
「プログラミング」も資産運用もしたことないわたしがAIで株価を予測するー9ー 改善しました!

こんにちは。「プログラミング」も資産運用もしたことないわたしがAIで株価を予測するの第9弾です。
さて、前回、1日後の予測結果を実際に動かしてみて、記事数が増えると、単語数が変化するので精度が下がるという問題点に直面しました。
そもそも、Fingerprintというのは、固定長でないと取り扱いが非常に難しいですが、今のやり方だと、Fingerprintの長さが変化していってしまうという難点がずっと心の中で指摘さていたのを無視しながらやってきていて……このへんでそれをなんとかしたいと思います。
クラスタリング
よく、同じ趣味を持った人のことを○○クラスタと言ったり○○徒と言ったりします。集団を共通(っぽいもの)の組に分けるのがクラスタリングです。距離を使って分ける方法にk-means法があります。
今回の1000記事の中には、予測に向く記事と、たいして予測に向かない記事があると考えられます。そういうものをクラスタリングで分けてみようと思いつきました。前回の研究で、400記事くらいがちょうど全体の予測精度があがるということで、
①400記事を適度に選んで、学習させる。
②選んだ記事をk-means法で5つのクラスタに分ける。
③それぞれのモデルで、一番R2が大きかったクラスタを選択して、その平均を調べる→どのワードが予測に重要かを知ることができる!
てことで、早速実践です。
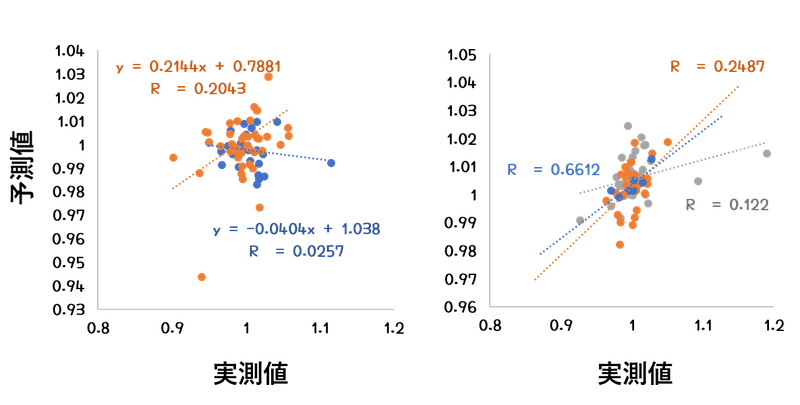
左のセットではほぼ2つのクラスタに分類されまして、オレンジのクラスタが0.2を超えてきました。一方で、青のクラスタは傾きがマイナスになってしまいました。
右のセットでは3つのクラスタに分かれました。概ね良好だったのですが、その中でも青のクラスタは0.66という高いR2を生み出しました。
