
Elasticsearchを使ったパフォーマンス
こんにちは。ビズパ プロダクト開発チームの吉留です。
前回のnoteでは、ビズパの検索機能をElasticsearchにリプレイスした背景と実際にリプレイスした時のハマった部分、効果ついて書きました。
今回は、Elasticsearchの検索パフォーマンスについて、より詳細に書きたいと思います。
(※全体的にビズパで検証した結果での内容となります。もしかしたら調べきれていない範囲で他にもっと良い解決策があるかもしれないことを予めご了承ください。)
パフォーマンス改善を実施する背景
ElasticsearchはApache Luceneベースの全文検索エンジンです。
ドキュメントという単位でデータを保持し柔軟に検索をすることが可能です。
RDBで例えるとINDEXがテーブル、ドキュメントがレコードというイメージです。
ドキュメントには単一の文字列や数値はもちろん、配列やオブジェクトを持たせることもできます。
しかし、ドキュメント自体の増加やドキュメント構造の複雑化・肥大化によってパフォーマンスが出なくなってくることがあります。
ビズパでも上記のような理由から、思ったようにパフォーマンスが出なくなってきたという背景より、パフォーマンス改善を実施することになりました。
Elasticsearch のドキュメント構成について検討
ビズパでは掲載している広告を「媒体」と「商品」という2つの単位でデータ保持しています。
データ構造的には、媒体と商品が1:nの関係で紐づくイメージです。
検索に表示されるのは媒体単位であり、検索自体は商品単位レベルから行われます。
そのため、INDEXでデータ管理する際にドキュメントが、媒体単位なのか商品単位なのかについて検討する必要がありました。
より具体的には、
INDEXで保持するドキュメントを媒体単位にし、結果をそのまま表示する。
INDEXで保持するドキュメントを商品単位にし、媒体単位に集約(Aggregations)して表示する。
という2パターンを考える必要があるという意味です。
商品の掲載される場所や価格等の情報、駅系の媒体であればどの駅に紐づいているのか、特定の駅ではなく路線全体に紐づく商品なのかなど。
ビズパでは1媒体、1商品に対して複数の情報をできるだけ正規化した形で保持しているため、検索はさらに複雑になります。
そのため一概にドキュメントの構成はどちらが良いと判別できない状態にありました。
そこで、検索パフォーマンスの向上をするために両方の構成で速度を確認し、どちらがどれくらいパフォーマンスが出るのかという検証を行いました。
ドキュメントを媒体単位にするパターン(nestedが3階層)
まず、Elasticsearchのパフォーマンスについて検索すると多くヒットするのが、nestedフィールドという形で子要素、孫要素の形でデータを保持するのがパフォーマンス劣化につながるというものです。
ビズパを例に媒体単位でドキュメントをINDEXに保持する場合、媒体 - 子要素(商品)- 孫要素(商品に紐づくデータ)といった形で1ドキュメントにつき3階層までデータが大きくなることになります。
nestedフィールドの特徴として、nestedフィールドのデータ(子要素 or 孫要素)を更新する場合にも、ドキュメント全体が更新されるという仕組みになっているため、更新に対してパフォーマンスが悪くなります。
ただし、Elasticsearchの裏側で採用されているApache Lucene上ではnestedフィールドのデータは1つのドキュメントとして保持されるそうです。
マッピングのコストが高いため更新パフォーマンスは悪くなりますが、検索パフォーマンスに関してはビズパが行った検証では遅延は認められませんでした。
(nestedフィールドの数がそれほど多くないという理由もあると考えています。)
参考 :
更新時のパフォーマンスが劣化するというのも比較的大きな問題になると考えられます。
また、今後nestedフィールドで保持するデータが増えた場合を考慮し、商品数と商品に紐づくデータを増やしたテストを行った結果、ヒットしたnestedフィールドを取得する inner hits でパフォーマンスの問題が発生しました。
これはINDEXで保持するドキュメントが媒体単位になっており、商品単位レベルでの絞り込みが行われていないため、inner hitsで検索するnestedフィールドの数が多いためと考えています。
ドキュメントを商品単位にするパターン(nestedが2階層)
次に、INDEXで保持するドキュメントを商品単位に変更してAggregationsを使って集約する方法を検証しました。
ビズパの場合、商品単位に変更しても、商品に紐づくデータを保持する必要がありますので、nestedフィールドは存在します。
ただし、階層が1つ減って子要素までの2階層構成になります。
商品単位に変更後、更新時のパフォーマンスはとても良くなりました。
商品単位での更新が可能になるため、特に商品が多く紐づいている媒体に関しては更新コストが大きく低下します。
検索に関しては、Aggregations自体はそれほどパフォーマンスが悪くないというのが現状の認識ですが、集約されるデータの件数が多くなった場合に非常にパフォーマンスが劣化することが分かりました。
具体的にはビズパには「消火栓」と「電柱」という1媒体に紐づく商品数が数万件レベルの媒体が存在します。
