
【論文瞬読】AIEフレームワーク: 大規模言語モデルを用いたハイブリッド長文書からの情報抽出の最前線

こんにちは!株式会社AI Nestです。
今回は、大規模言語モデル(LLM)を用いて、テキストと表が混在したハイブリッド長文書(HLD)から情報を抽出する新しい手法についてご紹介します。
タイトル:Enabling and Analyzing How to Efficiently Extract Information from Hybrid Long Documents with LLMs
URL:https://arxiv.org/abs/2305.16344
所属:School of Software & Microelectronics, Peking University; Microsoft;
Institute of Software Chinese Academy of Sciences; University of Technology Sydney
著者:Chongjian Yue, Xinrun Xu, Xiaojun Ma, Lun Du, Hengyu Liu, Zhiming Ding, Yanbing Jiang, Shi Han, Dongmei Zhang
HLDからの情報抽出における課題
HLDからの情報抽出には、以下のような課題があります。
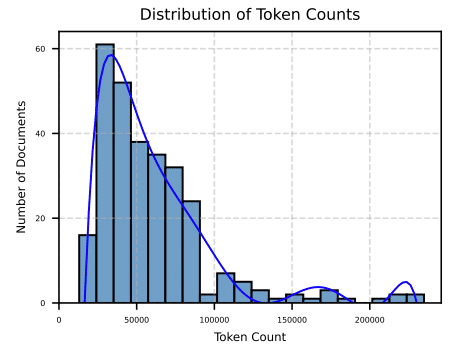
長文書:HLDは非常に長く、LLMの処理限界を超えることがあります。例えば、実験で使用された財務報告書の平均トークン数は59,464であり、GPT-3.5の最大トークン数の14.5倍、GPT-4の1.8倍にもなります。
ハイブリッドコンテンツ:テキストと表が混在しているため、両方を同時に分析する必要があります。同じ情報がテキストと表の両方に異なる形式で記載されていることがあり、正確な情報抽出のためには両方を考慮する必要があります。
表現の曖昧さ:同じ情報が異なる表現で記載されていることがあります。例えば、"Revenue"と"Total Net Sales"は同じ意味を持ちますが、異なる表現が使用されています。
数値の精度:テキストと表で数値の精度が異なることがあります。例えば、テキストでは"$15.3 billion"と記載されていても、表では"$15,338 million"と記載されていることがあります。
AIEフレームワーク
これらの課題を解決するために、研究者たちは自動情報抽出(AIE)フレームワークを提案しました。AIEは以下の4つのモジュールから構成されています。

セグメンテーション:HLDを短いセグメントに分割します。これにより、LLMがHLDを処理できるようになります。セグメンテーションは、テーブルのシリアライゼーション、長い要素の分割、隣接要素のマージの3つのステップから構成されています。
検索:キーワードに関連する最も関連性の高いセグメントを選択します。これにより、不要な情報を除外し、処理速度を向上させることができます。研究者たちは、埋め込みベースの検索戦略を採用しています。
要約:選択されたセグメントから関連情報を要約します。これにより、関連情報を抽出し、圧縮することができます。研究者たちは、リファイン戦略とマップリデュース戦略の2つの要約戦略を比較しました。
抽出:要約からキーワードに対応する値を抽出します。これにより、不要な情報を除外し、ダウンストリームタスクの精度と効率を向上させることができます。

