『Aidemy-AIアプリコース』受講記:16日目(深層学習①)

プログラミングスクール「Aidemy」を受講し、その体験記をコツコツ書いていこうと思います。
「Aidemy」の受講を検討している方、どんなことをするかイメージを持っていただければ幸いです。
自己紹介:
大卒。ITに関して無知識。
新卒で造船業:現場管理。転職を目指し「Aidemy」を受講。
8/3
<16日目>
今日から10章突入です!
<今日の学習内容>
10-1 : 深層学習の実践(1.5h)
まず深層学習(ディープラーニング)とは、生物の神経細胞を模したアルゴリズム「ニューラルネットワーク」を使用した現在最も高い精度が出やすい機械学習の技術の一つです。
ディープラーニングの仕組みについてを前半に学び、後半は手書き文字の分類をやりながらディープラーニングとはこんな感じですよと言うのを体験しました。
ディープラーニングは、予測したものと正解ラベルとの差を見てプログラムが勝手に微調整を加えてくれます。
例えば犬と猫の画像の分類を考えます。
犬のデータを与えたとき1回目の予想が犬の確率40%、猫の確率60%と判断したとします。
正解ラベルは犬:1、猫:0であるためそれぞれの予測との差を見て重みと言う変数をいじります。
これを繰り返していくうちに、犬97%、猫3%と判断できるようになりました。
こんな感じでプログラム自信が調整を加えてより正しい分類ができるように学習していきます。
なんかすごいですね!
パパッと図でもかければより説明しやすいのですが、解説ではなく個人の勉強日誌のためめんどくさいことはしません笑
後半は実際に手書き文字を使ってディープラーニングをしてみました。
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.layers import Activation, Dense
from keras.models import Sequential, load_model
from keras.utils.np_utils import to_categorical
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 784)[:6000]
X_test = X_test.reshape(X_test.shape[0], 784)[:1000]
y_train = to_categorical(y_train)[:6000]
y_test = to_categorical(y_test)[:1000]
model = Sequential()
model.add(Dense(256, input_dim=784))
model.add(Activation("sigmoid"))
model.add(Dense(128))
model.add(Activation("sigmoid"))
model.add(Dense(10))
model.add(Activation("softmax"))
model.compile(optimizer="sgd", loss="categorical_crossentropy", metrics=["accuracy"])
model.fit(X_train, y_train, verbose=True)
score = model.evaluate(X_test, y_test, verbose=False)
print("evaluate loss: {0[0]}\nevaluate acc: {0[1]}".format(score))
for i in range(10):
plt.subplot(1, 10, i+1)
plt.imshow(X_test[i].reshape((28,28)), "gray")
plt.show()
pred = np.argmax(model.predict(X_test[0:10]), axis=1)
print(model.predict(X_test[0:10]))
print(pred)
#学習中
Epoch 1/10
6000/6000 [==============================] - 0s - loss: 2.0722 - acc: 0.4382
Epoch 2/10
6000/6000 [==============================] - 0s - loss: 1.6622 - acc: 0.6818
Epoch 3/10
6000/6000 [==============================] - 0s - loss: 1.3428 - acc: 0.7590
Epoch 4/10
6000/6000 [==============================] - 0s - loss: 1.1064 - acc: 0.7968
Epoch 5/10
6000/6000 [==============================] - 0s - loss: 0.9320 - acc: 0.8278
Epoch 6/10
6000/6000 [==============================] - 0s - loss: 0.8020 - acc: 0.8487
Epoch 7/10
6000/6000 [==============================] - 0s - loss: 0.7017 - acc: 0.8700
Epoch 8/10
6000/6000 [==============================] - 0s - loss: 0.6229 - acc: 0.8817
Epoch 9/10
6000/6000 [==============================] - 0s - loss: 0.5599 - acc: 0.8892
Epoch 10/10
6000/6000 [==============================] - 0s - loss: 0.5071 - acc: 0.8973
evaluate loss: 0.613485613822937
evaluate acc: 0.853
#予測結果
[7 2 1 0 4 1 4 9 6 9]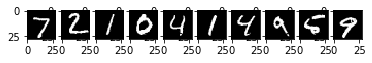
これはテストデータの最初の10枚を表示しています。
28*28ピクセルの画像6000枚を使って学習し、1000枚のテストデータで正解率を出しています。
10回繰り返し学習していき、最終的には85.3%の正解率になりました。
最初の10枚では画像と予測結果が一致していますね!多分(9枚目が僕は何かはっきりとはわかりませんでしたので、、、)
[[ 6.84821093e-03 1.61062705e-03 2.26838910e-03 8.30130465e-03
6.07547536e-03 4.64851223e-03 5.74017351e-04 9.30753767e-01
6.02649152e-03 3.28932367e-02]
[ 8.56032744e-02 1.42430887e-02 4.00587499e-01 7.25976378e-02
3.46655119e-03 1.30619481e-01 1.74412847e-01 2.66527687e-03
1.12795025e-01 3.00931674e-03]
[ 3.77990160e-04 9.32596445e-01 1.77142117e-02 7.29891798e-03
3.00386618e-03 5.15536312e-03 7.11730821e-03 9.69153270e-03
1.12792626e-02 5.76523412e-03]
[ 8.80854130e-01 6.48881309e-04 1.24607012e-02 1.02195824e-02
1.34015828e-03 4.68244106e-02 1.23519283e-02 1.43757770e-02
1.71814822e-02 3.74298333e-03]
[ 5.15676942e-03 1.67431927e-03 4.17275839e-02 3.12578282e-03
6.76263988e-01 6.93902699e-03 4.22624871e-02 2.97353044e-02
1.40315359e-02 1.79083213e-01]
[ 2.85776216e-04 9.42013562e-01 1.08841974e-02 8.23874213e-03
1.63399964e-03 6.05822867e-03 2.99990154e-03 1.19931707e-02
1.07423738e-02 5.15010767e-03]
[ 3.05335294e-03 3.74996918e-03 3.79526359e-03 2.10292079e-02
5.41058242e-01 4.86084260e-02 8.80642142e-03 4.08638418e-02
4.31662351e-02 2.85869122e-01]
[ 1.87026255e-03 2.42098477e-02 1.03677996e-02 1.61993746e-02
3.67045790e-01 6.46010265e-02 4.08490971e-02 3.48498747e-02
2.81325877e-02 4.11874354e-01]
[ 3.02447211e-02 1.16238035e-02 1.65878072e-01 4.60114796e-03
1.41148910e-01 6.53258786e-02 4.53815490e-01 1.41432239e-02
6.53259382e-02 4.78928499e-02]
[ 2.62863678e-03 6.35525631e-03 2.29381165e-03 3.96611122e-03
1.22750215e-01 1.10323578e-02 6.17067283e-03 2.15311438e-01
1.85018796e-02 6.10989630e-01]]これは学習後です。
10枚それぞれで0である確率、1である確率・・・9である確率が出ています。
その中で一番確率の高いものを出力しています!
np.argmaxは一番高い数字のインデックス(何番目に高い数字が入っているか)を返しています。
今回は体験的な意味合いが強かったです。
8-2では実際にプログラムを書くための勉強になりそうです!
それではまた明日!
この記事が気に入ったらサポートをしてみませんか?