
AI画像のポーズを自在にコントロール!『OPENPOSE』が結構凄かった

こんにちは。Automatic1111のアップデートでControlNetが実装され、各種拡張機能が登場しております。その中でも被写体のポーズをコントロールできる『openpose』が注目されていますが、早速試したところ結構凄かったので取り急ぎ感想をnoteにまとめます。しばらく弄っていましたが、凄い部分と現時点ではまだダメな部分が分かった感じです。
今回のアプデでは他にも以前紹介したdepth2imgや、線画に自動着色を行うCannyなど複数の新機能が登場しています。これはimg2img登場時くらいの革新じゃないでしょーか。
ControlNetとopenposeの導入についてはこちらの記事を参考にさせていただきました↓
では生成物をご覧ください。


ベース用の画像はblnederとDaz3Dで作成しています。御覧の通りベース画像のポーズがAIに検出され、生成物に反映されていますね。現在ある諸々の呪文ノウハウは画像AI黎明期のものであり、技術発展に伴い淘汰されるものだと考えていますが、早くも姿勢系のプロンプトは殆ど不要になったように思います。
私の環境では生成にかかる時間が通常より1.5倍程度になっていますが、これまで良い感じのが出るまで何十枚も生成していたのが、一発でイメージ通りのポーズを出せるようになると思えば、おつりが来るくらいじゃないでしょうか。
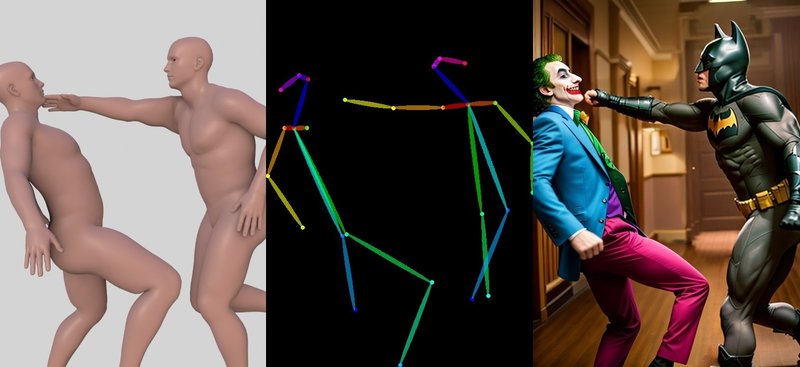

恐らく大勢のユーザーにとってありがたいのは、複数の人物にポーズをとらせることができるようになった点です。このような画像はtext2imgでの生成は難しく、img2imgやinpaintを使ってある程度手作業で作成する必要がありました。これがベース画像とプロンプトのみで生成できるようになったのはかなり大きいです。
『より思い通りの画像を作る!img2img&フォトバッシュ複合ワークフローについて』で紹介していたようなimg2imgでもopenposeは役立ちます。img2imgは繰り返すことでキャラクターの姿勢が徐々に変化していってしまい、低strengthでチマチマ生成と修正を繰り返さなければならずやたら手間がかかっていたのですが、openposeがあれば「被写体のポーズ」は強力に制御されますので、修正したい部分はinpaintのfill生成や高strengh img2imgをバンバンかけてしまえる訳です。
あと人物の顔の向きも検出してくれるので、「完全に横向き」「ちょい斜め向き」みたいな地味に制御が難しかった部分も弄れるようになってきました。これはありがたい。
真面目に良い感じの画像を作るとなるとやはり細部修正は必要になってきますが、体感では作業時間が40分から10分に短縮された感じです。
もっと人物が多かったらどうなるんじゃ?ちょっと増やしてみよう。


あ、ああ~これは凄いわ。というかopenposeはかなり大人数でも認識してくれますね。これとは別になんかの集合写真でも試してみましたが、20人くらい居ても割と認識できました。まぁ解像度や生成精度の問題があるからあまりにも大人数で生成しても実用的じゃないと思うけど。
一方でまだダメな部分もあります。(2023/02/16 分かり辛かったので修正)

openposeの自動認識が最も強いのは、四肢の状態が分かり易い正面立ちポーズです。横向きの寝ポーズや人物の頭が画面下側に来ているようなポーズは、そもそもAIが人体として認識できずボーンが崩壊するか無視されてしまいます。上半身も直線一本のボーンで再現しているので、「被写体がどんな風に体を曲げているか?」も制御できません。被写体が前向きか後ろ向きかはボーンの構造から分かると思うんですが、どうも生成時に前後ろが無視されるケースもあります。

