
特集:日本企業のコンピュータサイエンス研究開発の2023年を総括する(後編) #CCSE2023

3回に渡ってお送りしたCCSE2023特集、最後は Stability AI・日本代表のJerry Chiさんの講演後半、特に研究開発体制と会場からの質疑応答に価値があります。
日本企業のコンピュータサイエンス研究開発の2023年を総括する要素がたくさんありますので年末年始にごゆっくりお読いただければ幸いです。
研究開発体制をどうしているか
世界中に研究者・開発者がいます。とにかく優秀な人がどこにいても採用したい。アメリカ、北米にたくさんいますよね。ヨーロッパにもたくさんいます。そういう論文の著者とかを見れば、やっぱり北米、ヨーロッパ、中国とかが多いので、そこでエンジニアや研究者を取るのが結構重要です。日本では、応用研究というエンジニアリングをやっております。
じゃあ、北米とかヨーロッパにすごい研究者がたくさんいるんだったら、じゃあ、どうして日本の技術者チームを作る必要があるかかっていうと、日本の文化や言語にそのAIモデルを考えさせるっていうのが結構重要で、それでま日本語話者とか日本在住、日本の企業がそのまま適切なモデルを選んでアメリカバイアスのないようなモデルをもっと有用に使えるかなと思います。
じゃあ日本人は日本のためにいるかっていうと、そうでもなくて、実はそれ以外のもっと大きいミッションがあるんですね。弊社の創業者の Emad Mostaque が言ってるのは、「各国、各文化、各個人のためのAI」を作る必要がある。ダイバーシティですね。世界中のいろんな多様な価値観、多様な文化のためのモデルを作る必要があって。もし、例えば「世界中のAIシステムが全てサンフランシスコ在住の三十五歳の白人男性の価値観を持ってたら」、それは「ディストピア」っていうんですよね。

それはもう、いろんな世界の文化か、一つの文化とか、一つの価値観に圧倒されてしまう。そうなったら僕は結構悲しいと思いますね。なので日本のためにそれをやるのも重要ですし、日本での、ローカライズのエンジニアリングだとか、応用研究とかそういうノウハウを蓄積して、それを他の国とか他の文化、他の言語へ、そういうノウハウを応用することができます。
例えば、英語の指示データを日本語に機械翻訳した時に、色々、注意点とか問題とかが起こったりするので、じゃあそういう問題にどう対応すべきか、どう後処理すればいいか。例えば、LLMのトークナイザーを、日本語以外の他の言語、英語以外の言語に拡張させる時にどういう風にすればいいか。
その新しいトークンのエンベディングをどうすればいいか。日本人が論文をあさって、中国の研究者のGitHubとかブログとか見て、いろいろ論文とか、自分でブレストして考えて。
じゃあ、実験してどういうトークナイザーがいいかっていう実験をして、ノウハウを得るんですね。で、それを例えばスペイン語とかドイツ語にそのまま適用できるかっていうと、ちょっと違うかもしれないんですけれども、弊社のヨーロッパチームが英語から日本語での転移学習を参考に「スペイン語モデルを作る時にそれを参考にしましょう」っていうのが結構ありますね。
「Have fun:楽しまないともったいないよね」
先ほどもちょっと申し上げましたけれども、日本チームの技術者も、主に応用研究とエンジニアリングの仕事をしていて、基礎研究はやっていないです。欧米の基礎研究の方が強いっていうのもあります。なので、例えば海外チームは有名な学会に論文を出したりするんですけど、日本チームは応用なので、あまり論文書いたりしないんですね。まだ自由度が結構高いので、例えば本社から「これ、やっちゃダメ」とか「絶対こうしろ」っていうのはあんまりなくて。意見はもらいますけれども、結局日本チームが日本のマーケットニーズを見て、自分たちでベースで考えて、何をどうすればいいかを考えていってみる。チームのサイドで、お互い議論して考えた価値観の一つは、「Have fun」ですね。楽しみましょう。せっかくこんなに面白い生成AIっていう技術の業界にいることによって、「楽しまないともったいないよね」っていう。実際すごく楽しい生成AIのアプリとかモデルもたくさんあるので、これはできるかなと。
どういうロールがあるか
どういうロールがあるかっていうと、機械学習的はもちろんですね。あとデータセット。データのスクーリーニングとか前処理、後処理、クリーニングとか。危ないものを省くとか品質悪いものを省くとか。あとデータのフィルタリングにもAIを使う。そこに重要な課題があるかなと思います。あと、お客さんの結果がまだ弊社にはまだ少ないんですけれども。ソリューションエンジニアですね。そういう機械学習者の専門性の高いスキルエンジニアとか。それから、ジェネレーティブメディアエンジニア。いろんな画像とか動画をうまくそのお客さんのニーズを合わせてなんか作れる人とか。ロールは流動的で、例えば、例えば十年前だったら、画像処理の人がいきなり自然言語の処理に移ろうとすれば、多分難しかったんですけれども。今のこの時代だとTransformerとかPyTorchなどディープラーニングの基礎があれば結構、言語モデルやってた人が画像生成モデルをやり始めたり、スピーチモデルやり始めたり。そういうモダリティ間の流動性はあります。
モデルを開発してた人がそのお客さんのアンケートを手伝うとか、まあ嫌だったら、させないですけど、そういうのもあります。正直新しいスタートアップで、カオスも結構あるので。ちょっと不安なところはあるんですけれども、そういう色々に対応できるチームメンバーでチームを構成してて、この業界ほんとに変化がとても激しいので、臨機応変的に対応できる組織を作っています。
海外の研究開発メンバーとの連携がすごく重要で。海外の欧米と中国にもいるアルゴリズム、どのアルゴリズムだったらうまくいくのかとか。いろんな実験の中でどれを先にやればいいのか?GPUカを使えばいいのか?例えば訓練がちょっと不安定だけど、どうすればいいかみたいな。結構色々Slackとかミーティングとかで相談したりしてて。そういうミーティングメモなんかもAIツールで自動要約してSlackで共有するとかなので、そういうのは結構海外チームもすごい。日本チームのサポートをすごいいつも積極的にやってくれてるので、それはすごく助かりますね。
全体的アプローチはどうなのか?何をどうやるか、どうやって決めるの?ってところですが。普通の会社は、例えばまず、特定のお客さんの問題があって、そこから逆算して、じゃあこういうことが必要で、そこから逆算して、こういう機械学習のモデルが必要です……みたいな。そういう感じが多分ほとんどの会社ですが、弊社はそれとちょっとギャップがあって、ともかくまずは世界の一流の技術者と研究者、エンジニアを採用する。裁量権と自由をあげて、彼らがすごい人たちだから、きっとすごいものを作るんだろうっていう方針。それで、若干カオスとなることもありますけれども。そういうちょっと特別な会社です。

