
Google BigQuery: The Definitive Guide感想 -Architecture of BigQuery-

目的
BQの仕組みを知りたい!!
経緯
仕事でBQを利用していますが、非常に便利で使いやすいデータベースという印象だったのですが、BQが通常のRDBと何が違うのかを理解はしているつもではいますが、さらにその裏(カラムベースと言ってもどうやってデータを管理しているのか??)のことはさっぱりだったので、もっとしっかりBQを理解することで、この魔法の様なサービスを100%使いこなせるのではないかと思い勉強していこうと思いました。
以降は、
6章の内容をまとめたものになりますが、
下記の内容は省略したりしているため、
しっかり内容を理解したい方は、
実際の本を読んでいただければ幸いです。
6. Architecture of BigQuery
■Summary
BigQuery の内部構造+クエリが実行されているときに何が起こっているかを説明しています。
特に重要なことは、下記の5つとなります。
・ライフサイクル:ハイレベルなアーキテクチャから、クエリが GFE サーバーで受信され、適切な BigQuery ジョブサーバーにルーティングされて Dremel クエリサーバーで処理されるまでのクエリのライフサイクルを追跡しました。
・スキャンフィルタ:最も単純なスキャンフィルタカウントクエリから、より複雑なスキャンフィルタアグリゲートクエリまで、より複雑なスキャンフィルタアグリゲートクエリまでさまざまなタイプのクエリのステージを調査し、再分割を必要とする可能性のある高いカーディナリティのクエリも調査しました。再分割を必要とする可能性のある高いカーディナリティのクエリも調査しました。
・結合:実装方法として、2つの方法があります。どの結合メカニズムが使用されているかはクエリプランから認識できます。
- 小さなテーブルにはブロードキャスト結合
- 大きなテーブルにはハッシュ結合
・タイムトラベル:データの保存方法、BigQueryのカラム型フォーマットの利点、辞書エンコーディング、ストレージセットを使用することでタイムトラベルが可能になる方法についても議論しました。
・パフォーマンス:パーティショニングとクラスタリングがどのように実装されているか、そしてなぜそれらがクエリのパフォーマンスを向上させるのかを見てみました。
■High-Level Architecture
■■Life of a Query Request
下記は、実際にBQにクエリを投げた際に実行する処理の簡略化した図です。


1.HTTPでのPostで通信(JSON形式でリクエスト)
2.GFE(Google Front End)からBQのバックエンドを見つけます。
3.ルータ(JSON HTTP リクエストを Protocol Buffers (Protobufs) に変換)
4.ジョブサーバは、正しいクエリサーバにリクエストをディスパッチする責任があります。ジョブサーバーは非同期で動作するように設計されています。
5.クエリマスタはメタデータサーバに連絡して、
物理的なデータの格納先やパーティショニング情報を確認します。
6.クエリサーバがどの程度のデータがクエリに含まれているかを把握し、
予備的なクエリプランを作成した後、
クエリマスタはスケジューラにスロットを要求します。
7.スケジューラは、
クエリ・シャード間でどのように作業を分担するかを決定します。
8.スロットのリクエストは、
クエリを実行するシャードのアドレスを返します。
9.クエリマスタは、
クエリ要求を Dremel の各シャードに並列に送信します。
10..クエリワーカーのシャードがクエリの実行を終えると、結果は2つの部分に分割されます。
- 最初のページほどの結果は、クエリのメタデータとともに、
分散型リレーショナルデータベースであるSpannerに格納されます。
Spannerは、実行クエリと同じリージョンにあります。
- 残りのデータはColossus(Google の分散ファイルシステム )に書き込まれます。BigQueryの結果は24時間保存され、機能的にはテーブルと同等であり、あたかもテーブルであるかのようにクエリすることができます。(10GBが制限)
スロットとは、クエリワーカーのシャード上で実行されるスレッドのことで、一般的にはCPUコアの半分と約1GBのRAMに相当します。
スロット = スレッド
■■BigQuery Upgrades
■Query Engine (Dremel)
Dremelの開発経緯が非常に面白いです。
Dremelは2006年に、MapReduceのジョブが終わるのを待つのに飽きてしまったエンジニアがクエリエンジンを作ったことで誕生しました。(本文引用)
Dremelの初期のトポロジーはツリー構造だった。
*Dremel はもはや固定ツリー構造を使用していませんが、Dremel クラスタは今でもよく「ツリー」と呼ばれています。
1.クエリはルートから入力
2.分岐してリーフに転送
3.それぞれがクエリの一部を操作する
4.結果と集計は、ツリーを遡ってルートに送られました。
クエリは、単純なスキャンと集計を行います。
- スキャンは葉の部分で行います。
- 集約は木の上の方で行います。
- 最終的な組み合わせは根元で行うことができます。
2010 年、Dremel のアーキテクチャは、単一の静的トポロジではなく、動的に実行計画を構築するように変更されました。
ツリーは、特定のタイプのクエリ、つまりスキャン・フィルタ・集約クエリには最適ですが、より複雑なクエリには不向きです。クエリがJOIN操作を行う必要がある場合や、ネストしたサブクエリを持つ場合は、ツリーを複数回通過する必要があります。さらに、ツリーを通過するたびに、異なるサイズのデータに対して操作を行うため、異なるスケーリングが必要になります。(本文引用)
SELECT
COUNT(*)
, starts.start_station_id as point_a
, ends.start_station_id as point_b
FROM
`bigquery-public-data`.london_bicycles.cycle_hire starts,
`bigquery-public-data`.london_bicycles.cycle_hire ends
WHERE
starts.start_station_id = ends.end_station_id
AND ends.start_station_id = starts.end_station_id
AND starts.start_station_id <> ends.start_station_id
AND starts.start_date = ends.start_date
GROUP BY 2, 3
ORDER BY 1 DESC
LIMIT 10上記のSQLの場合に、静的トポロジでは性能面で不向きだったので、動的にトポロジとなったらしいです。
現在のDremelのアーキテクチャは Dremel X と呼ばれていますが、動的なクエリプランを構築します。(本文引用)
ひえ!!現在version 10らしいです。
下記 は、Dremel X でのクエリの簡略化された制御フローを示しています。