さて、これらのクラスタにはどんな言葉が多く使われているんでしょうか。左のオレンジのクラスタに多く使われていた言葉ベスト5は
する/発表/月/なる/できる
右の青のクラスタに多く使われていた言葉ベスト5は
する/発表/月/なる/開発
とほぼ一致しました。
これらの言葉を事前に一定数決めて、それを含むか含まないかというので実践すれば、Fingerprintの長さを固定長にできそうです。ということで、このようなセットを8セット行って、暫定的に315ワードを使うことにしました。
その単語のみで、1000記事を評価したのがこちらです。
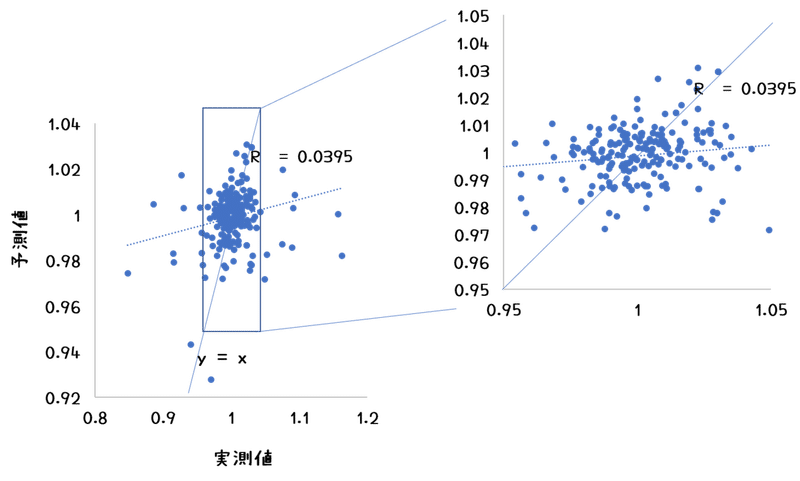
あ、あれ、0.04か……せめてy=x上に載っている点の数が多いかなとおもって拡大してみたものの……
それもそのはず、もとの1000記事には予測に向かないクラスタが存在することを前提にしているので、そういうものを抜かないといけないのでした。
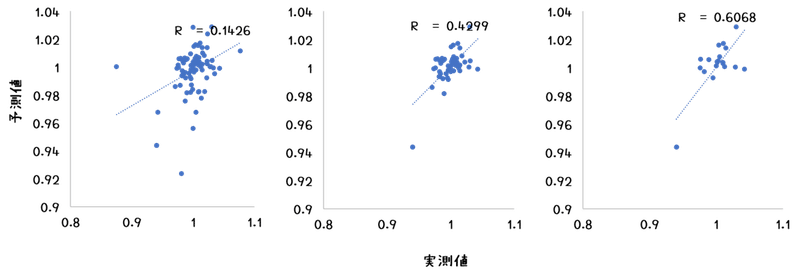
てことで、1000記事を3つのクラスタに分けて、再度検討です。
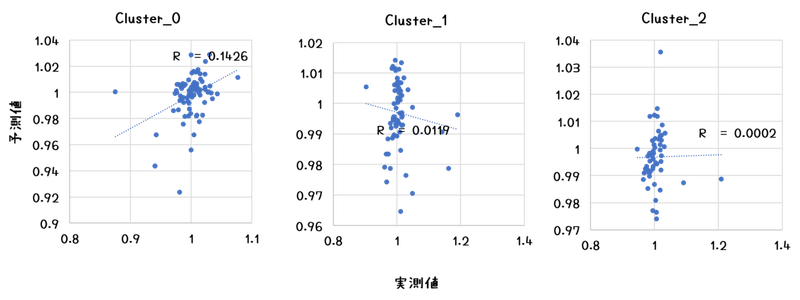
とりあえず、Cluster_0で0.14となりました。グラフから察するに上がる/上がらないの2値予測にすればもっと精度は高められそうです。さらに、この予測方法では、それがどれくらい信頼に値する予測なのかを示す数値も同時に計算されてくるので、
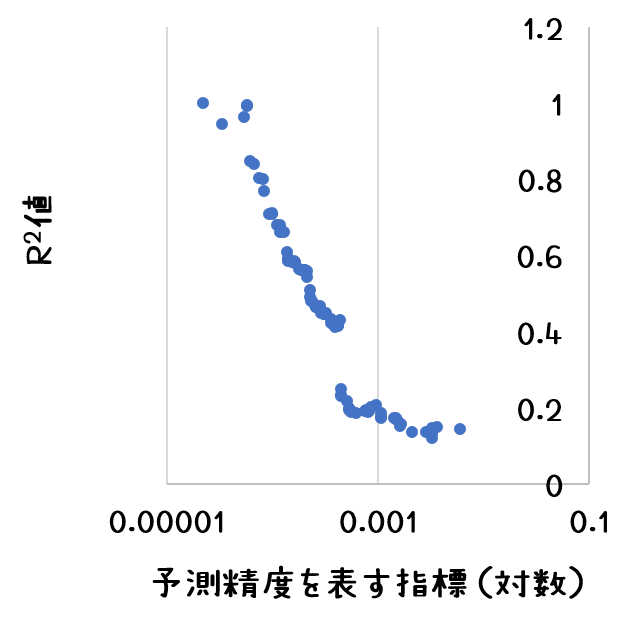
これを元に、カットオフ値を設定すればR2を(意図的にですが)挙げていくことも可能だろうと思います。
つづく
この記事が気に入ったらサポートをしてみませんか?