
Google Cloud Data Platform Day #2の感想

まとめ
データの民主化をどうやって行っていくか各企業様で試行錯誤している点が非常に印象的でした。
各企業共通していたのはBQが「速い、安い、マネージド」この観点があるため、利用してるんだなと感じました。その上でいかにして利用ユーザが自分たちの欲しいデータを、自分たちで作れるかの仕組み作りをしていっているのかが、今日のデータ基盤(データ分析基盤)のオリジナリティなのかなと感じました。
リクルートさんのETL基盤を作っている話や、DeNAさんMedjedサービスによる利用者からデータをバルク形式で取り込む話は、基本的にシステムはエンジニアが作るけどそこからの利用(運用)は、利用者も一緒になってやっていこうねとしている点が非常に参考になるなと思いました。使いたくする仕組みを作ることが必要であることを再度痛感しました。
あと、みなさんGKEで頑張っててすげーと思いました。。。コンテナは便利ですもんね。
以下は各セッションのまとめと感想です。
Google Cloud スマート アナリティクス ソリューションの最新情報
データウェアハウス
■BigQuery Reservations(Beta)
スロットの購入、ワークロード管理
Flex:60秒 コスト高
月間:30日 コスト中
年間:365日 コスト低
■メリット
クエリのコストがわかる
迅速なスロット購入と割当
ワークロード管理
未使用スロットの効率的な活用
■整数範囲パーティショニング(GA)
パーティションとクラスタリングを同じ整数範囲のカラムでやると料金が安くなる。
■DML実行回数の無制限化
DML(INSERT, UPDATE, DELETE, MERGE)の実行回数の上限撤廃
DMLのキューイング
同時更新失敗時のリトライ
など
■INFORMATION_SCHEMA
メタデータ:データセット、テーブル、ビュー、ルーティン、ジョブ
組織全体の監査、利用状況のモニタリング
■カラム単位でのデータアクセス制御(Beta)
テーブルないの絡むごとにデータアクセス制御を実施可能
次にデータレイクの新機能と改善です。
■データレイク
- Cloud Dataproc - 自動スケーリング(GA)
- Cloud Dataproc - GKEでのSparkジョブの実行(アルファ)
- BigQuery - GCSのHiveパーティションデータのロード
- BigQuery - BigQuery Storage API(GA)
最後にストリームアナリティクスの新機能と改善です。
■ストリームアナリティクス
例:リアルタイムダッシュボード
例:リアルタイム集計
- Dataflow SQL
SQLでストリーミングまたはバッチジョブを実行
Cloud Pub/sub BQ Cloud Sotrage
ウインドウ:tumble(fixed), hop(slideing),session
- Flexible Resource Scheduling(FlexRS)(GA)
時間制約がないワークロード向き
- Dataflow Monitoring Interface改善
■まとめ
整数範囲パーティショニング使えるようになったタイミングで使いましたが非常に便利です。もちろんよくわからないくらい大きい桁は扱えませんが、データマートを作るタイミングでは非常に利用したいなと思いました。
顧客理解を深化させるために:バンダイナムコエンターテインメントが活用するデータ統合・分析プラットフォーム
■問題(障壁)
データのサイロ化(横展開ができていない)
データを活用できていない
■解決したい
データ活用の目指すべき姿に到達するためには2つの障壁を取り払う必要がある。
■なぜBQを導入したのか
■Redshiftの問題(ビジネス視点)
- データストレージコスト
- パフォーマンス(速度、性能)
■アナリスト視点
- 標準SQLの対応
- Window関数が使えるなどの分析関数が使える
メリット
- 処理が非常に速い(データに集中できる)
- コストが低い
- シンプルで運用しやすい
- プロジェクトごとに権限管理ができる
- プロジェクトをまたいでのjoinができる
- 多少非効率なクエリを書いても問題なし
- 一般的なBIツールをサポートしている
デメリット
- データカタログとしての一貫性があまりない
- Datasetの上位概念が欲しい
分析者からも好意的にBQを利用できている点が、データ分析基盤では重要だと思っているので、BQは非常にいい選択肢なのではないかと思いました。
まとめ
Datasetの上位概念は本当に欲しいです。やっぱりDWHやデータマートを構築すると非常に乱雑になるので、あると便利だなと思います。でも、バンダイナムコさんの一番良かったのは、アナリストの視点でBQが何がいいのかを共有いただけたことです。どうしても定額制でなく従量課金でBQを使い始めるとSQLを実行するだけでお金がとなってBQのよさが伝わらなかったりしたので、アナリスト視点を共有いただければ、社内でもアナリストとの共有はしやすくなるかなと思いました。
Google Cloud を使ったデータプラットフォームへの変革と最新の活用状況について
データプラットフォームの刷新なぜGoogle plaformを選んだのか?
■旧データプラットフォーム
特徴
- 多種多様な利用者(アナリストから企画、経営層までの利用)
- 高いレベルの自由度(アナリストが欲しいデータを作る)
- マルチテナント
課題
- モノリス化(改善が難しい、複雑化)
課題の顕在化について
- 進化、多様化する分析ニーズ(技術用件は事業/案件ごとに異なる)
刷新「モノリスからポリモフ(polymorph)」
■方針
サービスごとに環境分離
ワークロードごとにリソースの分離
■GCPを選んだ理由
- BigQuery(安い、スケーラビリティ、チューニングフリー)
- BigQueryを使うなら他のコンポーネントもGCPに寄せる
- アカウント管理が一元管理できる
- コストが一元把握できる
- サービスアカウントをGCP情なら管理してくれる
ポリモフの全体構成
■方針
サービスごとに環境分離
ワークロードごとにリソースの分離