■■Dremel Architecture
クエリエンジンは、下記の3つの部分から構成されています。
クエリマスター:クエリの計画(どのような作業を行うかの決定)を担当
スケジューラ:スロットの割り当て(誰が作業を行えるかの確認)を担当
ワーカーシャード:クエリの実行(作業の実行)を担当
■■■QUERY MASTER
クエリマスターはクエリの実行を担当します。
処理内容
1.クエリを解析する
2.クエリに含まれるテーブルと
各テーブルに適用されているフィルタの2つの情報を抽出します
3.クエリマスタは次にメタデータサーバから
テーブルのメタデータを検索し、テーブルのファイルロケーションを返す
- フィルタについて
パーティション・プルーニングを実行するために必要です。
BigQueryでは、テーブルをカラムでパーティショニングした後、そのカラムでフィルタをかけると、フィルタの外側のデータをスキャンしないようにすることができます。(本文引用)
フィルタの機能を利用することで、BQのクエリにかかる費用を抑えることができていることがわかります。
- メタデータサーバについて(メタデータサーバから返されるファイルの中には特別なものがあります。)
メタファイルの内容
1.テーブル内のファイルの位置
2.上記1がフィールド値にどのようにマッピングされているかを示す。
このメタデータを利用することで、データの大きさを把握することができるのですね。
クエリマスタの3つの流れを経て、クエリマスタがファイル情報を検索すると、クエリの実行にどれだけの作業が必要かがわかります。クエリをスケジュールするためには、スケジューラがスケジュールするスロット数を知る必要があるため、この情報は重要です。
ただし、クエリ・マスターがクエリをスケジュールする前に、クエリ・プラン(下記イメージ参照)の作成という重要な作業を行う必要があります。

最初のクエリ計画を作成した後、
1.クエリ・マスターはスケジューラに連絡して、
クエリを実行するスロットを探す。
2.スケジューラはワーカーシャードを割り当て、
そのアドレスをクエリマスタに返します。
3.クエリマスタは、
作業単位(通常は1ファイルずつ)をシャードに送信します。
4.実行は、
スケジューラから返されたスロット数に応じて並行して行われます。
5.利用可能なスロットが不足している場合は、
一部のワーカー・シャードが現在の作業を終えるまで待ってから、
スケジューラに追加のスロットを要求します。
*スケジューラは、
クエリに割り当てられたスロットをいつでも増減させることができます。
クエリ、プランは基本的に実行したものでしか見てないので(GUI経由)、実は実行計画の段階でできているのかと、気がつかされました。
ワーカーシャードの作業が終わると、クエリーマスターはスケジューラに戻り、第2ステージ以降のクエリーを実行するためのスロットを要求します。最終段階が終了すると、クエリーマスターはジョブサーバーに戻ります。
■■■SCHEDULER
クエリにスロットを割り当てる役割を果たします。
スロットは作業の単位で、一般的には1つのファイル(読み取り段階)または後の段階のためのShuffle Sinkの処理に対応します。Shuffle Sinkは、中間的なクエリ結果を一時的に保存する場所です。
スロットはWorker Shards上で実行されるスレッドです。
1つのWorker Shardタスクで多くのスロットを実行することができます。
クエリを実行する際に最大2000スロットを利用することができるが、他ユーザがオンデマンドプールの上限との兼ね合いで2000スロット全てを利用できない場合もあります。
スケジュールの特徴
- クエリのスロット割り当ては基本的に「公平」です。
- 優先度の高いユーザーのために実行中のスロットをキャンセルしたり、公平性を確保したりすることができます。
*スロットの対策としては公式から「予約済み」スロットを購入することもできます。これは、そのユーザーがそのスロットの第一拒否権を持っていることを意味する。このようなユーザーは、必要なときにいつでもその数のスロットを持つことが保証されています。
ここでは、スロットのについて知ることができました。今までBQでは定額制プランでスロットを事前に購入できるとあったのですが。。。そちらの意味が全くわかりませんでした。「スロット=スレッド」として考えれば、結局は処理する場所を事前に購入すると意味がわかったので非常に勉強になりました。
■■■WORKER SHARD
クエリで実際に作業を行う
Borgについて
BQを利用しているかならずBorgを耳にします。簡単に言うとk8sですね。
Worker Shard は、Google のコンテナ管理システムである Borgで実行されるタスクで、Dremel はハードウェアやインフラストラクチャの管理を気にすることなく、コンテナ内で何千もの並列タスクを実行できます。
Worker Shardは、クエリの1つのステージのごく一部を実行するために、リモート・プロシージャ・コール(RPC)インターフェースを公開します。RPCインターフェースは、クエリのどの部分を実行し、どのデータ上で実行するかをWorker Shardに指示します。(本文引用)
BigQuery UI の実行計画を見ると、シャードで実行される SQLスニペット(READ, WRITE部分)を見ることができます。そのスニペットのほとんどは通常のSQLのように見えますが、特にクエリの途中のステージを見ると、ソーステーブルとデスティネーションテーブルが見慣れないように見えるかもしれません。
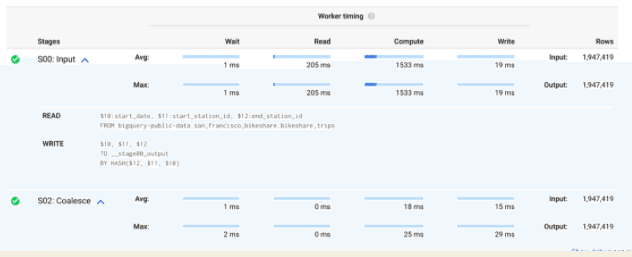
クエリのソースはColossus上のファイルで、クエリされるテーブルを表すか、以前のステージの出力です。一般的には、1つの入力ファイルが1つの実行スレッド(スロット)に割り当てられ、Worker Shardは要求されたクエリの一部を実行し、その結果を宛先の場所に書き込みます。
書き込み先は通常、インメモリファイルシステムです。例外は、クエリが大量のデータを書き出す必要があり、これが最終段階となる場合です。インメモリファイルシステムは、クエリのステージ間の短期的な耐久性のあるストレージを提供し、クエリがステージ間のシャッフルを実行できるようにします。
■■■SHUFFLE
Shuffleを使用すると、
複数のSinkにデータを書き込むことで、
ステージ間でデータに依存したデータフローが可能になります。
たとえば、Shuffleは、
「A」で始まるすべてのデータをシンク1に書き込み、
「B」で始まるすべてのデータをシンク2に書き込みます。
次のステージでは、
1つのWorker Shardがシンク1から読み込み、
"A "で始まるすべてのデータにアクセスできるのようになります。
別のWorker Shardはシンク2から読み込み、
"B "で始まるすべてのデータにアクセスできることを知ることができます。
ステージに関与するシャードの数は、書き込まれたシャッフルシンクの数に大きく依存します。では、どのくらいの数のシャッフルシンクを使えばいいのでしょうか?BigQueryは下記に示すように、出力のサイズと形状に応じてクエリ中にシャッフル・シンクの数を動的に変更します。
つまり、BigQueryが開始時にシンク数を正しく推定するのが上手であればあるほど、クエリの実行速度は速くなります。(本文引用)