オープンソースコミュニティ、例えば EleutherAI とか discord とかHuggingFaceとか GitHubとか。いろんなそのオープンソースコミュニティで活躍してる人とちょっと話し始めて、「すごい面白いモデルとか面白いことやってるから、弊社に入れないか」みたいな。「入社して、一緒にプロジェクト入れませんか?」みたいな。そういうのもよくあります。すごい人たちがいくつかチームを作って、画像生成担当するチームとか、例えばヨーロッパの言語の言語モデルを担当するチームとか。そういういくつかのチームに分かれて、それぞれがどういうモデルを作るかは、それぞれのチームが決めるんですけれども、社長の意見もあります。で、色々論文漁って。海外チームはアルリズムの発明とかもあるんですけれども、日本チームはどっちかっていうと、そのまま論文読んで僕とかも読んで海外チームがやってることも参考にして「じゃあ日本に役立ちそうなモデルは」「何をどう作れば役立ちそうなのか」っていうのを見て決めるんですね。で、実験をたくさんします。データ中心。長期プランはあんまり作りません。この業界は変化が激しすぎるので、例えば「一年後はこういうモデルを出来上がるようにしたいです」っていうのをあんまり言わない。例えば来月とか再来月にどういうモデルがあるといいかなっていうそういうタイムラインなんで。それのいいところも悪いところもあります。そのビジネスニーズも重要ですけれども、それに左右されすぎないように、やっぱり研究開発の自由度を保つようにしたいっていう会社ですね。

先週、NeurIPS、確か世界最大のAI会議ですけれども、多分一万数千人参加したんですけれども。僕と日本メンバーももう一人、そのアメリカに行って楽しく食事したり、有名なAIの人に出会ったり。結構それで海外チームがどういう研究しているか、今後どう連携すればいいかっていうのが深まりましたね。
オープンソース・オープンモデルコミュニティへの貢献