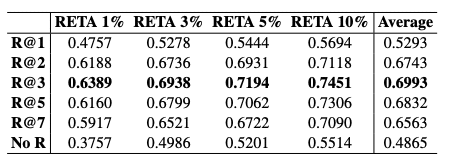

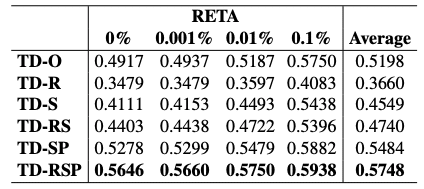
研究者たちは、各モジュールの最適な実装方法について詳細な分析を行いました。例えば、テーブルのシリアライゼーションフォーマットの比較では、PLAINとCSVフォーマットがXMLとHTMLフォーマットよりも優れていることが示されました。また、検索セグメント数の影響では、3つのセグメントを検索するのが最適であることが示されました。要約戦略の比較では、リファイン戦略がマップリデュース戦略よりも精度が高いことが示されました。数値精度の向上手法では、直接的な精度要件と精度を含む入出力例を組み合わせることが最も効果的であることが示されました。
AIEの有効性検証
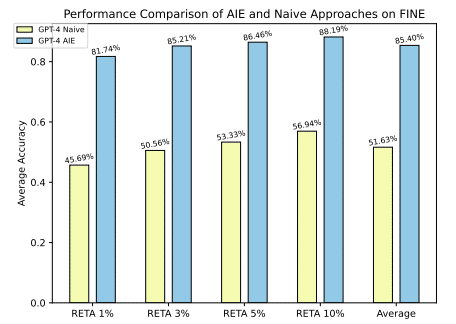
AIEの有効性を検証するために、研究者たちは財務報告書、ウィキペディア、科学論文の3つのドメインで実験を行いました。結果として、AIEはLLMのHLD処理能力を大幅に向上させることが示されました。例えば、財務報告書のドメインでは、AIEを使用することで、平均精度が69.93%から85.40%に向上しました。
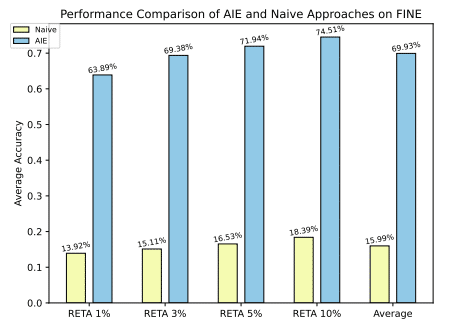

さらに、AIEのLLMに対する適応性や曖昧さ処理能力なども追加実験により確認されています。例えば、GPT-4を使用した場合でも、AIEはナイーブな戦略よりも優れた性能を示しました。また、キーワードの曖昧さを処理する能力についても、AIEはナイーブな手法よりも優れていることが示されました。

まとめと感想
このペーパーは、LLMを用いたHLDからの情報抽出において、非常に有用な知見を提供していると感じました。AIEフレームワークは、HLD処理の課題を体系的に解決するアプローチであり、各モジュールの詳細な分析は、実装する上で参考になります。
特に、テーブルのシリアライゼーションフォーマットの比較や、数値精度の向上手法などは、実用上重要な示唆を与えてくれます。PLAINやCSVフォーマットを使用することで、テーブルの分割を減らし、完全なセマンティック情報を捉えることができます。また、直接的な精度要件と精度を含む入出力例を組み合わせることで、数値精度を向上させることができます。
また、複数のドメインでの実験により、AIEの汎用性の高さも示されました。財務報告書、ウィキペディア、科学論文という異なるドメインでも、AIEは一貫して優れた性能を示しています。これは、AIEが様々な分野での応用可能性を持っていることを示唆しています。
一方で、AIEにはいくつかの限界点も存在します。例えば、モデルの能力については、式の推論や抽象の生成、キーワード抽出などの他の側面での評価がまだ不十分です。また、画像や図表などの他の種類のコンテンツを含むマルチモーダルデータへの対応も課題として挙げられています。さらに、GPT-3.5やGPT-4を使用するためのコストの制約もあります。これらの課題に対するさらなる研究が期待されます。
全体として、このペーパーはLLMを用いたHLDからの情報抽出に関する重要な貢献であり、関連分野の研究者や実務者にとって有益な知見を提供していると思います。AIEは、HLDからの情報抽出における新しい可能性を切り開くアプローチであり、今後の更なる発展が期待されますね。
以上で、テックブログを終えたいと思います!この内容が少しでもみなさんのお役に立てれば幸いです。