クエリの実行結果を見ると上記のようなのを見ると思いますが、読み方が全くわかりません。。。。
Shuffleをした際に、メモリ上にのせきれないデータはdiskに保持されますが、結果としてメモリだけを利用する時よりパフォーマンスが低下してしまいます。
Bytes shuffled:シャッフルされたバイト数
Bytes spilled to disk:ディスクにオーバーフローしたバイト数
BQのクエリが遅い場合は「Bytes spilled to disk」を見る必要があり、改善のためには、クエリを分割することをお勧めしています。
■■Query Execution
下記ではサンプルクエリをもちいで、クエリプランの見方を説明します。
*下記は、ほぼ備忘みたいな内容となっております。
■■■SCAN-FILTER-COUNT QUERY
SELECT COUNT(*) as c
FROM `bigquery-public-data`.new_york_taxi_trips.tlc_yellow_trips_2017
WHERE passenger_count > 5
2つの実行ステージがあることに注目してください。S00とS01です。
1つ目(S00)は
入力で、これは読み込みフェーズで、Colossusから読み込みます。
2つ目(S01)は
出力で、最終的な結果を結合してユーザーに返す役割を担っています。
下記の処理をもとに、クエリマスタは9つのWorker Shardすべてに並行してリクエストを送信します。
1.クエリマスターは、クエリにどれだけのデータが含まれているかを見て,
それをチャンク(一般的にはファイルに対応する)に分割します。
この場合、9つのファイルがあります。
2.クエリマスタはスケジューラに9つのスロットを要求します。
3.スロット(9つの)が利用可能なので、
スケジューラは9つの異なるWorker Shardsの情報を返します。
Worker Shardsにリクエストが渡された後の動きを下記に記載します。
Stage 0(S00の処理)
処理
1.各Worker Shardはファイルを読み込みます。
2.まず、5人以上の乗客を乗せたタクシーだけを保持する必要があります。
3.次に、残りのタクシー乗車数をカウントアップする必要があります。
現状は、結果を並列に計算しているため、各シャードは合計結果を計算するのに十分な情報を持っていないため、部分的な結果を次のステージに送る必要があります。つまり、ここでは、最終集計はしていない。

READ:指定した条件で乗客数を読み取ります。
AGGREGATE:ここでフィルタを適用し、結果をカウントします。
WRITE:AGGREGATEの結果をインメモリに書き込む
COUNT_STAR()は、行数をカウントする内部演算子です。
これらの部分的な結果を計算し、指定された出力領域に書き込んだ後、各シャードはクエリマスターに戻ります。
Post–stage 0
一度、ワーカー・シャードに戻り、そこから今回のクエリの結果を出力するためのStage1をスケジュールします。この場合、9つの値の合計を計算するだけなので、1つのスロットが必要です。
Stage 1(S01の処理)