写真:Weights & Biases のLLM評価勉強会にて
オープンソースコミュニティ、オープンモデルコミュニティ、つまりソースはオープンじゃないけど、モデル自体はオープンなものもあります。そのコミュニティに貢献したいと思っていて。
例えばLLMに関しては その「日本lm-evaluation-harness」とか MT-Bench っていう、LLMの評価手法は、弊社の日本チームが開発していて、これが結構いろんな会社とかで使われたりしてます。
あとは、そういうコミュニティ、例えば大学に所属する人とか、個人とか、そういうオンラインコミュニティにGPUを無料で貸し出したりしてて、そういう面白い生成モデルは是非サポートしたいと思っております。

結構いろんなイベントの登壇したり、スタートアップ支援プログラム、技術者向けの勉強会とかもやったりしてます。

ソリューションエンジニアがメインですけれども、こういうメジャーな日本の企業のためのプロジェクトもやってます。こういうマーケティングとかプロモーション。
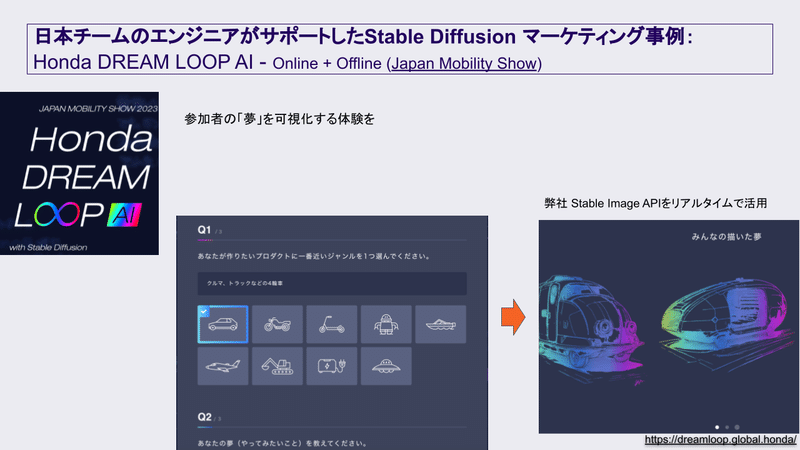

ホンダとかビールのブランドをかっこよくするような案件とかもあります。結構メディア系とかプロマーケティング系が多いですね。
弊社はオープンでマルチモーダルでグローバル国内外で研究開発にやってる会社です。採用中なのでもしご興味がある方がいらっしゃったら、ぜひ私でもどうぞご連絡ください。キャリアページがあります。


生成AIっていう技術の進化が非常に楽しくて面白くて、もう毎日わくわくしてます。ぜひこのコミュニティに参加していただければと思います。
ありがとうございました。
(会場拍手)
質疑応答より

質問: モデルをオープンにする選択はなぜか?どうやって収益するのか。
Stability AIがモデルをオープンにするという選択について、それによって会社がどのように成長していくのか?
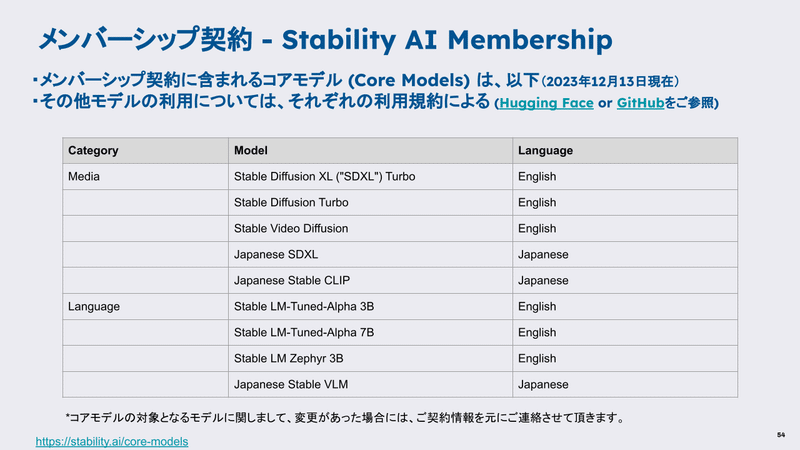
Jerry Chi:ビジネスモデルに関して、オープンモデルの採用によってビジネスの存続性についてよく質問される。最近メンバーシッププログラムとサブスクリプションを導入した。これによりモデルはメンバーシップサブスクリプションの一部として提供される。ライセンスと利用に関して、個人や非商用利用に関しては無料で利用可能で、小規模の企業や個人が商用利用する場合は月額20ドルの料金が設定されています。また、大企業が商用利用する場合は個別の相談が必要であり、多様なモデルを商業利用することが可能です。その他の収益モデルについてはGPUの再販やAPIの提供、AI技術の利用など、さまざまな収益源がある。メンバーシッププランが主要な収益モデルになる。
https://ja.stability.ai/blog/stability-ai-membership