■サービスごとに環境分離
サービスごとにプロジェクトを作る。
- 権限管理上のメリット
- コスト管理上のメリット
■ワークロードごとにリソースの分離
GKE(digdag, batch, webapp)上で管理している。
コンテナで管理することで、コンテナ内のカスタマイズは利用者に寄せる。- - batch
- webapp
■セキュリティ面
armor + identity aware proxyを利用して、セキュリティを担保する。

新データ プラットフォームへ効率の良い移行方法
移行に求められること
- 移行前と移行後のデータの差分を最小限にする。
- 移行を効率化する仕組みを提供する。
差分確認は自動化している

アナリストが自分たちでBulkできる仕組みを提供(Data Fusionで作れるが、自前で構築してる)

事例
SNSデータ(twitterなど)を使ったコミュニティとの関わり

デジタルマーケティングの施策
学習

予測
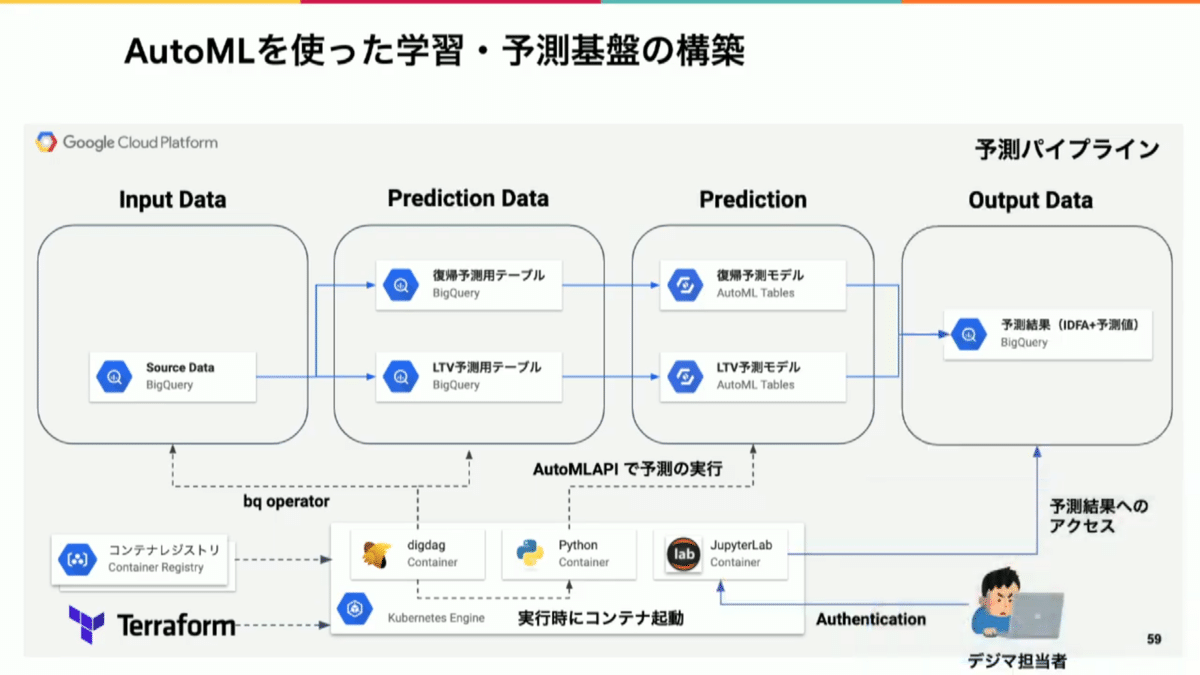
まとめ
BigQueryのフル活用をベースに、データの民主化をさせるための仕組み作りがすごい。。。オンプレからの移行もありすでにデータを使う(民主化まででなくても)準備はできていていたため、新規構築で作り込みできな部分までしっかり構築できている印象でした。

テーブル差分確認を自動化している点は非常に参考になったので、真似したいと思います。
CDP / マーケティング DWH のトレンドと Google Cloud での実現方法
CDP(カスタマーデータプラットフォーム)
GCPを使ったCDP


既製品とGCPで構築した場合の比較

ここは超重要です。データを取得するよりも利用側で本当に重要。

まとめ