READ:Stage0の結果をインメモリから取得
AGGREGATE:ここでは、READをSUM_OF_COUNTS()しています。
WRITE:結果を出力します。(サイズが小さいため、Spannerに書き込まれる-BQのキャッシュ(一時テーブル)-)
クエリマスターがジョブサーバーに戻った後、ジョブサーバーは結果をクライアントに返すことができます。結果は小さいので、Spannerに書き込まれるので、クライアントが自由に結果を取得できるようになっています。
■■■SCAN-FILTER-AGGREGATE QUERY
SELECT title, COUNT(title) as c
FROM `bigquery-samples.wikipedia_benchmark.Wiki1B`
WHERE title LIKE "G%o%o%g%l%e"
GROUP BY title
ORDER BY c DESC
#### RESULT
Row title c
1 Google 2904
2 Google_Chrome 1302
3 Google_Wave 623
4 Google_Translate 561
5 Google_AdSense 426
stage0
READ, AGGREGATE, WRITEを読みますが、Worker Shardでデータを共有するためにhashを使っているのは驚きました。(こんなことをやっているのかと言う意味で)
READ:対象条件(フィルタ)からtitleカラムを読み取る
AGGREGATE:title絡むごとにGroupByして、titleごとのカウントを取得
WIRTE:__stage00_outputとして結果を書き出すが、BY HASHディレクティブを追加して、ハッシュと紐づくバケットにデータを送ります。(バケットは Worker Shard 間で共有されているので、特定の値に遭遇したすべての Shard は結果を同じバケットに送ります。)つまり、title別に特定のバケットが用意されていて、そこにWRITEされるようになります。(このルーティングは、グローバルな結果をスケールで計算できるかどうかの鍵となります。)
Hashの使い方としては、下記がの本文引用がわかりやすいです。つまり、ハッシュ化することで「1つのWorker Shard上で結果を処理する」ための必要な処理だとわかります。
クエリによっては何十億、何兆もの異なる値を持つ可能性があるため、
- 値ごとに1つのバケットを作成するのではなく、
- 値に数学的なハッシュ関数を適用し(これがBY HASHの意味です)、その出力をバケット名として使用します。
これは、同じ入力値が常に同じ出力値を取得することを意味し、1つのWorker Shard上で結果を処理するために重要です。また、複数の異なる入力値を同じバケットに入れることができるため、ユニークなバケットの数を減らすことができます。(本文引用)
rows列について
rowsの「output」は28,693となっています。これは「使用されたスロットと値の積」を示しています。
例
各Worker Shardが100個の異なる値を見ていて、200個のShardがあった場合、この数は20,000(100 * 200)になります。
stage1
ステージ0のシャッフルされた出力から読み込み、最終的な集計を行う。

入力データはカウントしているものによってシャッフルされているので、最終的な集計は並行して行うことができます。つまり、バケットが"Google "や"Google_Chrome "専用に分かれているので、マッチするタイトルの部分的なカウントはすべて同じバケットから取得することができます。
ここでは、出力される行数は5,115行です。
Stage 2
5,115個の値を読み込んでソートするだけです。

ソート操作は、非常に多くの値がある場合を除き、単一のWorker Shard上で行われます。
■■■SCAN-FILTER-AGGREGATE QUERY WITH HIGH CARDINALITY
Filter処理がない場合どうなるのか???
SELECT title, COUNT(title) as c
FROM `bigquery-samples.wikipedia_benchmark.Wiki1B`
GROUP BY title
ORDER BY c DESC
Stage 0
BigQueryが小さすぎるハッシュバケットの数を選んで、
データをより大きな数のバケットに再シャッフルする。

1,205,625,714件の値があるが、一度に全てを処理ができない。
単一のノードでソートでないないため、分散ソートを行う


分散ソートを行い、最終的な結果を書き込む。

結果として、かなり多くの分散さん処理をすることになるため、料金も非常に跳ね上がってしまうことが上記の仕組みからわかります。
■■■BROADCAST JOIN QUERY
BQの結合について
BigQueryの結合にはブロードキャスト結合とハッシュ結合の2種類があります。(本文引用)
以下では、BROADCAST結合についての説明です。条件としては、テーブルの1つが小さい場合に使用できます。
テーブル全体をすべてのワーカーに送信することで、シャッフルを必要せずに結合することができます。
WITH
repo_commits AS (
SELECT repos AS repo_name, author.name AS author
FROM `bigquery-public-data.github_repos.commits` c, c.repo_name repos
WHERE author.name IN ("Valliappa Lakshmanan", "Jordan Tigani")
GROUP BY repos, author),
repo_languages AS (
SELECT lang.name AS lang, lang.bytes AS lang_bytes, repos.repo_name AS repo_name
FROM `bigquery-public-data.github_repos.languages` repos, repos.LANGUAGE AS lang
)
SELECT lang, author, SUM(lang_bytes) AS total_bytes
FROM repo_languages
JOIN repo_commits USING (repo_name)
GROUP BY lang, author
ORDER BY total_bytes DESC
### result
Row lang author total_bytes
1 Jupyter Notebook Valliappa Lakshmanan 78900202
2 Python Valliappa Lakshmanan 33742613
...
8 Jupyter Notebook Jordan Tigani 153243
9 Python Jordan Tigani 134409
... 上記のクエリは、CROSS JOINやWITH文による配列の平坦化など、かなり高度なクエリ技術を使用しており、クエリを読みやすくしています
SELECT lang, author, SUM(lang_bytes) AS total_bytes
FROM repo_languages
JOIN repo_commits USING (repo_name)
GROUP BY lang, author
ORDER BY total_bytes DESCS03:coalesceは、非常にシンプルです。ROWSも37しかないことを確認できます。