質問: 日本が最初の対象国である理由は?
Jerry Chi: 日本への愛着。Stability AIのスタッフの中には日本文化、特にアニメやゲームを好む人が多い。経済的・地政学的理由。日本は世界第三位のGDPを持つ経済大国で、中国と比べて地政学的に取り組みやすい市場である。クリエイティブ産業への適合性。日本にはクリエイティブな才能や会社が多く、Stability AIのメディア業界やクリエイター向けAIモデルに適している。
質問者からは日本は人口減少に直面しており、AIの導入による生産性の向上が重要。というディスカッションもありました。
Stability AIがスタートアップや大企業向けに支援プログラムを提供していることに言及。特に、「フォトグラファーAI」というサービスについて紹介。このサービスは、Stable Diffusion を改造し、より使いやすいUIを提供することで、商品写真の生成を助けるものです。最初は主に技術に詳しいユーザー(ギーク)のみがこれらのツールを活用できる状況だったが、時間が経つにつれて、より多くの非技術者や一般の大衆に向けた使いやすいツールへと進化していくことを指摘。これは、モデルの理解がコミュニティ内で広がり、初期の使いにくいツールからよりアクセスしやすい形へと変化していく過程。
質問: 企業におけるプロダクト開発と、モデル公開のタイミングや決定軸について。回せば回すほど性能が上がっていくとは思うがリリースする判断はどうしている?
Jerry Chiの回答: モデル開発の課題。モデルの作成、実験、選択、リリースのタイミングが常に議論される課題。リリース戦略としてはリーダーボードでの位置取りという考え方もあるが、長期的な視点でのリリースが重要。性能と安全性視点。性能は重要だが、安全性の考慮も強まり、レッドチーミングなどの出力確認が必要。たとえば安全性を考慮し、グローバルセキュリティ担当者も採用されている。これにより安全なモデルのリリースに向けて取り組みがなされている。モデルリリースは複雑な問題で、多くの要因を考慮する必要がある。

質問: Stability AIのモデルの性能において、アルゴリズム、データ量、データ品質のうち、どれが最も影響力があるか。
Jerry Chi: いろいろ複雑だがまずはアルゴリズムの重要性。 アルゴリズムによる「魔法的な進化」がある。例えば、Latent Diffusion Modelは画像処理において効率的な進歩を示している。敵対的拡散蒸留(ADD)、この新しいアルゴリズムは高速で高品質な画像生成を可能にし、かつ高速でも品質維持ができている重要なアルゴリズム。続いてデータの役割。モデルの構造を変えることも一つの方法だが、特定のデータを集め、クリーニングすることで最良の効果が得られることもある。つまりは総合的な視点が重要で、状況によってアルゴリズム、データ量、データ品質のそれぞれが重要になる可能性がある。
質問: ダイバーシティに関して、少数言語やマイナーな自然言語のデジタルデータの取り扱いと、それらの言語に対するアプローチをお聞きしたい。
Jerry Chi: 弊社の Emadは全言語の取り組みの意欲をみせている。会社の目標としてはすべての国と言語に対応すること。しかし現状の制約として、すべての言語をすぐにカバーすることは現実的ではない。マイナー言語への対応、 例えばアイスランド語など、現在は取り組んでいない言語もある。圧倒的にデータ量が少ない言語にどう適応するかについて、シンセティックデータの生成: 既存のデータから新しい言語のデータを生成する実験などもある。転移学習の利用によって、他の言語のモデルから学習して、データが少ない言語に適用するなど。他社はペアデータの重要性に注目し、既存のペアデータがなくても、翻訳AIを作成できる方法の研究などもある。英語での世界の知識を他の言語に適用するアプローチもある。
質問: マーケティング観点からのご質問
Stable Diffusion XL のモデルを使わせていただいて、広告クリエイティブの画像にこう生成をして提案するっていうものをお客さんにしているんですけども、このマーケットって結構そういうところに保守的なところがあり、技術的には素晴らしいけども、こうまだそこの段階ではないっていう返答をもらうことがかなり多いです。で、アメリカだったりとか、そういった米国のマーケットで、なんかすごく活用されている事例とか、アジアのところで活用されている事例はあれば教えていただけると幸いです。
Jerry Chi: そうですね。海外でも日本でもそういう事例が色々増えてますね。例えばアメリカで有名なのはコカコーラのテレビCM。これはたぶん Stable Diffusion とか OpenAI も使ったと思いますけれども。そういうメジャーなブランドがどんどん活用し始めてるんですね。ちょっとまだ生成AI自体になんか抵抗があるとか。Stable Diffusionのデータセットがどうなの?って、広告主からちょっと躊躇するケースがあるんですけれども。かなり今はいいトレンドだと思いますね。一年前になんかありえなかったとか、絶対炎上するだろうからやめるっていうことを、今もうできるようになってて。
例えばアサヒビールさんもホンダさんも、おおやけに「Stable Diffusion」って書いてくれているのですね。(他にも多分 Stable Diffusion が使われた例もあったりするのですけども)、ただ「AIを使いました」っていう言い方をしてるんですね。ちょっと不透明性で、炎上を抑えるみたいな戦略ですけれども。時間が経つにつれて、皆さんがコミュニティでうまく、情報を説明すれば、例えば Stable Diffusion のそのデータセットは「オプトアウト」をすごく頑張ってます。
危ない画像のフィルタリングアウトをすごく頑張ってます。なので、そういう、「学習されたくないアーティスト」がいれば、「オプトアウトすれば学習されません」みたいなことをま説明すれば、そういう行動するし、より安心して使えるかなと思います。
質問: アニメーションや漫画のようなコンテンツの生成において、単純なプロンプト入力だけでは期待通りの結果が得られない場合があるか。
Jerry Chi: Stable Diffusion XLのアップデートでは、よりシンプルなプロンプトでも美しい画像を生成できるようになっている。MidJourneyなど他社のモデルも、ほとんどの入力で綺麗な画像を出力するファインチューニングを施している。しかし、これによる多様性の損失もあるため、ユースケースによっては難しい判断が必要。アルゴリズムやデータの選び方、集め方によっても変わり、テキストと画像のペアデータを作る際にキャプションを拡張することや、プロンプトの自動拡張も可能。これらの手法を組み合わせることで、多くのユーザーにとって使いやすくなると考えられる。

