
ゼロからはじめるスクリプト言語製作: 要素を基本型で表現する(6日目)

前回までで、ユーザー入力を構造化して、内部表現を文字列化することができるようになった。
例えばユーザー入力として (writeln 1 2 (+ 1 2)) を指定すると、内部表現は以下のように構築される。
1つ目の要素は atomv 型の writeln という値
2つ目の要素は atomv 型の 1 という値
3つ目の要素は atomv 型の 2 という値
4つ目の要素は cell 型のリンクリスト
その1つ目の要素は atomv 型の + という値
その2つ目の要素は atomv 型の 1 という値
その3つ目の要素は atomv 型の 2 という値
この段階では atomv 型には整数型や文字列型といった区別がなく、バリアント型のようにどんな値でも保持できるようになっている。これはメリットとデメリットの両面がありそうで、どちらが正解というものでもないのだが、これから製作しようとしているスクリプト言語を「どのように使ってもらうのか」を想定して、基本型を導入するのかどうかを決めていく必要がある。
筆者は↓以下のように整理した。
ユーザー入力においては、型の明示は不要
内部表現においては、複数ある基本型を使い分ける。基本型には以下の種類がある
文字列型・論理型(ブーリアン)・整数型・浮動小数型・関数型・シンボル(定数名や変数名や関数名)
ユーザー入力を内部表現に置き換える際は、入力規則による単純な推測により型が決定される
今回はこの部分を拡張していこう。
型宣言のこれまで、これから
これまでに Type.cs に宣言してきた型をクラス図にすると↓以下のようになる。
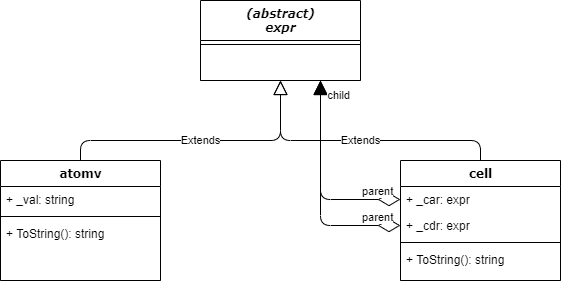
少しおさらいすると、atomv と cell はどちらも expr であり、atomv は1つの値を(_val メンバーに)格納でき、cell は atomv や cell 自身を(_car メンバーに)格納しつつ、「次の要素」を(_cdr メンバーに)連結することができる。
この時点のクラス atomv の実装は、↓以下のようになっている。
public class atomv : expr
{
public atomv(string val) => _val = val;
public override string ToString() => _val.ToString();
public readonly string _val;
}この atomv を派生させて、string 型以外の基本型を格納できるように拡張すると、↓以下のようになった。
public class atomv<T> : expr
{
public atomv(T val) => _val = val;
public override string ToString() => _val.ToString();
public readonly T _val;
}これを利用して、文字列型や整数型などを作っていこう。
基本型の宣言を追加したクラス図は、↓以下のようになる。
※ 赤字は変更箇所
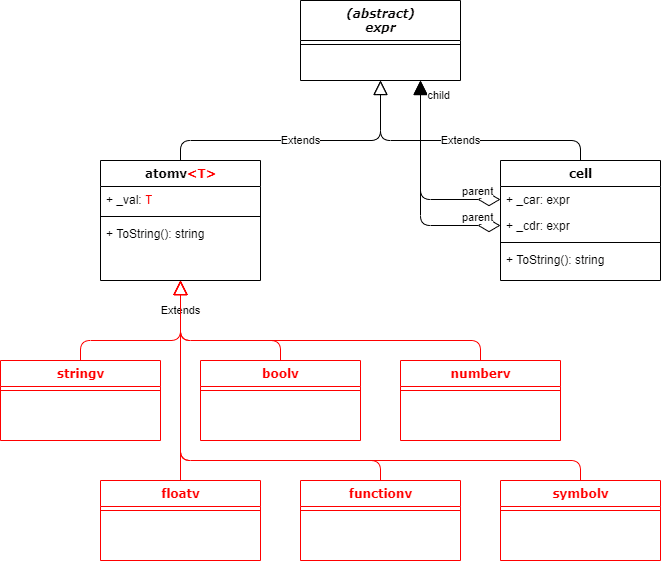
一例として整数型のコードを↓以下に引用した。基本型としての機能は atomv クラスに実装済みなので、最低限のコードで済んでいる。
public class numberv : atomv<long>
{
public numberv(long val) : base(val)
{
}
}読み込んだ要素はどの基本型なのか
> (writeln 1 2 True "Hello,World.")例えば上記のようなユーザー入力があった場合について考えよう(ただし記号「>」はプロンプト)。
入力したユーザーの気分になって考えると、1 の部分と 2 の部分は整数値として解釈してほしい、と思うだろう。
"Hello,World." の部分は文字列値として解釈してほしい、と思うだろう。
True の部分も論理値ということで良いだろう。できれば小文字で true と書いた場合も、同じように解釈してほしいのだろう。
