
NMKD Stable Diffusion GUI

やりたいこと
写真を取り込んで、その人物を二次元キャラに落とし込む
または指定した等身のデッサン人形に置き換えて構図の参考にする

これはNMKD Stable Diffusion GUI を理解するために咀嚼した記事です。。
以下NMKD_SDと記載。
参考
公式説明書
仕様書
DreamBooth 訓練ガイド(24GBのVRAMが必要)
(補足)VRAMを増やすには
どんなものか
プロンプト(指示書・呪文)から画像を生成するお絵かきAIの1種、
Stable Diffusionの派生ソフト。
GUIなのでボタンぽちぽちのみ。(コマンドモードもある)
DLして扱う。無料。(お布施可能)
化け物スペックPC専用
作成事例

たのしい pic.twitter.com/UYTDnCseXc
— ききよ🥉 (@_kikiyo_) October 26, 2022
機能(端的に)
プロンプトを用いて画像を作成する。
画像を元に画像を作成できる。(作成のスタートをその画像にする)
プロパティを全く同じにすれば、誰でも同じ画像を生成できる。
訓練モデルを取り替えることで、写真、アニメ、ケモノなど出力結果を偏らせることができる。
ファインチューニングでプロンプト圧縮ができる。
一度に数百枚作成できる。(PCスペックによる)
64px刻みで縦横比の解像度を変更して出力できる。
イラストの作成方法(端的に)
プロンプトを元にNMKD_SDのAIが学習した画像データをいい感じに組み合わせて作成する。
作成した画像の中からより良いものを選んでそれをゴール地点に
設定しなおして再度作成をする。作成物とゴールの中間から厳選する。これを繰り返す。
ポケモンの個体値厳選みたいなイメージ。
アップデートの注意
アップデート機能はないため、新たに全てをDLしなおして新設する
ダウンロード
説明通り。
注意点
グラフィックボード(GPU)がNVIDIAのみ対応
最新バージョンの全部入りは4GB。
基本的にゲーミングPCなどの化け物スペックPC専用です。
その他注意
ZIPの解凍ソフトはLaplaceだと途中で止まった。(1時間ぐらいかけて40%で止まる)
7-ZIPだと1、2分で解凍できた。
解凍の中身その場でソフトを作成するので、解凍場所は最終設置場所が好ましい。
後は上のリンク先通り。
以下DL後
基本操作
※起動した最初の1回目は10分以上かかることもある。
モデルを変更した際も同時間かかる。
慣らし運転としてGeneration Stepを10で1回動かすのオススメ。
作成した画像は、

に作られる。(設定で変更可能)
操作画面
ver1.6時点では日本語未対応です。


だいたいこの「出力設定」と「呪文詠唱」と「プレビュー」で構成。
他のボタンはマウスオーバーすれば説明がでます。(英語)
1クリックで詐欺られた!みたいなものはないので、一度クリックしながら確かめた方が早いかも。
「出力設定」→「プロンプト記入」→「出力ボタン」
でイラストが出力されます。
出力設定

それぞれの機能をまとめるとこうなります。

①Prompt(AI inputs)-スタート設定
画像生成の一番最初の参照素材を指定します。
しない場合、NMKD_SDが1から生成します。
画像の場合、その比率を⑥Resolutionの比率と合わせる必要があります。
(⑥の比率に入力画像が歪む)
②Amount Of Images To Generate-出力枚数
根本となるイラストを何枚出力するかを決めます。1~∞。
例えば、④Prompt Guidance(CFG Scale)-AIの制御を複数指定して出力する場合、②×④枚出力します。
⑨があるimg2imgでも複数指定の場合、②×④×⑨枚出力します。
他の諸々の設定が完全に固まってから100枚とかするのがPCに優しいです。
③Generation Steps-ステップ数
1枚出力するまでに内部で作り直す回数。5~120。
多い程精巧に作成されますが、時間がかかります。

これをコンピューターが指定した回数繰り返すみたいな感じ。

20~60ぐらいが推奨されてます。
④Prompt Guidance(CFG Scale)-AIの制御
プロンプトにどれだけ従わせるかの数値です。0~25。
低い程NMKD_SDが自在に、高い程プロンプトに従わせます。
7-12ぐらいがセーフティ。0.5刻みで変更可能。
⑤Seed(Empty = Random)-ID作成
出力イラストに識別番号を付属。入力なしでランダム生成。
⑥解像度と⑦サンプラーと⑤が一致している場合同じ画像の出力が可能。

(またはLoad Settings From Metadata)

"a sleeping silver tabby cat" -s 25 -S 1238837275 -W 512 -H 512 -C 9.0 -A k_euler_a
---------------------------------------
"プロンプト" ステップ数 シード番号 解像度 CFG(AI制御) サンプラー
が圧縮されたメタデータなので、これを分解して記入してもOK.
⑥Resolution(Width×Height)-解像度
出力画像の縦横px数。256~1024(64px刻み)
(→PCのスペックで出力最大サイズが変化するらしい。)
大きい程出力に時間がかかります。
⑦Sampler-画像サンプリング
技術仕様
①で画像参照にした場合、これは項目から消えます。
どのような手段で行うか。過程。
ステップ数を増やせば最終的に同じものになるらしい(理論値)。
これらの違いは計算式が異なる。らしい。