S04:JOIN+の意味は「JOINとAGGREGATE」をやっていると言う意味です。
JOINの「each with all」がロードキャスト結合を識別する唯一の方法となります。結合の左側のテーブルの各行を取って、"ALL "で一致させることを意味します。

■■■HASH JOIN QUERY
同じキーを含む行が同じバケットに入るように、
結合の両側をハッシュ化することで動作します。(データ量が多い)
WITH
repo_commits AS (
SELECT repos AS repo_name, author.name AS author
FROM `bigquery-public-data.github_repos.commits` c, c.repo_name repos
-- WHERE author.name IN ("Valliappa Lakshmanan", "Jordan Tigani")
GROUP BY repos, author),
repo_languages AS (
SELECT lang.name AS lang, lang.bytes AS lang_bytes, repos.repo_name AS repo_name
FROM `bigquery-public-data.github_repos.languages` repos, repos.LANGUAGE AS lang
)
SELECT lang, author, SUM(lang_bytes) AS total_bytes
FROM repo_languages
JOIN repo_commits USING (repo_name)
GROUP BY lang, author
ORDER BY total_bytes DESC
LIMIT 100
### result
Row lang author total_bytes
1 C Eric Dumazet 2917514359851
2 C Russell King 2878666474184
3 C Thomas Gleixner 2876903624978ハッシュ処理はすべての等価値を同じバケットにルーティングするので、単一のワーカーがそれぞれのバケットをピックアップし、バケット内のキーの結合を実行するために必要なすべての情報を持つことができることを意味します。

JOINが「EACH WITH EACH」となっていることを確認してください。これは、左側の各行が右側の各一致する行と結合されることを意味します。
■Storage
あらゆるデータベース管理システムの成功の秘訣の1つは、効率的なストレージです。(本文引用)
BigQueryの高速性 = データの保存方法が鍵となります。基礎となるストレージハードウェア(大規模な分散ファイルシステムを使用)からファイルフォーマット(カスタムカラムストア)に至るまで、メタデータとストレージデータの両方を構成するBigQueryのストレージスタックは、分析のスピードを高めるために常に最適化され続けています。
■■Storage Data
BigQueryは、数十の地域にある数百万の物理ディスクに分散されたエクサバイトのデータを保存します。
下層ストレージシステムの主な目標
- この分散データのすべてに高速にアクセスすること
- どの2つのテーブルも互いに結合できるようにすること
つまり、同じ場所に存在する必要があることを保証することです。
■■■PHYSICAL STORAGE: COLOSSUS
BigQueryは、Google全体で使われている分散型ストレージシステムであるColossusにすべてのデータを保存しています。
Colossus = Google File System(GFS)を進化させたものです。
Colossusは、より柔軟なメタデータシステムを構築し、単一障害点を取り除くことで、GFSにあったスケーラビリティ、柔軟性、信頼性の多くの問題を解決しています。
Colossusは、多数のサーバで多数のディスクを運用し、それらが結合してファイルシステムを形成する。数万、数十万のディスクがあれば、そのうちの数十台のディスクが毎日のように故障することになります。しかし、目標は、これまで(あるいは少なくとも数百万年以内に)データを失わないことです。ディスクが死んでもデータを失わないようにする方法は、データを複数回書き込むことです。Colossusでこれを行う場合、エンコーディングと呼ばれます。
■エンコーディングの種類
- レプリケート・エンコーディング
(データの複数のコピーを書き込む)
- 消去エンコーディングorリードソロモンエンコーディング
(データの数学関数を他のディスクに格納して、複雑さとスペースをトレードオフにします。)
下記の例では、1つのデータを 3つの別のディスクに書き込んでいます。
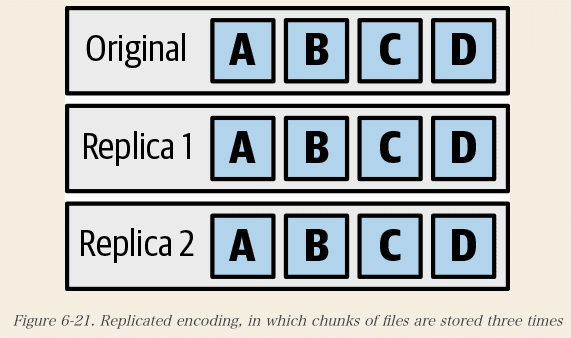

