
【論文瞬読】画像で時系列予測?驚きの新手法VISIONTSが示す AIの可能性

こんにちは!株式会社AI Nestです。今日は、時系列予測の世界に革命を起こす可能性のある最新の研究について紹介します。その名も「VISIONTS」。なんと、自然画像を使って時系列データを予測するという、斬新なアプローチなんです。これ、本当にすごいんですよ。それでは、詳しく見ていきましょう!
タイトル:VisionTS: Visual Masked Autoencoders Are Free-Lunch Zero-Shot Time Series Forecasters
URL:https://arxiv.org/abs/2408.17253
所属:Zhejiang University、State Street Technology (Zhejiang) Ltd、Salesforce Research Asia
著者:Mouxiang Chen, Lefei Shen, Zhuo Li, Xiaoyun Joy Wang, Jianling Sun, Chenghao Liu
1. VISIONTSって何?
VISIONTSは、時系列予測(Time Series Forecasting, TSF)のための新しい基盤モデルです。従来の手法とは全く異なり、自然画像を用いてTSFモデルを構築します。
具体的には、ImageNetデータセットで事前学習された視覚マスク自己エンコーダ(Masked Autoencoder, MAE)を活用し、TSFタスクを画像再構成タスクとして再定式化しています。つまり、時系列データを画像に変換し、その画像の一部をMAEに予測させることで、未来の値を予測するわけです。
これ、一見すると「えっ、そんなことできるの?」と思いますよね。でも、実際にやってみたら驚くべき結果が得られたんです。
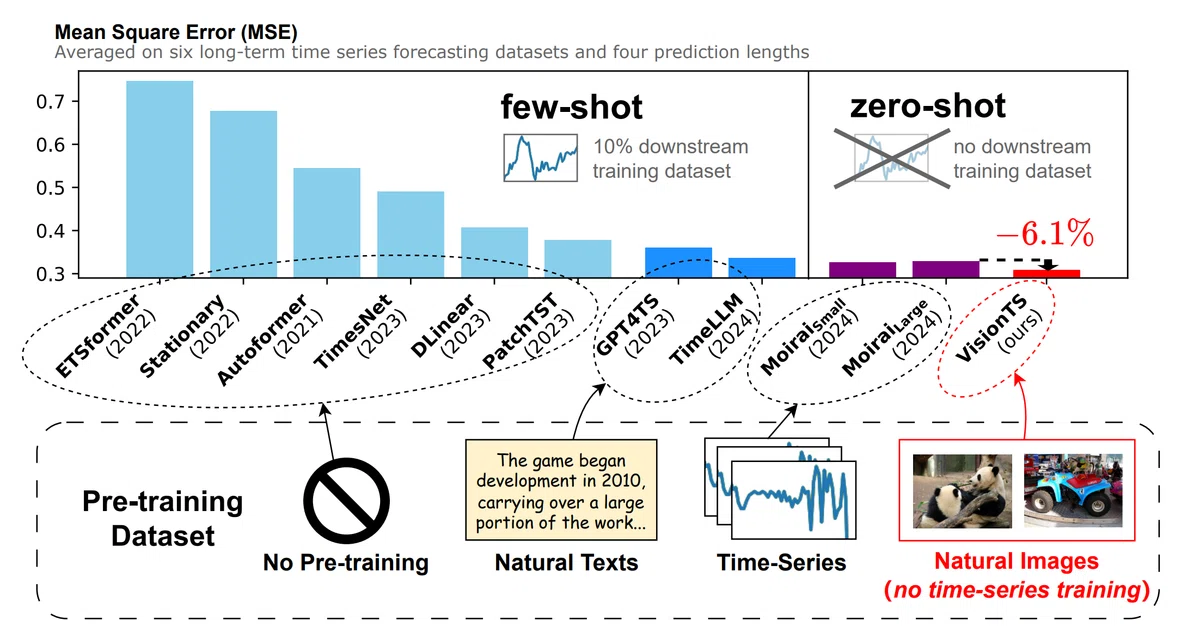
図1は、VISIONTSと他のモデルの長期予測性能を比較したものです。なんと、VISIONTSはゼロショット(追加学習なし)の設定で、事前学習済みの最大のモデルMOIRAI Largeを上回る性能を示しているんです!これ、本当にすごいことなんですよ。
2. なぜ画像を使うの?
ここで疑問に思うのは、「なぜわざわざ画像を使うの?」ということでしょう。実は、時系列データと画像には意外な共通点があるんです:
連続性:画像のピクセル値も時系列データも、連続的な値を持ちます。
冗長性:両者とも、近接するデータポイント間に強い相関があります。
特徴の類似性:周期性やトレンドなど、時系列データの特徴は画像にも見られます。