最初の writeln の部分はどうだろうか。これは整数値でも文字列値でも論理値でもない。
いずれにも該当しないものは、おそらく関数名か変数名、つまりスクリプト上で利用できるシンボルとして解釈してほしいものと推測できる。
以上を踏まえて、「読み込んだ要素(文字列)」を基本型に変換する処理を実装してみたのが、↓以下のコードだ。
public class parser
{
public static expr parse(string token)
{
if (token.Equals("null"))
{
return new nil();
}
if (token.StartsWith("\"") && token.EndsWith("\""))
{
return new stringv(token);
}
{
if (bool.TryParse(token, out var val))
{
return new boolv(val);
}
}
{
if (long.TryParse(token, out var val))
{
return new numberv(val);
}
}
{
if (double.TryParse(token, out var val))
{
return new floatv(val);
}
}
return new symbolv(token);
}
}parser.parse() メソッドには6つの return 文があり、それぞれの条件に応じた基本型のインスタンスが呼び出し元に渡されるようになっている。
基本型への変換には TryParse() というクラスメソッドを一部利用している。
bool.TryParse() は True / true / False / false といった入力に対応している。
long.TryParse() は負の整数にも対応している。
double.TryParse() は負の浮動小数はもちろん、指数表記(6.67e-11)や Nan(非数)にも対応している。
parser.parse() を組み込んで、冒頭と同じユーザー入力を与えてみると、↓以下のようになった。
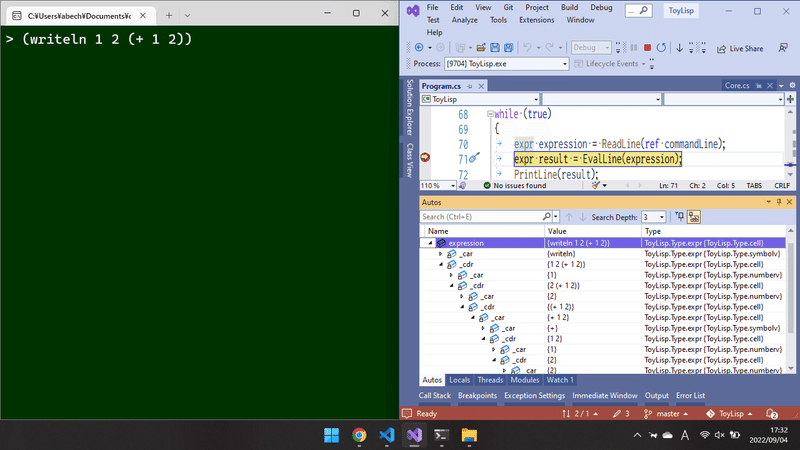
デバッガの Autos 表示を眺めてみると、以下のような構成になっていることが分かる。
1つ目の要素は symbolv 型の writeln という値
2つ目の要素は numberv 型の 1 という値
3つ目の要素は numberv 型の 2 という値
4つ目の要素は cell 型のリンクリスト
その1つ目の要素は symbolv 型の + という値
その2つ目の要素は numberv 型の 1 という値
その3つ目の要素は numberv 型の 2 という値
今日はここまで、おつかれさま。
Program.cs は計 71 行、Type.cs は計 126 行。今後もコンパクトさを維持していきたい。
小さな発見
クラスを継承して実装していくとき、C# では基底クラスにアクセスするためのキーワード base を使うことができる。
public numberv(long val) : base(val)
{
}base キーワードは Java の super と同じように使えるようだ。
引用したコードではコンストラクタ呼び出しに利用しているが、メンバー関数などの呼び出しや、メンバー変数・プロパティのアクセスにも使えるようだ。
もう1つの発見。
out 引数を持つ関数を呼び出すとき、その手前の行で受け取りたい変数を宣言しておく必要はない。TryParse() の呼び出しでは以下のように記述した。
{
if (bool.TryParse(token, out var val))
{
return new boolv(val);
}
}out キーワードと var キーワード(ここでは bool と同義)を一緒に指定することで、「TryParse() が文字列解釈に成功してはじめて、その結果を受け取る」といった書き方ができるようになっている。
コードが1行少なく済むのに加えて、変数の型指定を省略しやすくなる効果があって、ちょっぴりスマートな仕組みだと思った。
この記事が気に入ったらサポートをしてみませんか?