BigQueryは、ほとんどのデータを消去エンコーディングで保存し、十分なリカバリ ブロックを使用することで、3 者間で複製されたエンコーディングよりも桁違いの耐久性を実現しています。(本文引用)
■■■STORAGE FORMAT: CAPACITOR
BigQueryは、独自のカラム型ストレージ形式です。
Capacitorは、BigQueryで使用される第2世代のフォーマットで、第1世代は基本的なカラムストアでした。Capacitorは、エクサバイト級のデータを扱う分散型クエリエンジンを8年間実行してきた経験から学んだことを基に構築されました。
ParquetとOptimized Row Columnar(ORC)は、2つの人気の高いオープンソースのカラム型ストレージ形式ですが、BigQueryでは、アンダーグラウンドではこれらを使用しないことを選択しました。
Capacitorの主な機能の1つは、辞書エンコーディングです。つまり、カーディナリティが比較的小さい(異なる値が少ない)フィールドに対しては、ファイルヘッダに辞書を格納する。
例えば、ジュークボックスで演奏される曲が含まれるテーブルがあります。
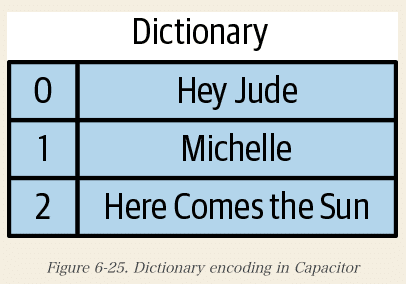
完全なタイトルを格納する代わりに、Capacitorはオフセットを辞書に格納するだけでよく、よりコンパクトになるようにします。
- 最初の列(0)はエンコードされた曲のタイトルです。
- 2番目(xc*)の列は別のデータフィールド(おそらく曲の再生を要求した顧客)です。

辞書エンコーディングのもう一つの利点は、フィルターです。
例えば、曲のタイトルに "Sun "という単語が含まれている行を探しているとします。これは、文字列のどこからでも値を見つけられるようにする必要があるため、比較的高価なフィルタです。
通常は、テーブルの各行を比較して、述語に一致する値を探します。しかし、Dictionaryに対して述語をテストして、結果の真理値テーブルを作成することができます。

さて、Lookup taleは、値がTorFを示す配列です。すべての行をスキャンする際には、ルックアップテーブルにインデックスを作成するだけです。例えば、エンコードされた値が "1 "であった場合、ルックアップテーブルのオフセット1の値を調べると、評価はFであることがわかる。
さらにスペースを節約するために、Capacitorはランレングスエンコーディングを行う。つまり、"2 "という値が一行に5回現れる場合、"2,2,2,2,2,2,2 "を格納するのではなく、"2:5 "を格納することができます。同じ値が長く続く場合、これはかなりの圧縮になります。
しかし、同じ値のロングランが複数回存在しないように行が順序付けされている場合はどうでしょうか?これを解決するために、Capacitorは巧妙なトリックを採用しています。BigQueryの行は順序付けされておらず、どの行が他のどの行の後に来るかは保証されていないし、予想もされない。

Likeとかで文字列をよく扱ってはいますが、内部的にLoop upを利用しているなど、内部のことは全く知らなかったので、かなり斬新でした。
■■Metadata
メタデータとは、格納されているデータに関するデータのことです。
データ基盤を作っている観点からも、日々データを適切に利用するメタデータの重要性を感じています。
BigQueryのテーブルのメタデータには3つのレイヤーがあり、そのうちユーザーが直接見ることができるのは2つのレイヤーのみです。
1.外側のレイヤーはデータセットで、
テーブル、モデル、ルーチンなどのコレクションであり、
アクセス制御権限が1つのセットで構成されています。
2.次の層はテーブルで、スキーマとキー統計情報が含まれています。
その内側の層はストレージセットで、データが物理的にどのように
保存されているかについてのデータが含まれています。
3.ストレージセットはユーザーから見えない概念であり、
それに関する情報はユーザーから隠されています。
(本文引用)
■■■STORAGE SETS
ロードジョブ、ストリーミング抽出、またはデータ操作言語(DML)クエリに応答して作成される、アトミックなデータ単位です。
つまり、観点としては下記が存在します。
- アトミック(一度にすべて発生するか、またはまったく発生しない)
- コンシステント(コミット後はどこでも利用可能)
- アイデムポテント(エラーやネットワーク・パーティションが発生しても複数回のコミットを心配する必要がない)
- 耐久性(コミット後、コミットが失われない)があります。
+追加
BigQueryの基礎となる物理ストレージは不変です。
ファイルを閉じた後は、二度と変更することはできません。
ストレージ・セットも同様に不変で、コミット後は二度と変更できません。
(本文引用)

■■■TIME TRAVEL
BigQueryは過去7日間のタイムトラベルをサポートしており、そのタイムウィンドウ内の任意の時点でテーブルの状態を読み取ることができます。
タイムトラベルを有効にするには、BigQueryはストレージ セットの遷移が発生したタイムスタンプを追跡します。(下記では、T1, T2, T3としているものです。)下記は、時刻T1、T2、およびT3にそれぞれコミットされた3つのストレージセットを持つテーブルを示しています。T2からT3の間のある時点でテーブルを読みたい場合、最初の2つのストレージセットだけが必要になります。

