
【論文瞬読】RAG: 大規模言語モデルを飛躍的に進化させる次世代技術

こんにちは!株式会社AI Nestです。今回は、自然言語処理技術である「Retrieval-Augmented Generation (RAG)」について、改めてわかりやすく解説していきたいと思います。
タイトル:Retrieval-Augmented Generation for Large Language Models: A Survey
URL:https://arxiv.org/abs/2312.10997
所属:Shanghai Research Institute for Intelligent Autonomous Systems, Tongji University, Shanghai Key Laboratory of Data Science, School of Computer Science, Fudan University, College of Design and Innovation, Tongji University
著者:Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, Haofen Wang
RAGとは?
RAGは、大規模言語モデル(Large Language Models; LLMs)の性能を向上させるための手法の一つです。LLMは、GPT-3やT5などに代表される、数億から数千億のパラメータを持つ超大規模な言語モデルのことを指します。これらのモデルは、大量のテキストデータを学習することで、人間のような自然な文章生成や質問応答が可能になりましたが、一方で、ハルシネーション(幻覚)や知識の陳腐化、推論プロセスの不透明性などの課題も抱えています。
RAGは、LLMの内在知識と外部データベースの膨大で動的な知識を相乗的に組み合わせることで、これらの課題に対処しようとしています。つまり、LLMの「頭の中の知識」だけでなく、「外部の知識」も活用することで、より正確で最新の情報に基づいた文章生成や質問応答を目指すのです。
具体的には、RAGは以下のようなプロセスで動作します。
ユーザーからの質問を受け取る
質問に関連する情報を外部知識ベースから検索する
検索結果を基に、LLMを使って自然な文章を生成する
生成された文章をユーザーに返す

このように、RAGは検索と生成を組み合わせることで、LLMの能力を拡張しているのです。
RAGの進化 - 3つのパラダイム
RAGの研究は、大きく3つのパラダイムに分けられます。
Naive RAG:最も基本的なRAGの形で、検索、生成、増強という3つのステップを順番に実行します。Naive RAGは、シンプルで理解しやすい反面、検索の精度や生成文章の品質に課題がありました。
Advanced RAG:Naive RAGの課題を解決するために、検索前後の処理を最適化します。例えば、検索クエリの最適化、検索結果のランク付け、生成文章の後処理などを行うことで、より高品質な結果を得ることができます。
Modular RAG:より柔軟で適応性の高いRAGを目指し、モジュール化や新しい処理の流れを導入します。Modular RAGでは、検索、生成、増強の各ステップが独立したモジュールとして扱われ、タスクに応じて最適な組み合わせを選択できます。また、反復的な検索や、検索と生成の同時最適化なども可能になります。

これらのパラダイムは、RAG技術の進化の過程を表しており、それぞれ特徴と長所があります。Naive RAGは基本的な仕組みを理解する上で重要ですが、実用的なRAGシステムを構築するには、Advanced RAGやModular RAGの技術が必要不可欠です。
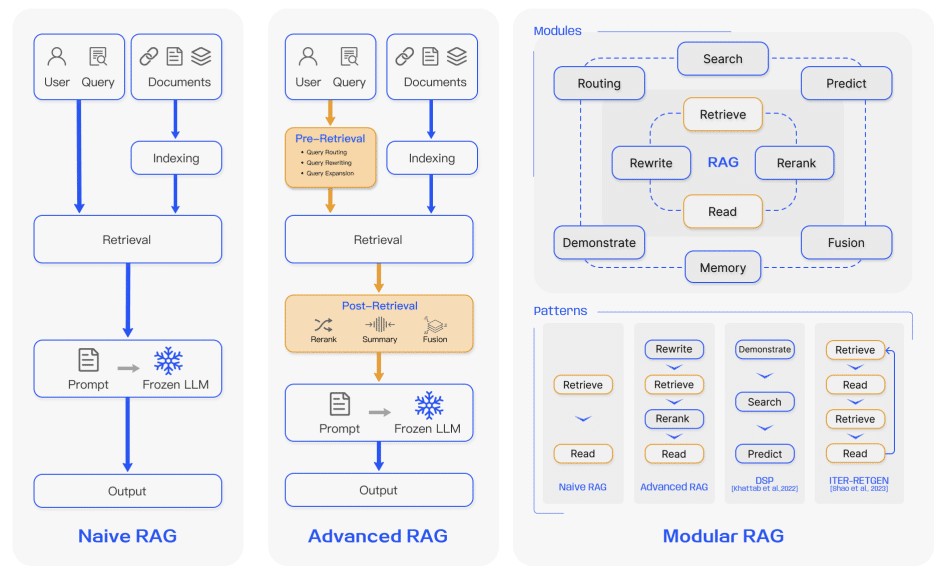
RAGの3要素 - 検索、生成、増強
RAGシステムを支える3つの要素技術についても、もう少し詳しく見ていきましょう。
検索(Retrieval):外部知識ベースから、ユーザーの質問に関連する情報を見つけ出します。効果的な検索を行うためには、知識ベースのインデックス化、検索クエリの最適化、関連性スコアリングなどの技術が重要です。また、検索結果の多様性を確保することで、より広い文脈を捉えることができます。
生成(Generation):検索で得た情報を基に、自然な文章を生成します。生成には、LLMの言語モデリング能力が活用されます。ただし、検索結果をそのまま使うのではなく、文脈に合わせて適切に要約したり、関連性の低い情報を除外したりする必要があります。また、生成された文章の整合性や忠実性を確保することも重要です。
増強(Augmentation):検索と生成を繰り返し、より良い結果を得るためのフィードバックループです。例えば、生成された文章を基に追加の検索を行い、新たな情報を取り込むことで、より完全な回答を生成できます。また、ユーザーからのフィードバックを利用して、検索クエリや生成文章の品質を向上させることもできます。

