > 70) & (dataset['Age'] <= 80), 'Age'] = 7
dataset.loc[(dataset['Age'] > 80) & (dataset['Age'] <= 90), 'Age'] = 8#5
Embarkedの欠損値は一番多くの人が乗った港を入れました。
そしてそれぞれの港に番号を振ります。
freq_port = train_df.Embarked.dropna().mode()[0]
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)#6
テストデータにFareの欠損値があるので中間値で埋めました。
その後、価格帯で分類し番号を振っています。
分類の数値に関しては次のコードで出てきた数値を使っています。
train_df['FareBand'] = pd.qcut(train_df['Fare'],10)
train_df[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by='FareBand', ascending=True)test_df['Fare'].fillna(test_df['Fare'].dropna().median(), inplace=True)
for dataset in combine:
dataset.loc[ dataset['Fare'] <= 7.55, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.55) & (dataset['Fare'] <= 7.854), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 7.854) & (dataset['Fare'] <= 8.05), 'Fare'] = 2
dataset.loc[(dataset['Fare'] > 8.05) & (dataset['Fare'] <= 10.5), 'Fare'] = 3
dataset.loc[(dataset['Fare'] > 10.5) & (dataset['Fare'] <= 14.454), 'Fare'] = 4
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 21.679), 'Fare'] = 5
dataset.loc[(dataset['Fare'] > 21.679) & (dataset['Fare'] <= 27.0), 'Fare'] = 6
dataset.loc[(dataset['Fare'] > 27.0) & (dataset['Fare'] <= 39.688), 'Fare'] = 7
dataset.loc[(dataset['Fare'] > 39.688) & (dataset['Fare'] <= 77.958), 'Fare'] = 8
dataset.loc[(dataset['Fare'] > 77.958) & (dataset['Fare'] <= 512.329), 'Fare'] = 9
dataset['Fare'] = dataset['Fare'].astype(int)ここまでで、データの中身はこのようになっています。
Survived Pclass Sex Age SibSp Parch Fare Embarked Title
0 0 3 0 2 1 0 0 0 1
1 1 1 1 3 1 0 8 1 3
2 1 3 1 2 0 0 2 0 2
3 1 1 1 3 1 0 8 0 3
4 0 3 0 3 0 0 2 0 1
5 0 3 0 2 0 0 3 2 1
6 0 1 0 5 0 0 8 0 1
7 0 3 0 0 3 1 5 0 4
8 1 3 1 2 0 2 4 0 3
9 1 2 1 1 1 0 7 1 3#7
最後にモデルを用いて予測を行っていきます。
なぜRandomForestを使っているかというと、様々なモデルで検証してみた結果これが一番いい数値を出したからです。
参考までに↓
Model Score
3 Random Forest 91.36
5 Decision Tree 91.36
1 KNN 86.42
4 Linear SVC 80.25
2 Logistic Regression 78.77
7 perceptron 77.67
0 Support Vector Machines 75.76
6 gaussian 73.06
8 sgd 48.37はじめに訓練用データのラベル作りをしています。
そしてランダムフォレストを用いて予測を行い、CSVファイルに保存しています。
X_train = train_df.drop("Survived", axis=1)
Y_train = train_df["Survived"]
X_test = test_df.drop("PassengerId", axis=1)
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
random_pred = random_forest.predict(X_test)
acc_random_forest = round(random_forest.score(X_train, Y_train)* 100, 2)
print(acc_random_forest)
submission = pd.DataFrame({
"PassengerId": test_df["PassengerId"],
"Survived": random_pred
})
submission.to_csv('/kaggle/working/my_submission.csv', index=False)提出した結果がこちら!
スコアは76.315%でした。順位はおそらく14374位。
全体で17000人ぐらいなのでまだまだでした。
改善点
・今回は家族・親戚の部分をそのまま使っていますが、例えばそれらをまとめて一つの特微量にする
・敬称をまとめてみる(Mr/Miss/Mrsの3つなど)
・年齢、価格帯の分け方を変えてみる。
・欠損値の埋め方を変える。
・Age、Fare、Embarkedをまとめて一つの特微量にする
などまだまだできることはたくさんあると思います。
今度挑戦してみたいと思います。
この記事が気に入ったらサポートをしてみませんか?