■■■STORAGE OPTIMIZATION
クエリに最適な形にデータを配置するのに利用します。
これは、定期的にファイルを書き換えることによって行われます。
ファイルは、
1.最初に書き込みが速い形式で書き込まれ(書き込み最適化ストレージ)、
2.後にクエリが速い形式で書き込まれます(読み取り最適化ストレージ)。
つまり、データは複数の世代に分けて書き込まれ、それぞれの世代はより古く、より最適化されています。
下記は、第1世代のデータが最適化され、第1世代に書き換えられたテーブルを示しています。
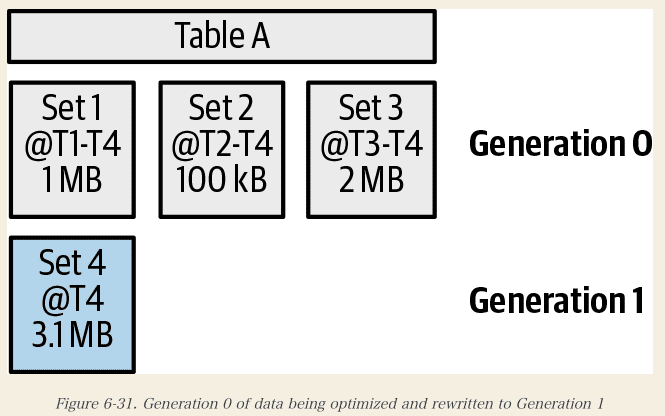
最適化されたストレージセット(Set4)には、Set1,2、および 3と全く同じデータが含まれています。セット 4 がコミットすると、最初の 3 つのストレージセットはゴミとしてマークされますが、すぐには削除されません。ユーザーは、以前のストレージ・セットだけが存在していたテーブルを読みたいと思う可能性があるため、BigQueryはそのメタデータを追跡する必要があります。
■■■PARTITIONING
BigQueryのパーティショニングを使用すると、大規模な論理テーブルを小さなパーティションに分割し、必要な部分だけを対象にクエリを実行することができます。テーブルを日付でパーティショニングしておけば、パーティショニングされたテーブルを使用してそのデータのみを効率的に読み込むことができます。
パーティションは基本的に軽量なテーブルです。1つのパーティションのデータは、他のパーティションとは物理的に別の場所に保存され、パーティションはメタデータのフルセットを持っています。
これにより、以下のことができます。
1.パーティション上で tables.delete() のREST API エンドポイントを
呼び出して削除することができます。
2.パーティションの有効期限を設定すると、
日付ベースのパーティションがテーブルであるかのように
一定期間後に有効期限が切れるようになります。
パーティションを利用することで、複数テーブルをサフィックスで分割しているよりもjoinが減り、filterだけで対応ができるため、効率的にデータをスキャンすることができる。また、パーティションフィルタは、一般的にメタデータデータベース層(Spanner)にプッシュダウンすることができるので、不要なデータだけでなく、不要なメタデータの読み込みを節約することができます。
注意点
パーティションは、一般的に数千以下の低カード性(すなわち、異なる値の数が少ない)フィールド向けに設計されています。テーブルを過度にパーティショニングすると、多くのメタデータを作成することになります。テーブル規模が大きいテーブルの全体を読み込む必要がある場合は、すべてのメタデータを読み込む必要があるため、効率が悪くなります。その場合は、クラスタリングを使うべきです。
パーティションの数を減らす1つの方法は、月別パーティションのような粗い粒度のパーティションを作成することです。これは、イベントの日付を月レベルに切り捨て、そのフィールドでパーティションを作成する別のフィールドを作成することで実現できます。
メタデータでパーティションを表現するために、BigQueryはパーティションIDでマークされたストレージセットを使用します。これにより、パーティションに基づいたフィルタリングが容易になります。特定の日付に一致するパーティションのみを読み取るために、BigQueryは物理データを開くことなくメタデータ層でフィルタを適用できます。ストレージ・セットにはフィールド・サイズ情報も含まれているため、実際にクエリを実行しなくても、ドライ・ランでスキャンされるデータ量を判断できます。
下記は、3つのストレージ・セットを持つテーブルを示しています。この場合の各ストレージセットは、異なるパーティションを表しています。

パーティショニングカラムがeventDateで、
WHERE eventDate >= '20170102'を含むクエリを実行していたとします。
これは、2つのストレージ・セット20170102と20170103だけにマッチするはずです。
ストレージセットの特定方法
「IDX = Spannerデータベースインデックス」から対象のストレージセットを見つけ、ここでは、Set2と3に対して、クエリを実行します。その結果Set1にはストレージセットを見る必要がなくなるので、料金と実行速度が速くなる。
■■■CLUSTERING
クラスタリングは、
データ内の列から構築されたキーに基づいて
半ソートされた形式でデータを保存する機能です。
データファイルは、キー空間の重複しない範囲を取得します。これにより、クエリエンジンはキーを持つファイルのみを開く必要があるため、効率的なルックアップと範囲スキャンが可能になります。

上記テーブルは customer_id フィールドによってクラスタ化され、ファイル内のデータは、ファイルが customer_id の非重複範囲を持つようにソートされます。
- ファイル 1 には顧客 ID 101 から 200 までの顧客 ID
- ファイル 2 には顧客 ID 201 から 300 までの顧客 ID
実行されるクエリが SELECT ... WHERE customer_id = 275 であるとします。ファイルは customer_id の昇順であることがわかっているので、ファイルヘッダを見るだけで customer_id 275 が File 2 にあることがわかります。バイナリ検索を行って開始ファイルを見つけることができ、正しいファイルを見つけた後に他のファイルを見る必要はありません。テーブルはクラスタ化されているので、すべてのファイルを読み込むのではなく、1つのファイルだけを読み込む必要があります。
データファイルには、すべてのフィールドの最小値と最大値を含むヘッダがあります。ここでの利点は、ヘッダーを見るだけでテーブルに値があるかどうかを確認できることです。さらに、ファイルヘッダがキャッシュされているので、ディスクI/Oを全く行わなくても必要なファイルを正確に特定できることが多いです。
■■■Reclustering
この断片化(時間の経過とともにrow追加がある場合)の解決策は、リクラスターリングです。定期的に、バックグラウンドでBigQueryがテーブルを再クラスタリングします。BigQueryは、データが完全にクラスタリングされている割合であるクラスタリング率を維持します。その割合が低すぎると、ソートされた形式でデータが書き換えられます。これは、以前のテーブルの状態にタイムトラベルする能力を維持するために、新しいストレージ セットで行われます。リクラスタリングはユーザの介入なしに自動的に行われ、ユーザがお金を払わなければならないリソースではなく、「システムリソース」を使用して行われます。
下記は、Reclusteringを行うイメージです。

