
【論文瞬読】大規模言語モデルの新潮流:Mixture of Experts (MoE) の可能性と課題

こんにちは、みなさん。株式会社AI Nestです。今日は、最近の大規模言語モデルの研究で注目を集めているMixture of Experts (MoE) について、お話ししたいと思います。
タイトル:A Survey on Mixture of Experts
URL:https://arxiv.org/abs/2407.06204
所属:The Hong Kong University of Science and Technology (Guangzhou), China
著者:Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, Jiayi Huang
MoEとは?
MoEは、複数の専門家モデル (expert) とゲーティング機構を組み合わせることで、大規模なモデルを効率的に学習・推論するための手法です。expertは、タスクに特化した知識を持つ個々のニューラルネットワークで、ゲーティング機構は、入力に応じて適切なexpertを選択する役割を担っています。

従来の言語モデルでは、すべての入力に対して同じニューラルネットワークを適用していました。しかし、MoEでは、入力の特性に応じて異なるexpertを選択的に適用することで、より効率的かつ効果的な処理を実現します。例えば、科学関連の文章を処理する際には科学に特化したexpertを、法律関連の文章を処理する際には法律に特化したexpertを適用するといった具合です。
MoEの魅力は、計算コストを抑えつつ、モデルの表現力を大幅に向上できる点にあります。つまり、少ない計算リソースで、より高度な言語処理を実現できる可能性を秘めているのです。これは、大規模言語モデルの実用化に向けて、非常に重要な意味を持っています。
MoEの最新動向
アルゴリズム設計
MoEのアルゴリズム設計に関する研究では、ゲーティング機構やexpertネットワークの改善が活発に行われています。例えば、Switch Transformer [1] では、ルーティングの効率化とexpertの専門性の向上を目的とした新しいゲーティング機構が提案されています。また、GShard [2] では、expertの負荷分散を考慮した学習手法が導入され、より安定的なMoEの学習が可能になりました。
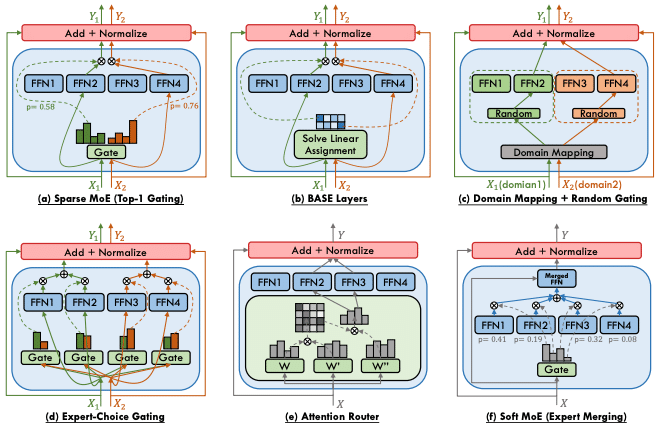



これらの研究により、MoEのゲーティング機構の効率性と柔軟性が大きく向上しています。また、expertネットワークの設計に関する知見も蓄積されつつあり、タスクに適した専門性の高いexpertを構築するための指針が明らかになりつつあります。
システム設計
MoEの大規模化に伴い、システム設計に関する研究も重要性を増しています。大規模なMoEを効率的に学習・推論するためには、計算リソースの最適化や通信コストの削減が欠かせません。

DeepSpeed-MoE [3] では、MoEに特化した並列化手法が提案されています。expertごとに計算を分散させることで、大規模なMoEを効率的に学習できるようになりました。また、FasterMoE [4] では、通信コストを削減するための技術が導入され、より大規模なMoEの学習が可能になっています。
これらの研究により、数千億から数兆のパラメータを持つ超大規模なMoEを、現実的な計算コストで学習・推論できるようになりつつあります。
Mixture of Parameter-Efficient Experts (MoPE)
最近では、パラメータ効率の良いファインチューニング (PEFT) 手法とMoEを組み合わせるMixture of Parameter-Efficient Experts (MoPE) の枠組みが注目を集めています。PEFTは、事前学習済みの大規模モデルを、少数のパラメータのみを更新することで効率的にファインチューニングする手法です。
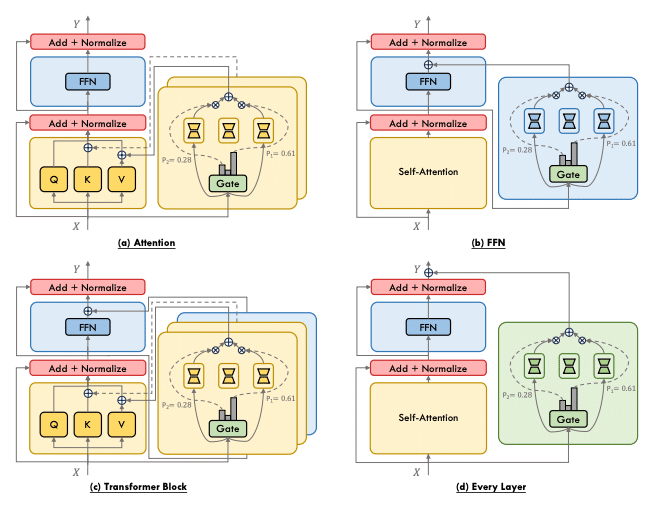
MoPEでは、PEFTで学習したexpertを組み合わせることで、タスクに特化した高性能なMoEを構築します。これにより、大規模なMoEを、より少ないファインチューニングコストで特定のタスクに適応させることが可能になります。
MoPEは、大規模言語モデルの適用可能性を大きく広げる可能性を持っており、様々なタスクでの性能向上が報告されています。例えば、MoELoRA [5] では、LoRAを用いたMoPEが提案され、自然言語処理の複数のタスクで高い性能を達成しています。
課題と展望
MoEは、大規模言語モデルの効率的な学習・推論を可能にする有望な技術ですが、まだ多くの課題が残されています。

