
NMKD Stable Diffusion GUI の img2img

つまり、画像を元にしてAIに描いてもらう方法。
NMKD_SDの主な使い方について
化け物スペックPC推奨。
概要
NMKD_SDは主軸が複数あるのでそれらを徐々に合わせていく。
水平思考ゲームのように、徐々に範囲を狭めて取得するイメージ。
主軸
影響が大きい順

①訓練モデル(Stable Diffusion Model File).ckpt
ゲーム機ごと変更するイメージ。
どのような学習をしてきたかが大きな違い。
Init Image Strength (influence)の0.000値がプロンプトでどのようなものが出るか、がモデルの相違点。
===================
https://note.com/preview/nace10f722b38?prev_access_key=20d31f3d326f6b35862509d14a668e55
それぞれのモデルの出力結果(NSFW注意)
===================
人物写真だけ、風景写真だけ、絵画だけ、みたいな学習をすると出力結果もそれに偏る。
この0.000値が理想の形にどれだけ近いかで完成精度が大きく変わる。
1つ当たり平均5GBぐらい。.ckpt形式。
この学習元の平均値がAIイラストで受けられる恩恵の最大値です。
変更の詳細は以下より。
②Strength(influence)
NMKD_SDが作成した画像を0.000、
こちらが読み込ませた画像を1.000とした場合の
それぞれのブレンド率です。

左が0、右が1。
元画像から大きく変化させたい場合はより0に近い数値に、
元の画像をほぼ変えない場合はより1に近い数値にします。
大体の場合これの値を0.025にカーソルを合わせて、
ボックスの中身を0.000 > 1.000 : 0.1
などにしてちょうどいい部分を探り当てて行きます。
コラム:参照画像の影響力-Strength(influence)
ほとんどの場合、バストショットがカウボーイショットやニーショット、
3面図など、元から大きく変化した構図になることはありません。
(あるとすればプロンプトを完全無視した出力結果)
シミュラクラ現象から新しく人の首が生えるみたいなことはあります。
また多くの場合、元の絵より上手な絵が出力される
ということもほとんどありません。

一見グレードアップしたように見えますが、よく見ると左手の山の方が手前にあるのに、出力結果では右手が手前になっていてほぼ別物です。
この程度別に気にしない!
っていう方にとってはグレードアップかもしれませんが。


③プロンプト
画像を参照する場合にも使用します。
画像をプロンプトで説明します。

↑これがプロンプト
訓練モデルの学習先がdanbooruであればnovelAIのプロンプトが参考になる
んじゃないですかね…?
学習先のタグは使えるハズです。
④Generation Step
書き込み量です。
イメージとしては、数値が小さいほど、めちゃ太ペン先で描いた感じになります。

背景部分がわかりやすいかも。
数値を下げて荒くした場合、その画像を元に、数値を上げても荒くした部位が細かく戻るということはないので注意。
(荒い部分は荒い部分の中が鮮明な感じになる)
なお、このステップ数が出力時間に直結するので、
数値が倍に増えれば出力時間が倍に増えます。
⑤Prompt Guidance(CFG scale)
img2imgの場合ほとんど影響力はありません。
0だってOK。