■■■Performance optimizations with clustered tables
クラスタリングは多くのクエリ最適化を可能にします。
SELECT orders.order_id
FROM retail.orders AS orders JOIN retail.customers
ON orders.customer_id = customers.customer_id
WHERE customers.customer_name = 'Jordan Tigani'これは "Jordan Tigani "という名前の顧客の全ての注文を見つけます。ここでは、注文テーブルが customer_id によってクラスタ化されていると仮定します。これを実装するための素朴な方法は、顧客テーブルのフィルタを実行し、残りの部分をすべてのシャードにブロードキャストしてから、注文テーブル全体をスキャンして、顧客IDに一致する注文を見つけることです。しかし、オーダーテーブルは customer_id によってクラスタ化されているので、一致する customer_id を持つファイルを見るだけでよいので、テーブル全体をスキャンする必要はありません。これにより、コストを削減し、パフォーマンスを大幅に向上させることができます。
もう一つ注意すべきことは、クラスタリングはクラスタリングされたフィールドでフィルタリングする場合だけではなく、クラスタリングされたフィールドと相関のあるフィールドでフィルタリングする場合にも機能するということです。
例えば、order_id でクラスタ化された orders テーブルを持っていて、注文は大体順に並んでいるとします。狭い範囲のトランザクション日付でフィルタリングするクエリを実行すると、それらのトランザクション日付は少数のファイルに含まれます。この最適化はパフォーマンスだけでなく、オンデマンド・モードで運用している場合、クエリのコストも削減されます。一般的に、BigQueryがスキャンする必要のあるデータ量を減らすためにできることは何でも、クラスタ化されたテーブルで運用する場合にコストを削減できます。
■■■DML
DMLは、テーブルを変更するための特別なSQL文のセットです。これらには4つの種類があります。INSERT、DELETE、UPDATE、MERGEです。
テーブルに行を追加するINSERT操作は、基本的にはテーブルにデータを追加するのと同じなので単純です。INSERT操作が実行されると、新しいデータを表すファイルがColossusに書き込まれ、新しいストレージセットがメタデータに追加されます。新しいストレージセットには、データが取り込まれた時刻のコミットタイムスタンプがあります。
しかし、テーブルから行を削除するDELETE操作は、より複雑です。BigQueryは、不変ファイルとメタデータ(ストレージ セット)を使用します。1 つの行を削除したい場合 (DELETE ... WHERE customer_id = 1234)、さらに、その行がストレージ セット 3 のファイル C に存在していたとします。BigQueryではファイルは不変であるため、単一の行を削除するには、ファイルCの途中から行を削除することはできません。その代わり、BigQueryは行を含まないファイルのコピーを作成します。これを C2 と呼びましょう。BigQuery は、古いストレージ・セット GARBAGE はもう使用されていないので、これをマークします。書き換えられたファイルには、ストレージ・セット 4 というストレージ・セットが必要になります。新しいストレージ・セットには、ストレージ・セット 3 にあった他のすべてのものを格納する必要があるため、これだけでは十分ではありません。新しいストレージセットは、ストレージセット3の古いファイルを指しますが、現在削除された行を持つファイルCを除いて、ストレージセッ ト3の古いファイルを指します。図 6-35 は、このすべてがどのように展開されるかを示しています。

これが1行を削除するのが大変そうに聞こえるならば、その通りです。このような理由から、更新をバッチ処理して、できるだけ多くの更新を一度に適用するのが最善の方法です。
UPDATEは通常、INSERTとDELETE操作のアトミックな組み合わせとして実装されています。つまり、実際にデータを変更するのではなく、古いレコードを削除して新しいレコードを追加します。
MERGEは、基本的には、読み取り、変更、および書き込み操作を同時に行うことができる、非常にファンシーなUPDATE文です。UPDATE は、更新された行の新しい値を持つ新しい追加データを書き込むだけです。同様に、MERGE はマージされたデータをさらに書き出します。
■■■META-FILE
BigQueryがパーティション・プルーニングを行う際に良いパフォーマンスを発揮する方法の1つは、メタファイルを使用することです。この章で説明したように、これはテーブルを構成するすべてのデータファイルに関するメタデータを含むファイルです。このファイルには、すべてのフィールドの最小・最大制約と各データファイルの場所が含まれています。このファイルは BigQuery データファイルと同じ形式で格納されているため、他の BigQuery ファイルと同様にクエリを実行できます。これは、どのファイルを読み込む必要があるかを判断するために、クエリエンジンがすべてのファイル ヘッダーを見る必要がないことを意味します。この 1 つのファイルを読み込むだけで、クエリで実際に必要なファイルを絞り込むことができます。

WHERE field1 = 30という述語を持つテーブルからクエリを実行する場合、まずこのファイルにクエリを送信し、必要なファイルはfile0002だけであるという結果を返信することができます。この情報があれば、クエリを満たすために他のファイルを開く必要はありません。
この記事が気に入ったらサポートをしてみませんか?