Original、Expert Models Merging、Dense-to-Sparse、Sparse-to-Denseの
4つのスキーム
学習の不安定性と負荷分散
MoEの学習では、expertの専門性を高めつつ、全体としての性能を向上させる必要があります。しかし、これらのバランスを取ることは容易ではなく、学習が不安定になる場合があります。また、expertごとの負荷が偏ってしまい、一部のexpertに計算が集中してしまう問題も指摘されています。
これらの課題に対しては、ゲーティング機構の改善やexpertの負荷分散を考慮した学習手法の開発が進められています。しかし、完全な解決には至っておらず、さらなる研究が必要とされています。
解釈性と透明性
MoEは、複数のexpertが協調して動作する複雑なシステムです。このため、モデルの振る舞いを理解し、説明することが難しくなります。特に、ゲーティング機構がどのようにexpertを選択しているのか、expertがどのような知識を獲得しているのかを解釈することは容易ではありません。
モデルの解釈性と透明性は、AIシステムへの信頼性を確保する上で重要な課題です。MoEに関しても、解釈性の高いゲーティング機構やexpertの開発、説明可能なモデルの構築などが求められています。
適用領域の拡大
現在のMoEは、主に自然言語処理の分野で活躍しています。しかし、MoEのアイデアは、他の分野にも応用可能であると考えられます。例えば、コンピュータビジョンやマルチモーダル学習、レコメンダーシステムなどへのMoEの適用が期待されています。
これらの分野では、タスクの多様性や入力の複雑さに対応するために、MoEの柔軟性と効率性が活かせるはずです。今後は、MoEをさまざまな分野に適用し、その有効性を実証していくことが重要になるでしょう。
終わりに
MoEは、大規模言語モデルの新たな可能性を切り開く技術として注目を集めています。計算効率と性能のバランスを取りつつ、より高度な言語処理を実現できる点が魅力的です。また、MoPEに代表されるようなPEFTとの組み合わせにより、さらなる応用の可能性が広がっています。
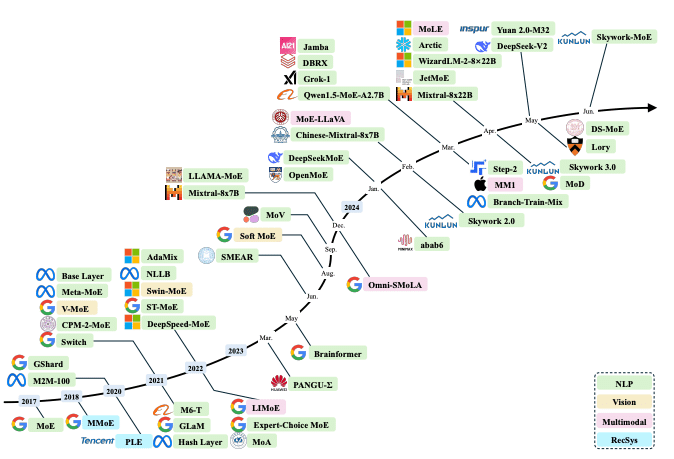

一方で、学習の不安定性や負荷分散、解釈性と透明性など、まだ多くの課題が残されていることも事実です。これらの課題を解決し、MoEの真の力を引き出すためには、研究コミュニティの継続的な努力が不可欠です。
今後は、これらの課題に立ち向かいながら、MoEの更なる改善と応用に向けた研究が進められることを期待しています。自然言語処理をはじめとする様々な分野で、MoEが新たなブレークスルーを生み出すことを楽しみにしています。
参考文献
[1] W. Fedus, et al. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. JMLR, 2022.
[2] D. Lepikhin, et al. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. arXiv, 2020.
[3] S. Rajbhandari, et al. DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale. ICML, 2022.
[4] J. He, et al. FasterMoE: Modeling and Optimizing Training of Large-Scale Dynamic Pre-Trained Models. PPoPP, 2022.
[5] T. Luo, et al. MoELoRA: Contrastive Learning Guided Mixture of Experts on Parameter-Efficient Fine-Tuning for Large Language Models. arXiv, 2024.