形は変わらないけど、モデルの特色が強く出るみたいです。
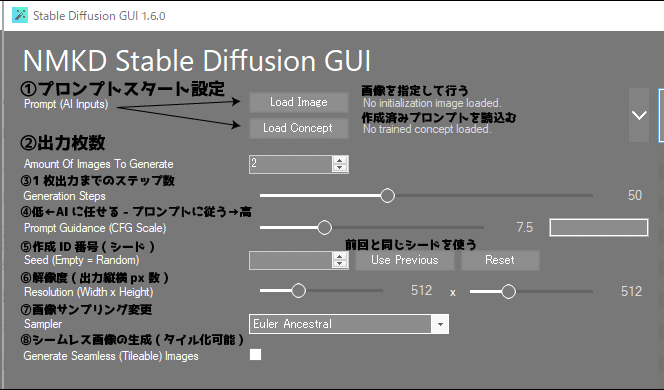
作成手順
最初に手順を俯瞰すると、
デフォルト値を決めて、①から順番に数値を切り替えて試していきます。
これで終わりです。
詳細
画像を読み込む
または、直接フォルダからドラッグして、NMKD_SDの上に移動させる。
または、クリップボードからペーストする。
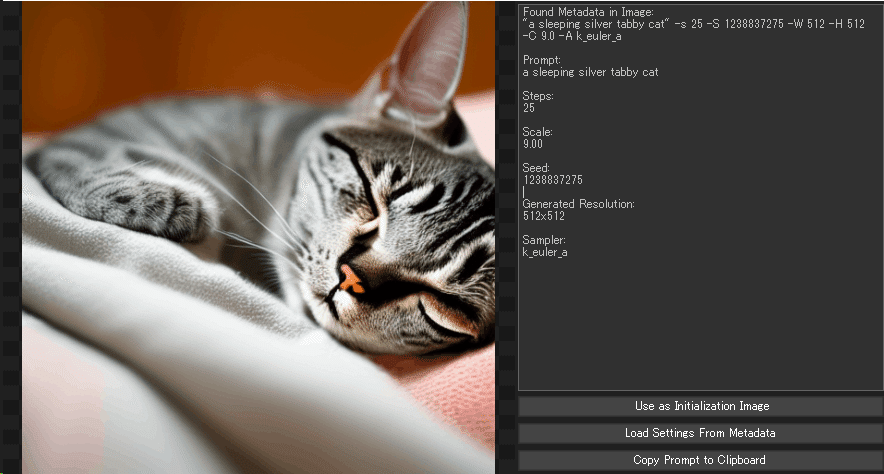
右上のボックスの羅列は、メタデータです。
右下3つのボタンはそれぞれ
「Use as Initialization Image」…初期化画像として使用
→②Strength(influence)の値1.000の画像データ。
「Load Settings From Metadata」…メタデータから設定を読み込む
→この画像がNMKD_SDで作成された画像の場合、メタデータが自動入力されます。右上にあるメタデータが転記されると同義です。
「Copy Prompt to Clipboard」…プロンプトをクリップボードにコピーする
→プロンプトのみをクリップボードにコピーします。メタデータは自動入力されないし初期化画像データとしても読み込みません。
なので、画像として読み込むので一番上の「Use as Initialization Image」
を選びます。
画像を読み込むと上画像のように変化します。
デフォルト値を入力しておく
ほぼ初期起動時のままで大丈夫です。
大体上の画像の数値です。
Masked Inpainting は初期は使わないと思うのでチェック外してください。
Generale Seamless(Tileble)Images=(タイル化)も必要なければ外す。
プロンプトを入力
読み込ませた画像を英語で説明します。
文でもいいし、学習先のタグ名でも大丈夫です。
後々加えていくので2,3単語ぐらいで。「 1 girl 」とか。
Masked Inpaintingを行う際は、マスク内の変化後の説明の記入します。
①の訓練モデルを決める
②Strength(influence)の値0.000の画像データになります。
これはそれぞれ特色とトリガーフレーズがあるので、実際に試して
使い分けるのがいいと思います。
===================
https://note.com/preview/nace10f722b38?prev_access_key=20d31f3d326f6b35862509d14a668e55
それぞれのモデルの出力結果(NSFW注意)
===================
試し運転
起動後の初回や、モデルを切り替えた初回が一番マシンパワーを使います。
動画を開きながらとかで出力するとクラッシュすることがあります。
とりあえずGeneration Stepを最小値(5)にして試し運転を1度終わらせてください。Amount Of Image To Generateは当然1です。
この時出力された画像の縦横比が歪んでいる場合、
Resolutionで読込み画像の比率と同じ比率に変更してください。
②を「0 > 1 : 0.1」で出力する
②Strength(influence)の混合率を調査します。

