
【論文瞬読】AI最前線、LLMの知識注入戦争!RAGがファインチューニングに勝利?

こんにちは!株式会社AI Nestです。今回は、大規模言語モデル(LLM)の世界で話題沸騰中の研究について、深掘りしていきたいと思います。みなさん、準備はいいですか?では、潜入開始!
タイトル:Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs
URL:https://arxiv.org/abs/2312.05934
所属:Microsoft, Israel
著者:Oded Ovadia、Menachem Brief、Moshik Mishaeli、 and Oren Elish
1. 衝撃の研究結果:RAGの圧勝
最近、Microsoft Israelの研究チームが発表した論文「Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs」が、AI界隈で大きな波紋を呼んでいます。この研究、一体何がそんなにすごいのでしょうか?
結論から言うと、LLMに新しい知識を注入する方法として、従来のファインチューニング(FT)よりも、検索拡張生成(RAG)の方が圧倒的に優秀だということが分かったのです。これ、めちゃくちゃビッグニュースなんです!

上の図を見てください。RAG(青色)がほぼすべてのケースでFT(オレンジ色)を上回っていることがわかりますね。特に、RAGを基本モデルに適用した場合(青色)が、FTを適用したモデル(オレンジ色)よりも高い精度向上を示しているのがポイントです。
2. RAGって何?FTと何が違うの?
ここで、ちょっと用語解説タイムです。
ファインチューニング(FT):事前学習済みのLLMを特定のタスクや領域用にさらに学習させる方法。モデルの重みを直接更新します。
検索拡張生成(RAG):外部の知識ベースから関連情報を検索し、それをLLMの入力に追加して回答を生成する方法。モデル自体は変更せず、入力を工夫します。
つまり、FTは「モデルに新しいことを覚えさせる」のに対し、RAGは「モデルに参考資料を与える」ようなイメージです。
3. 研究の詳細:どうやって比較したの?
研究チームは、以下のような壮大な実験を行いました:
使用モデル:Mistral 7B、Llama2 7B、Orca2 7Bの3種類のLLM
タスク:
MMLUベンチマーク(解剖学、天文学、生物学、化学、先史時代)
現在の出来事に関する独自データセット
設定:0-shot(例示なし)と5-shot(5つの例示あり)の両方
評価指標:対数尤度精度(簡単に言うと、正解の確からしさ)
これだけの大規模な比較実験、すごくないですか?研究者の皆さん、本当にお疲れ様です!
4. 衝撃の結果:RAGの圧倒的勝利
さて、結果はというと...
ほぼすべてのタスクで、RAGがFTを上回りました!

こちらの表を見てください。MMLUベンチマークの結果ですが、ほとんどすべてのケースでRAG(Base model + RAG列)がFT(Fine-tuned列)を上回っています。特に驚きなのは、RAGを使った基本モデルが、FTを施したモデルよりも高い精度を示したこと。これ、本当にすごいことなんです。
さらに面白いのは、現在の出来事(モデルが学習していない新しい情報)に関するタスクでの結果です。

この表を見てください。RAG(Base model + RAG列)が他のどの手法よりも圧倒的な強さを見せています。Mistral 7BとOrca2 7Bでは、RAGを使用した場合の精度が87%以上になっているんです!
5. 新発見:繰り返しの力
研究チームは、もう一つ重要な発見をしました。LLMに新しい知識を学習させるには、同じ情報を様々な形で繰り返し提示することが効果的だというのです。
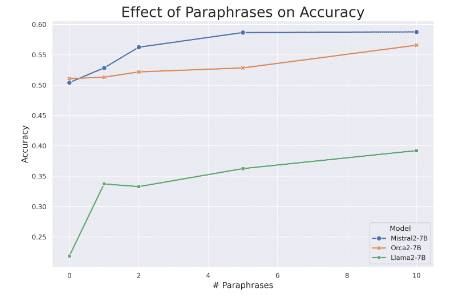
この図を見てください。パラフレーズ(言い換え)の数が増えるほど、モデルの精度が向上していることがわかります。つまり、同じ情報を様々な形で提示することで、モデルの理解が深まるんです。これ、人間の学習方法とも似ていて、なんだかホッとしませんか?
さらに、訓練中の損失の変化を見てみましょう。

この図は、Mistral-7Bモデルの訓練中の損失を示しています。エポック(全データを1周学習すること)が進むごとに損失が大きく減少しています。これは、繰り返し学習することでモデルの性能が向上していることを示しています。
6. RAGの課題:不安定なハイパーパラメータ
ただし、RAGにも課題はあります。最適な検索文書数(K)が一定せず、タスクやモデルによってバラつきがあるのです。これは実用化の際の大きな課題となりそうです。
7. 今後の展望:AI研究の新たな地平線
この研究結果は、LLMの開発と応用に大きな影響を与えそうです。特に:
知識更新の新手法:RAGを活用した効率的な知識更新
学習方法の再考:繰り返しと多様性を重視した学習データの設計
ハイブリッドアプローチ:RAGとFTを組み合わせた新たな手法の開発
AI研究者の皆さん、ワクワクしませんか?
8. まとめ:RAGの時代の到来?
今回の研究は、LLMの知識拡張に関する常識を覆す衝撃的なものでした。RAGの優位性が示されたことで、今後のAI開発の方向性が大きく変わる可能性があります。
ただし、これで全てが解決したわけではありません。RAGの不安定性や、より大規模なモデルでの検証など、課題はまだまだあります。
AIの世界は日々進化しています。今回の研究結果が、どのような新たなイノベーションを生み出すのか、今から楽しみですね。
みなさんは、この研究結果をどう思いますか?RAGの時代は本当に来るのでしょうか?コメント欄で皆さんの意見を聞かせてください!
それでは、次回のブログでまたお会いしましょう。AIの世界の冒険は、まだまだ続きます!