"a sleeping silver tabby cat" -s 25 -S (ランダム)-W 256 -H 256 -C 9.0 -A ●●(この部分だけを変更)それぞれ5枚ずつ出力。

ステップ数が少ない程上手く行く。デフォ。
制作者のオススメ設定はこれ。







少ない③ステップ数で行う場合や、その過程の偶然を狙って行うときなど。
好みのものを選んで使え!というものでもなく、それぞれにおいて得意なプロンプトがあるとかないとか。
従ってstepが小さいならSampling methodを変えるメリットはあるが、stepが十分大きいならSampling methodをデフォルトから変えると却ってノイズが増えて悪化する可能性があるので注意する。
⑧Generate Seamless(Tile able) Images-シームレス画像の生成(タイル化可能)


繰り返しパターン画像のことです。

出力設定まとめ
①Prompt(AI inputs)…画像やプロンプトがある場合設定。なければ無視。
②Amount Of Images To Generate…初期は5枚ぐらいから。厳選時に増やす。
③Generation Steps…20-60ぐらい安定。②が横幅、③が縦深度な感じ。
単純に数値が倍になると出力時間も倍になる。
④Prompt Guidance(CFG Scale)…7-12が成功率が高い。
⑤Seed(Empty = Random)…無記入でOK。再現出力の時に使用。
⑥Resolution(Width×Height)…①で画像参照の場合は比率を合わせる。
⑦Sampler…デフォのEuler Ancestralが製作者オススメ。画像参照時消える。
⑧Generate Seamless(Tile able) Images…テクスチャを作るときのみ使用。
プロンプト記入(呪文詠唱)

基本
デフォ設定で55単語まで。
プロンプトとネガティブプロンプト([]で囲む)はそれぞれ最大55単語。
=二つ合わせて最大110単語。
改行することで別のプロンプトとして記入可能。
=5枚出力している設定だとすると、1行5枚ずつ出力。
NovelAIと同じように英文で行ったり、単語を「,」で区切って作成します。
anime cat, anime style, cat, anime eyes, blush, detailed blue sky and green grass, japanese, pixiv, vulpix style, jewelpet style
重み付きプロンプト
出力イラストの構成の中でどの程度の割合なのかを表します。

cat:0.7 fox:0.3
many strawberries:0.6 green apples:0.4 on a plate
単語の後に「:」をつけて0-1の数値で示します。
文法途中に挟んでもできなくはない。(多すぎると破綻する)
全ての合計が1でなくてもOK。
マイナスの重み
単語の後に「:」をつけて-0~-1の数値で示します。
-0.3を超えたあたりから画質がおかしくなる上、
あんまり精度はよろしくないです。

下記の強調構文の方が信用度は高い感じです。

いやなんだこれ
強調構文
出力イラストで、これを必ず入れる/これは省くという要素を指示できます。
(100%ではない)
強い(この要素を入れろ)
↑
---
●●●:1
((()))
(())
()
何もしない
{}
{{}}
{{{}}}
●●●:-1
---
↓
弱い(この要素を入れるな)
---
[]…完全に除外する… , photo of blue sky [clouds] , … ,
画質向上のためにネガティブプロンプトを用いるというテクニックも。
lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers
https://pajoca.com/stable-diffusion-gui-nmkd-1-5-0/
画像から編集(img2img)
目次の出力設定-①Prompt(AI inputs)-スタート設定
で画像を読み込みます。


画像読込出力設定
⑨Init Image Strength (influence)-参照画像にどれだけ寄せるか
0.050~0.950
訓練モデルで生成した0.000の画像と
参照画像1.000の画像の混ぜる割合です。


もちろん、最初の0.025の出力画像がより理想に近い程
ブレンドの質が上がります。
そのための指標にプロンプトを用いるわけです。
訓練モデルの違いはこれだと思います。
⑩Masked Inpainting-一部分だけ変更する
画像を読み込み、Masked Inpaintingにチェックを入れる。
変えたい内容のプロンプトを事前に記入する。→出力
マスクの編集画面でプロンプトを適応させたい箇所を塗る。→出力(終)

猫ちゃんの肉球が花になっちゃった図。怖
このマスクは透明度0%の時と同じ効果を持つらしいので、
GIMPかPhotoshopで変化させたい箇所を透明にくり抜いて、png保存時に
「色の値を保存」にチェックをつけたものを使用すると同等効果が得られるらしい。
ちな、clipstudioでは不可能でした。
設定値を複数指定して画像を複数枚自動生成
イラスト作成の初期の初期、様々な設定で手探りで作り始める時に。
Creativeness (Guidance Scale) と img2img の Init Image Strength (Influence) は設定値を複数指定して画像を一括で生成させることができます。
Creativeness (Guidance Scale)==④Prompt Guidance(CFG Scale)-AIの制御
(バージョンアップで名前変更)