データを活用して顧客に価値あるものを提案するためにCDPと言う考え方はいいと思いますが、セキュリティや運用など実際に使い続けてもらうために必要なことを説明いただけたのが非常に良かったです。
CDPなどはプライバシーと切り離せないため是非ビジネスサイドの方にみてもらいたいセッションでした。
GCP で構築する、これからの変化に対応出来るデータ分析基盤の作り方
運用に80%を使っている。
■運用を減らすデータ基盤を作るために
- Scalability(90%を意識)
- Microservice(疎結合にさせてエンハンスを高める)
- 分析ユーザ主体

基盤エンジニアのモチベーションコントロールが非常に重要。
■ETLプラットフォーム



専用線を引くことでIP枯渇。。。GKEのよさを活かしきれないは、聞いてるだけだとそうだよねと思うのですが、絶対に開発前の段階だと気がつかない、非常にツライ問題なと思いました。
■Garudaこぼれ話

整数範囲のパーティショニングでOracleのNUMBERの桁数を指定できなくて、辛くなった記憶が蘇りました。
まとめ
基盤エンジニアのモチベーション。。。非常にわかります。作っても使い始めたら当たり前とおもわれて感謝よりも不平不満が多くなる。これだとデータ活用する前に基盤を作る人がいなくなります。だからこそ、こんな素晴らしいアーキテクチャを作れる方がをチーム、企業としてもっと思いやる必要があるのだと再認識させられました。
あと、ETLを作る発想はなかった(Dataflowなどの利用するため)ので、非常に新鮮でした。しかも利用ユーザに設定をさせるなど凄すぎて言葉が出ませんでした。Embulkのよさも聴けたので非常にためになるセッションでした。
Pairs のサービス成長を支える BigQuery フル活用のデータウェアハウス(中止)
この記事が気に入ったらサポートをしてみませんか?