0.220 > 0.300 : 0.01
と範囲を狭めていく。
1つに決まったら、右側のボックスの中身を削除して、左側のつまみでその数値に合わせます。

左のつまみ+右のボックスの連続値 枚 出力されることになる。
③でプロンプトを加える、または減らす
例えば髪色がおかしいという場合髪色を指定するプロンプトを付加します。
どうしても譲れない部分を加えていくようにするのが吉です。
Amount Of Image To Generateの値を1から5,10ぐらいに増やして探るのがよさげ。
④の数値を50-70にする。
この時点でもう出力内容が安定しているはずです。
④Generation Stepの値を50-70ぐらいに設定します。
この数値が最終出力まで持続します。
高い数値出力物を下げることは見た目の変化がわかりますが、
低い数値出力物を高くしても低くなったままに見えます。
数百枚出力する
あとはガチャです。理想のものが出る確率を一番高く設定できたはずなので
あとは運です。
Amount Of Image To Generateの値を100ぐらいにして出力を待ちます。
初期化画像を置き換える
場合により。数百枚のうち、より理想に近いものができたらそれを初期化画像にします。方法は「画像を読み込む」にて。
画像編集ソフトがある場合、出力物の良いところだけを切り合わせて1枚絵にしてから置き換える(キメラ化)という手もアリ。
⑤Prompt Guidance(CFG scale)で色濃くする
しなくてもいい。
以上。
注意
設定値の複数指定
7>10:0.5 ✖
7 > 10 : 0.5 〇それぞれ半角スペースを開ける
生成枚数について

計10枚出力される。
以下作成例
=============================
写真から(フィギュア)



訓練モデル次第だろうけど
nsfwタグを入れた方がクオリティが爆上がりしやすいこともある。

0.3 > 0.8 : 0.1
0.6 > 0.7 : 0.05 ここで型決定
0.8 ×10 ブラッシュアップ
初めから人形特有の不自然部分を塗潰して置けばもっと早いかも。
背景が星になったり偶然が楽しいです。
大体2時間ぐらい。
実写→二次元キャラ

https://www.pakutaso.com/20150358071post-5269.html

[lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers] , ( masterpiece )
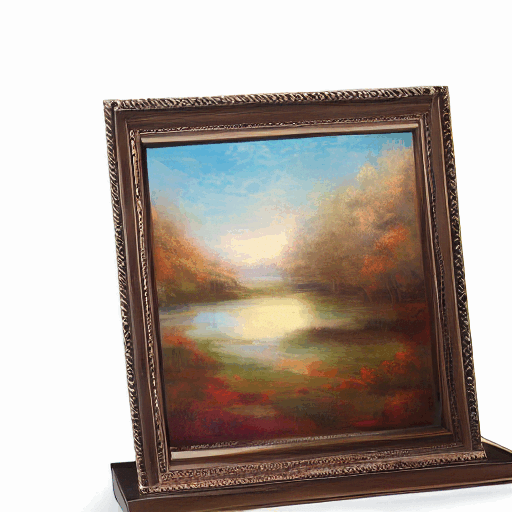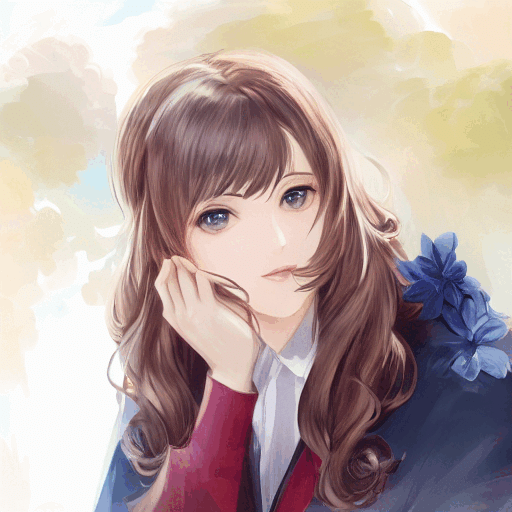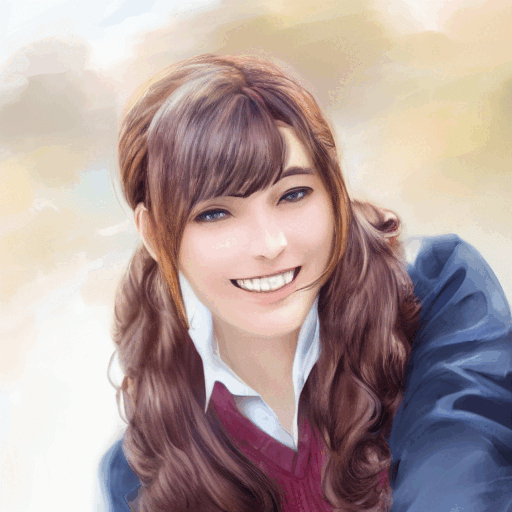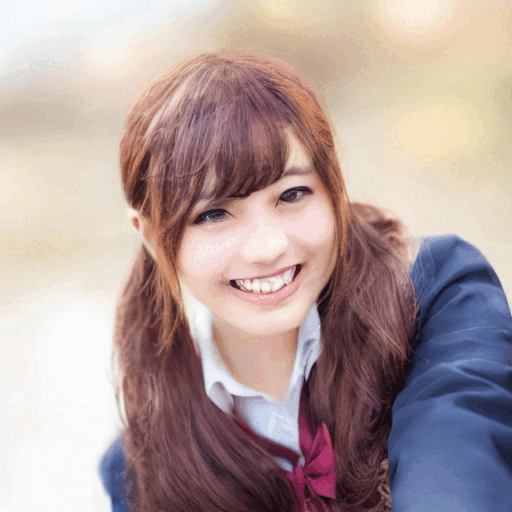
nsfwをつけた方が理想に近いのが出ることもある。
0.2-0.5辺りが日本アニメっぽいのでそこに範囲を狭めてもう一回。
プロンプトの追加は必要に応じて1つずつ増やしていきます。