記入例
10,20,30 …1回目は10、2回目は20、3回目は30の数値で出力する。
7 > 10 : 0.5 …7から10までを0.5刻みに増加して出力する。(1回目は7、2回目は7.5、…7回目は10)注意
7>10:0.5 ✖
7 > 10 : 0.5 〇
それぞれ半角スペースを空ける。出力枚数何枚?
全ての組み合わせが出力されます。
⑨が5種、④が10種、②が5枚の場合、5*10*5で250枚作成されます。
有志のファインチューニングを読み込む
※Textual Inversion の .ptファイル・.binファイル をソフトで読み込んで利用する方法です
ファインチューニングとは。
これは、3~5枚の画像を用いて、スタイルを表す新規の単語の埋め込みベクトルを学習する方法である。
既存のパラメータは一切更新しないで、既存モデルに新規の単語を追加することで、その単語が追加画像のスタイルを表すように学習される。
使用する画像は、配色やスタイルが統一されている必要がある。

引用:https://tadaoyamaoka.hatenablog.com/entry/2022/09/21/210417
ファインチューニング共有場所
読み込み方
上記共有場所などから.ptまたは.bin ファイルをDL。
①Prompt(AI inputs)-スタート設定の「Load Concept」からそれを読み込む。
プロンプトで使うには
「*」を付ける。その単語はファインチューニングで学習した内容から参照。
* = 圧縮されたプロンプト(マクロや関数みたいなもの)。
smile face of *
自分で作るには
手を付けたらまた咀嚼記事あげます。
訓練モデル(Stable Diffusion Model File)の読み込み
Stable Diffusion本家のモデルとは異なるモデルも NMKD Stable Diffusion GUI で使用可能です。
ファインチューニングがMOD的なものだとすれば、モデルを変えるというのはゲームカセットを切り替えるみたいな、その規模の変更。
本家は写真ベースのものが多いけど、アニメキャラだったりケモノキャラが出力できるようになる。(出る確率を大幅に上げる)。
切替え方
この記事のその他>設定(Setting)のStable Diffusion Model File部分から
フォルダを開いて.ckptファイルを読み込む。終わり。
一度登録したファイルはctrl+Mでモデルの切り替えが可能。
訓練モデルについて別記事にしました。
↓(NSFW注意)
https://note.com/preview/nace10f722b38?prev_access_key=20d31f3d326f6b35862509d14a668e55
その他

編集(Post-Processing Button)
現在の機能は2つ。
1.出力した画像の解像度をその画像のまま高める。
2.出力した現実の人間の顔の歪みを修正する。(二次元キャラ不可)
出力し終わったものに編集するのではなく、出力中に上を行います。
なので、③Generation Steps-ステップ数を最大、④Prompt Guidance(CFG Scale)-AIの制御を最大にするか、
⑤、⑥、⑦を同一のものにして全く同じものを出力させます。
拡張機能(Developer Tools Button)
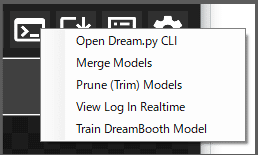
Open Dream.py CLI
Merge Models

Prune Models

View Log In Realtime
Train DreamBooth Model

私のPCだと無理。
設定(Settings)

キュー(Prompt Queue Button)
作成したプロンプトをキューに出し入れします。
左クリックで参照、右クリックで現在値を追加。
履歴(Prompt History Button)
使用したプロンプトの履歴です。ロードもできる。
削除(Image Deletion Button)
一度に作成したイラストを1つずつ削除またはまとめて削除。
過去に作ったものは消えない。
ショトカ
ホットキー (メイン ウィンドウ)
CTRL+G:イメージ生成を実行します (または、既に実行中の場合はキャンセルします) 。
CTRL+M:モデル クイック スイッチャーを表示 (開いたら、ESC を使用してキャンセルするか、Enter を使用して確認します)
CTRL+PLUS:プロンプトのテキストボックスのサイズを切り替え
CTLR+DEL:現在表示中の画像を削除
CTRL+SHIFT+DEL: (現在のバッチの) 生成されたすべての画像を削除します
CTRL+O:現在表示されている画像を開く
CTRL+SHIFT+O:フォルダ内の現在の画像を表示
CTRL+V:画像の貼り付け (クリップボードにビットマップが含まれている場合)
CTRL+Q:終了
CTRL + スクロール:フォント サイズの変更 (マウスがプロンプト テキスト フィールド上にある場合のみ)
F1:ヘルプを開く (現在は GitHub Readme へのリンク)
F12:設定を開く
制作者更新ノート
この記事が気に入ったらサポートをしてみませんか?