質問: ユーザーが意図しない結果、特にクリエイティブな分野でのSNSや予期せぬ出力についての考え方。
Jerry Chi: クリエイティブ分野では、予期せぬ結果が新しいアイデアやSNSでの共有を刺激することがある。プロンプトの自動拡張や、パラメータの調整を通じて多様な出力が得られ、これがクリエイティビティに寄与する。さまざまなモデルのバージョンやLoRAなどの従来は意図されなかったスタイルや内容の画像を生成し、新たな表現を探求していくことができる。
質問: ギーク向けのおもちゃとしてのAIの重要性、学習方法の革新、モデルの拡張、及び技術コミュニティ内での知見の交換について。
Jerry Chi: 各チームや個人が自由に情報を交換し、ディスコードやRedditのようなプラットフォームでアイデアが共有されている。研究者でなくとも、熱心なユーザーが新しい使い方やモデルの改良を発見しており、そのようなコミュニティでのアイデアや効果が豊富。弊社はこれらの情報を参考にし、インターネット上のハッカーのような人々からの斬新なアイデアやGitHub上の公開作品も注目している。そのような人々にアプローチし、協力を提案することもある。
質問: プロンプトは複雑さが増している傾向なのか、今後の方向性について。
Jerry Chi: 現在のトレンドは、プロンプトがより簡単になっていくこと。多くのユーザーにとって使いやすさを向上させるため、プロンプトは簡素化されている。自動プロンプト拡張やユーザー体験の改善が進んでいるが、複雑なプロンプトを好むユーザー向けの選択肢も残る。例えば、チャットGPTやDALL-E 3では、ユーザーが簡単なプロンプトを入力し、出力を調整することが可能。しかし、より専門的な職人的な使用を望むユーザーには、複雑なプロンプトの選択肢も提供されることも重要なのではないか。
まとめ:
3回に渡ってお送りしたCCSE2023特集、最後は Stability AI・日本代表のJerry Chiさんの講演後半と、会場からの質疑応答をお送りしました。
日本企業のコンピュータサイエンス研究開発の2023年を総括する要素がたくさん読み取れたようであれば幸いです。
謝辞:資料提供および内容確認にご協力いただいたJerry ChiさんおよびStability AI Japan各位に御礼申し上げます。
メンバーシップ向けExtra
今回の講演の取材用音源をダウンロード可能です。
この記事が気に入ったらサポートをしてみませんか?