これらの要素技術は、互いに密接に関連しており、どれか一つが欠けてもRAGシステムの性能は大きく低下してしまいます。したがって、各要素技術の研究開発を着実に進めていくことが重要です。
RAGの応用と評価
RAGは、質問応答だけでなく、情報抽出、対話生成、コード検索など、さまざまなタスクに応用できます。例えば、情報抽出では、RAGを使って文書から重要な情報を抽出し、構造化することができます。対話生成では、ユーザーの発話に対して、知識ベースを活用しながら自然な応答を生成できます。コード検索では、自然言語のクエリを基に、関連するコードスニペットを見つけ出すことができます。
ただし、タスクごとに適切な評価指標やベンチマークを整備することが重要です。現在、RAGの評価は発展途上にありますが、徐々に標準化が進んでいくでしょう。例えば、質問応答では、回答の正確性や完全性を測る指標が必要です。情報抽出では、抽出された情報の網羅性や正確性が重要です。対話生成では、応答の自然さや関連性が評価の対象になります。
これらの評価指標やベンチマークを整備することで、異なるRAGシステムの性能を公平に比較することができるようになります。また、評価結果を分析することで、RAGシステムの改善点や新たな研究課題を見つけ出すこともできるでしょう。
RAGの未来
RAGは、LLMの実用性を高める上で欠かせない技術になりつつあります。今後は、以下のような方向性で研究が進められていくと予想されます。
ロバスト性の向上:ノイズや矛盾する情報に対する耐性を高めます。現実世界の知識ベースには、誤りや古い情報が含まれている可能性があります。RAGシステムは、これらの問題に適切に対処できる必要があります。
長いコンテキストへの対応:より長い文脈を理解・生成できるようにします。現在のRAGシステムは、比較的短い文脈での動作に限定されています。しかし、複雑な質問に答えるためには、より長い文脈を扱える必要があります。
マルチモーダルへの拡張:テキストだけでなく、画像や音声なども扱えるようにします。現実世界の知識は、テキストだけでなく、画像や音声といった異なるモダリティで表現されています。これらすべてを統合的に扱えるRAGシステムが求められています。
他の技術との融合:ファインチューニングや強化学習などと組み合わせることで、さらなる性能向上を目指します。RAGは、他の機械学習技術と相性が良いため、これらを組み合わせることで、より強力なシステムを構築できる可能性があります。

これらの研究課題に取り組むことで、RAGはより実用的で汎用性の高い技術へと進化していくでしょう。
まとめ
RAGは、LLMの可能性を広げる革新的な技術です。外部知識を活用することで、より正確で最新の情報に基づいた自然言語処理を実現できます。まだ発展途上の技術ですが、着実に進化を遂げており、自然言語処理の研究者やエンジニアにとって必須の知識になりつつあります。
今回紹介した論文は、RAG研究の現状を俯瞰し、将来の方向性を示唆する上で非常に有益です。RAGの基本的な仕組みから、最新の研究動向まで、幅広くカバーされています。特に、3つのパラダイムと3つの要素技術に関する詳細な分析は、RAGシステムを理解し、設計する上で重要な知見を与えてくれます。
私自身、この論文を読んで、RAGの可能性と課題について、より深く理解することができました。特に、Modular RAGの考え方には興味を惹かれました。モジュール化によって、RAGシステムの柔軟性と適応性を高められる点は、実用上の大きなメリットになると思います。
また、RAGを異なるタスクに応用する際の評価指標やベンチマークの重要性も再認識しました。汎用的なRAGシステムを開発するためには、多様なタスクで性能を評価し、改善していく必要があります。この点は、今後の研究開発において重要な指針になるでしょう。

RAGの今後の発展に期待しつつ、私もこの分野の研究に励んでいきたいと思います。LLMとRAGの組み合わせは、自然言語処理の新しいパラダイムを切り開く可能性を秘めています。その実現に向けて、着実にステップを踏んでいきたいと考えています。
読者の皆さんも、RAGに興味を持っていただけたら幸いです。この記事が、RAGの理解を深める一助となれば光栄です。それでは、次回のブログでまた新しい話題でお会いしましょう!