画像からの自動認識ではなく棒人間を直接操作できるopenpose用3Dモデルでも試しましたが、openposeは被写体の姿勢を疑似的に2Dで認識しているので、「手前に向けて曲げられた膝」みたいなものは生成が難しくなります。手前や奥の概念も無いので、ボーン同士が交差しているとどちらが手前にあるのか分からず混乱したりします。人物同士が過度に密着しているようなポーズも狂いますね。
2023/02/26追記
openposeはボーンの姿勢を再現している訳ではなく、「この辺に人体があるからそれっぽく描けよ?」とstable diffusionに指示しているだけです。AIは「ココとココとココに人体があるってことはつまり立ってるポーズだな」と解釈してある程度のポーズを描写することができますが、複雑になってくると混乱して再現が難しくなります。ボーンを無視して人物同士の手足が融合したり、人物の前後が逆になったりするのも「なんとなくこの辺に人体がある」で生成しているからですね。
それからopenposeの精度が向上してもどうしようもないのは、『AIモデルが学習していない姿勢は再現できない』ことです。現在、生成が難しいと言われている変則的なポーズは、そもそもAIモデルが学習していません。人体が大きく傾いているような『寝てるポーズ』はその代表的なものの一つです。

寝ポーズを生成させたところ、被写体が形状崩壊してしまいました。90度傾いているポーズはAIが学習している「人間とはこういう形のもの」という認識からかけ離れているので上手く生成できない訳です。様々なカスタムAIモデルが日々公開されていますが、寝ポーズに対応してるAIモデルは数えるほどしか知らないので、この問題は今後も根強く残るんじゃないか。
2023/02/22追記
LORAによる追加学習で変則的なポーズを再現する方法もありますが、LORAは画風にも影響を及ぼしてきますので、「この絵柄でアクロバティックなポーズをしたい」とかの場合は使用が難しいです。
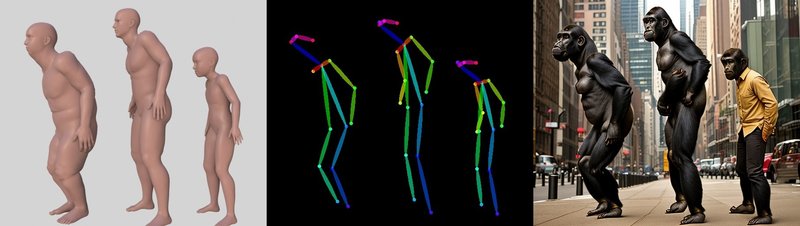
ベース画像に3Dモデルを使用する場合ですが、上記のopenpose用モデルを使うべきかは微妙なところです。AIが生成する人物のバランスはベース画像から検出されたボーンのバランスに依存しますので、生成したい内容に合っている体格のモデルを使用するか、openpose用モデルを調節して使うのが良いでしょう。ゴリラ画像生成するならゴリラ体型。DAZ3Dは基本無料だし体型を詳細に調整できるし人体の可動域を再現しているのでオススメなんじゃ。
あと気付いたんですが、openpose実行時に生成されるボーン画像は計算式のように厳密に取り扱われている訳ではありません。

なので「画像からポーズを取得したいけどどうしてもうまくいかない」という場合はいっそボーン画像自体を手描きしてしまうのも手です。色の配置関係を理解してそれっぽく描く必要はあると思いますが、手描きでも普通に機能します。何かの画像生成させてる途中で微妙に被写体の位置関係を修正したい場合などは、3Dツール弄るよりもボーン画像をササッと改変する方が早いですね。
使用感としては以上です。
イラストレーター的な余談ですが、openposeが平時のイラスト作業でどの程度役に立つか?と考えると、確かに個人的な画像生成遊びにおいては大幅な作業短縮ですが「できないことが出来るようになった」というよりは「できることの作業時間が1/4に短縮された」という印象です。正直なところ、キャラクターに任意のポーズをとらせること自体は、以前から適当手描きベース画像や3Dモデルを使用してのi2iで出来ていました。
そこで先日、AI画像をフルに使用した漫画製作を試みたのですが、『姿勢は制御できても統一性のあるキャラクターを生成できない』『できても色調やライティングに微妙なムラが出る』『細部修正に膨大な手作業が必要になる』ので、結局のところ全体的な作業時間が手描きとあまり変わらないという結論に達してしまったのでした。
今回のopenposeの登場で背景モブをAIで作成したい場合などは今までより素早くできるようになりましたが、メインでの使用はまだまだやり辛いですね。だいたいそんな感じ…。
あと最近技術発展に伴い操作も複雑化してきたのでそろそろ「クリック一発で画像生成!」の頃と比べてユーザー側にも技能が求められる段階に入ってきたんじゃないか。

この記事が気に入ったらサポートをしてみませんか?