
『バトル・ロワイアル』の登場人物情報を『GPT for Sheets™ and Docs™』で仕分ける

目的
非定型的な文章で表現されているが、ある程度内容は決まっている大量の情報をスプレッドシートにまとめ、
文章中から目的の情報をチャットGPTで抽出する。
⇒『バトル・ロワイアル』に登場する約四十人の生徒たちのプロフィール情報。
各生徒で文章量が違ったり、項目として整理されていなかったりするが、概ね『支給された武器』『出席番号』『キャラクター設定』『死因』などの情報を含む。
最初に考えた工程
(1)ウィキペディア『バトル・ロワイアルの登場人物』から、『城岩中学校3年B組 男子』と『城岩中学校3年B組 女子』の部分をザーッとコピー。
(2)「登場人物名」「演者」「人物紹介」の3つの要素に分け、スプレッドシートにインポートできる記述にする。
(3)「性格」「支給武器」「出席番号」等を(2)の「人物紹介」から抽出する。
素材
・ウィキペディア『バトル・ロワイアルの登場人物』の『城岩中学校3年B組 男子』と『城岩中学校3年B組 女子』の部分をコピーし、Googleドキュメントにとりあえずペーストしたもの。
・『GPT for Sheets™ and Docs™』のアドオン。

実践
工程(1)と(2):つまずいたポイント
・Googleドキュメントにコピペした生徒の情報をチャットGPTにさらにコピペし、カンマ区切りにしたかったが、長すぎて処理できない(csvファイル的なことができないかと思った)。
⇒GASのほうに貼り、見出しを基準に繰り返しで読み込む。ついでに、スプレッドシートに自動で表にしてくれないか。
function importCharacterData() {
var ss = SpreadsheetApp.getActiveSpreadsheet();
var sheet = ss.getActiveSheet();
var text = ""; // Googleドキュメントからコピペしたテキストをこの変数に格納します
var lines = text.split(/\n/);
var result = [];
for(var i = 0; i < lines.length; i++) {
if(lines[i].match(/演 -/)) {
var characterName = lines[i-1].trim();
var actor = lines[i].replace("演 -", "").trim();
var description = "";
for(var j = i + 1; j < lines.length; j++) {
if(lines[j].match(/演 -/)) {
break;
}
description += lines[j].trim() + " ";
}
result.push([characterName, actor, description.trim()]);
}
}
sheet.getRange(1, 1, result.length, 3).setValues(result);
}
ChatGPTに書かせた上記コードをGASに貼り付け、『var text = "";』の『""』間にWikiからのコピペを張り付けたところ、以下の問題が起きる。
・Wikiからのコピペ部分に、エラーが大量に出る。
・『MyFanction』しか実行できない。
そこで、再度ChatGPTに聞いてみる。
⇒『“”』ではなく『‘(バッククオート)』で括ると解決するはず、という返答
⇒エラーが消え、『importCharactorData』も選択できるように。
無事、スプレッドシートに表ができ、工程(3)に進むことができました。


工程(3):つまずいたポイント
・レギュレーションが一定でない「人物紹介」から、目的の情報を全体に統一感を持たせながら引き出すプロンプトが難しい。
・同じプロンプトなのに、情報がひとつのセルにおさまる人物とおさまらない人物が出てきて、エラーが起きる。
・プロンプトが長文になると大体反応しない(例:×「映画版で支給された武器」○「支給武器」)
・物騒な単語に反応しない?(例:×「死因」「殺害された経緯」○「劇中でどのように死んだのか」)
・レギュレーションによっては端的すぎる答えになる。(例:×「性格」○「劇中のエピソード」)
例)『人物紹介(D列の文章)』から『キャラクター設定』についてまとめる:以下のプロンプトを使用。
=GPT_EXTRACT(D列相対セル, "ひとつのセルに収める形式で、人物像の説明")

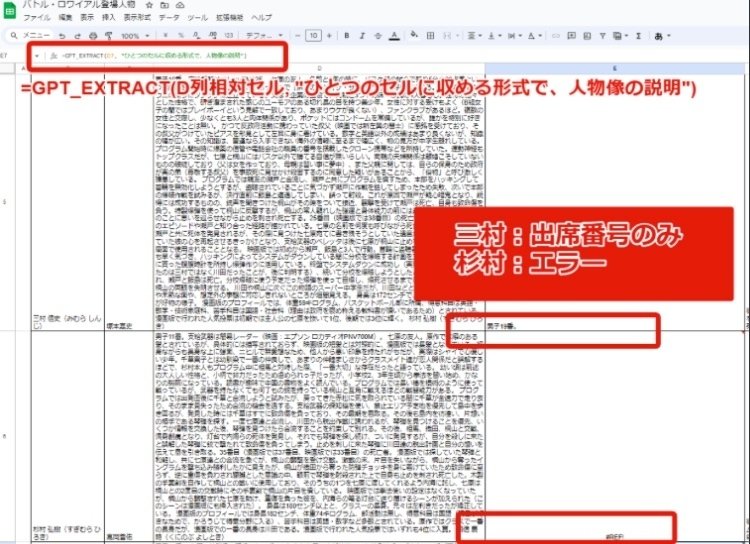

工程(3)のプロンプトについては、追って検証していこうと思います。
まとめ
わかったこと
・ChatGPTなので、物騒な単語や性的な単語を含む文章に反応しない可能性がある(RG15指定のデスゲームを題材に選んでしまったため『殺す』『売春』などの単語が含まれていた)
・ウィキペディアは複雑なHTMLで記述されていること。
・ChatGPTのトークンの安さ。各自で有料アカウントを持つのではなく、複数人でAPIキーを使い、経済的に済ませられる場面がありそう。
余裕があれば検証すること・調べること・知りたいこと
・GASに『importCharactorData』などという関数がデフォルトであるのか(どこかで定義した?)
・物騒ではない作品の登場人物情報を使ったらどうなるのか、試してみる。
・語学(要約・翻訳・反訳等)の用途向けに特化させた生成AIのアドオンはあるのか。
⇒抽出は捨て、要約が欲しい時。物騒だろうと性的だろうと、単純に要約という仕事をしてくれるもの。
・ウィキペディアのHTMLについて知り、スクレイピングする方法を考える。
・セル一個に出力をおさめる、または、エラーが出にくい方法を考える。
・人の手を加えたほうがラクで、精度も上げられる工程はありそうか。
・企業内の実践においては、どのような業務に転用できるか。
この記事が参加している募集
面白いと感じてくださいましたら、サポート嬉しいです。 ランチ・喫茶店・おやつ代に充て、noteに写真でアップします。 友人との時間や、仕事の合間の息抜きに使わせていただきます。