図2は、ImageNetデータセットの画像例です。よく見ると、この画像のピクセル配列が時系列データによく見られる特徴(トレンド、季節性、定常性など)を示していることがわかります。これらの類似性により、画像処理の技術を時系列データに応用できる可能性が生まれるわけです。
3. VISIONTSのすごいところ
VISIONTSの本当にすごいところは、その性能です。先ほどの図1でも示しましたが、追加の学習なしで既存のTSF基盤モデルと同等かそれ以上の性能を達成しているんです!

図4は、Monashベンチマークでの性能比較を示しています。VISIONTSは、個別にトレーニングされたモデルの多くを上回り、事前学習済みのMOIRAI Smallに次ぐ2位の性能を示しています。これは、画像ベースのアプローチが時系列予測に対して強力な汎化能力を持つことを示唆しています。
4. 技術的な仕組み
では、VISIONTSはどのように動作するのでしょうか?

図3は、VISIONTSのアーキテクチャを示しています。簡単に説明すると:
時系列データを周期性に基づいてセグメント化し、2D画像に変換します(①と②)。
画像の一部(未来に相当する部分)をマスクします(③)。
MAEにマスクされた部分を予測させます(④)。
予測結果を時系列データに戻します(⑤)。
この方法により、時系列の特徴を空間的な特徴として捉えることができ、画像処理の強力な技術を時系列予測に応用できるんです。
5. 驚きの発見:モデルサイズと性能の関係
研究の中で興味深い発見がありました。それは、必ずしも大きなモデルが良い性能を示すわけではないということです。

表2は、異なるサイズのMAEモデル(Base:112M、Large:330M、Huge:657M)の性能を比較したものです。驚くべきことに、最も小さいBaseモデルが全体的に最も良い性能を示しています。
これは、大きなモデルが画像特有の特徴に過剰適合してしまい、時系列データへの転移可能性が低下する可能性があるためだと推測されています。この発見は、「より大きいモデルが常に better」という一般的な認識に一石を投じるものですね。
6. VISIONTSの限界と将来の展望
もちろん、VISIONTSにも限界はあります。現在の手法では単変量予測に限定されており、多変量予測への拡張が今後の課題となっています。
また、研究者たちは、より高度な画像インペインティングタスクとしてTSFを再定式化する可能性も示唆しています。例えば、拡散モデルを使用することで、さらに精度の高い予測が可能になるかもしれません。
7. まとめ:VISIONTSが示す AI の可能性
VISIONTSは、単に新しいTSF手法を提案しただけではありません。この研究は、異なる分野間での知識や技術の転用の可能性を示唆しているんです。
コンピュータビジョンと時系列分析という、一見関係なさそうな分野を橋渡しすることで、驚くべき結果を生み出しました。これは、AI研究全体にとって大きな示唆を与えています。
今後、このようなクロスドメインの研究がさらに進むことで、AIの可能性がますます広がっていくことでしょう。VISIONTSは、その先駆けとなる重要な研究だと言えるでしょう。
みなさんは、この研究を聞いてどう思いましたか?AIの未来に、どんな可能性を感じましたか?ぜひ、コメント欄で教えてくださいね!
それでは、次回のブログでまたお会いしましょう。AI の世界の驚きはまだまだ続きます!