をプロンプトに追加
この画像をload image してさらに絞り込みます。
IISが0.05ぐらいが欲しい変化だと確定したので100連ガチャを行います。

右の窓に記入してると、0.050と0.5が両方出力。
つまり200枚出力になってた。

上左2を使ってもうちょいアニメ寄りに。

ファインチューニング並みに特定のキャラしか出ない
みたいなのだと変わりやすい。
Generation Step を下げると油絵みたくなるけど、
そこから元の塗りに戻すのはかなり無理でした。


これにて完成です。
AI→描く→AI→描く→AI

IIS 0.1 > 0.3 : 0.05 → IIS 0.3 > 0.7 : 0.1

IIS 0.7

IIS 0.9
内職しながらだったので5時間ぐらい。
画像の一部分だけ変化させる(マスク)
用途としては、表情を変化させたり、hgkrを作ったり…?

極端な出力結果だとこんな感じ。

生足にしよう。
なお、肌色をスポイトして塗れば終わる模様。
色情報を引きずる
上の画像のまま足にマスクをかけて出力すると

パールオレンジ色と指定しているのに、元の色情報を引きずっています。
最適な色を先に載せて置く

この時点でもう本末転倒である。

終わり!
活用方法

無から有を発生させる


思い通りにはならないでしょう。
スーパー最適なプロンプトと学習データがあれば可能かもしれません。
画質の荒い部分を置き換える
意図的に荒くしてある部分を本来の形に近いものに置換ることができます。
以下を一か所ずつ行っていくとベター。
適応範囲を1周り大きくマスクをかける
プロンプトでマスク内を置き換える
イラストソフトで整える
元の画質の荒さをマシにするフィルター
幸せな呪文
線が細く、影段階が1-2、アニメ塗り向け
ゲームの立ち絵など。
モデルはHentai Diffusion。
"nsfw ,
【その絵を表すプロンプト】
img2imgの場合、色に関する情報は絵から取得してプロンプトからは取得しにくいので書かなくて良い。
性別、人数、ポーズ、恰好、状態を記入。
,masterpeace ,((uncensored)) , (anime) , (2D) ,
[[[ lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers ]]]"

W×Hの比率は変更したい画像に合わせて必ず100%同じにすること。
イラストソフトなどでキャンパスサイズ自体を変更する。
この時、広げた範囲が透明の場合、クリップボードから貼付けのとき
透明箇所を無視無視するので、一番端に枠をつけておく。
比率が合わないと置き換え結果自体が上手く行かない。
00年代前半アニメーション
範囲が大雑把で真四角な奴。
モデルはHentai Diffusion。
プロンプト周りは上と同義。

最速で書き出せるサイズはW512*H512。
画像サイズをそれにして、出力サイズを3倍にする。
マスクは範囲の淵を中間サイズでなぞるように、ぼかしは最大。
前処理として、真四角をガウスぼかしで
真四角が消える+陰影が残る程度に行う。(720*480で27ぐらい)
最終的に、元のサイズの解像度に変形する。(もとより大きい状態から縮小する)
この記事が気に入ったらサポートをしてみませんか?