検索にヒットするたびに数万件の商品を1メディアに集約する可能性があり、コストは非常に大きいです。
さらに inner hits を取得する際にも、inner hits はドキュメント単位で取得するため、数万件のinner hitsを取得する必要が出てきます。
そのため、INDEXで保持するドキュメントの構成はどのようにするのが良いか一概に言えないというのが現状の検証結果です。
パフォーマンスをシビアに観察し、適切なドキュメント構成にしていくことが大切だと感じます。
Aggregationsを使う時の注意点
次にAggregationsを使う際に、注意する点について実際にハマった部分を3つほど挙げたいと思います。
AggregationsはSQLで言うところのGROUP BYに相当し複数のドキュメントを集約をするために用います。
例えば、ダッシュボードなどでレポートを表示するケースなどでは利用する機会があると思います。
1. inner hitsは使えない
Elasticsearchのクエリでは検索条件に一致したドキュメントが返却されますが、返却される件数を size パラメータで設定することができます。
Aggregationsを使う場合、返却結果が集約されるため一般的にsizeは0に設定しますが、これの影響でinner hitsが取得できません。
集約しているので、取得できないというのは当たり前のような感じですが、集約単位でのinner hitsの参照もできませんでした。
そのため、inner hitsを利用したい場合はAggregationsを使わないクエリを発行するという結論に至りました。
パフォーマンス面では、しっかりと検索対象の件数を制限することで大きな問題にはならないと考えています。
2. 基本的に事前に絞り込みをする方が良い
Aggregationsを利用する際に、集約したものをさらに絞り込みすることが可能です。
これはSQLだとHAVINGに相当します。
SQLと考え方は同じですが、基本的に集約前にできる限り絞り込みをしておいた方がパフォーマンスはよくなります。
これはinner hitsでも同様のことが言えます。
いかに無駄なドキュメントを事前に省くことができるかというのがポイントになると考えています。
3. ソートが少し特殊
Aggregationsでは集約したあとにソートをかけることが可能です。
ソートでは集約に関して指定したフィールドを利用することができます。
ソートにはbucket_sortを利用しますが、検証した結果、通常のElasticsearchクエリのようにソートの構文の中でscriptが使えませんでした。
そのため、Aggregationsの中でbucket_scriptを利用し、集約後のフィールドとして定義した上でこれをbucket_sortで利用する形で対応しました。
通常のクエリでは可能ですがbucket_sortでできないという点は少し注意が必要です。
インフラ設定周り
まず、インフラ設定に関して最初にやっておくべきなのはストレージです。
十分なディスク容量があることは大前提ですが、HDDを使っている場合はパフォーマンスが劣化する可能性があるようです。
インデキシングと検索の公式ドキュメントにも明記されているため、SSDを検討してみるのが良いと思います。
参考 :
ビズパでは初期構築のタイミングからSSDを採用していたため、今回変更によるパフォーマンス検証はしておりません。
すこし脱線しますが、AWS EC2を使っている場合、EBSのSSD(汎用)の選択肢としてgp2とgp3が選択可能です。
gp2はバースト機能があり、gp3はバーストがありませんがIOPS、スループットの値を事前に設定しておくことが可能です。
また、gp2のバーストした時の最大IOPS、スループットはEBSの設定サイズによるようです。
ビズパの場合、EBSのサイズがそれほど大きくないため、gp2でバースト機能があるものよりもgp3を利用した方が良いという結論に至りました。
また、gp3をデフォルトのIOPS、スループットで利用する場合はgp2よりもコストが抑えられるため、EBSのサイズと相談してgp2、gp3を選択するのが良いと思います。
次にシャードの数です。
シャードはデータを実際に保持しているところであり、INDEXをいくつかのシャードに分割させて保持させることが可能です。
複数のシャードにINDEXを持たせることによって並列実行ができるようになるため、パフォーマンスの改善に働く可能性があります。
一方で、シャードのサイズを大きくすることはサーバー負荷に影響を与えるため、サイズの調整は慎重に行った方が良いです。
詳細についてはElasticsearch公式のドキュメントにまとまっているため、シャード数の設定を検討中の場合は一読することをオススメします。
参考 :
その他
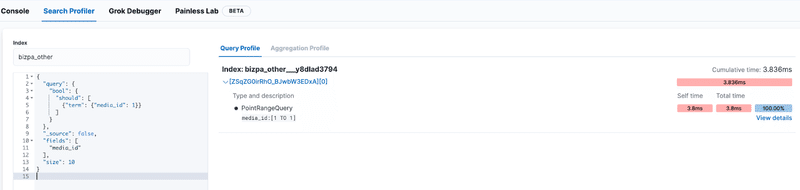
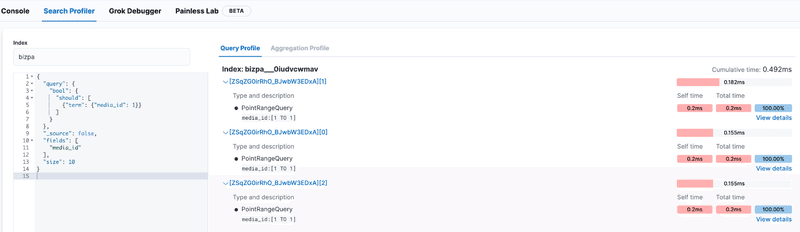
Kibanaを導入している場合、プロファイラ機能でクエリ自体を検証してみることができます。(Kibana -> Dev Tools -> Search Profiler)
実際にApache Luceneで実行されているクエリが参照できたり、クエリの実行速度が測定できたりします。
シャード数を複数設定するとそれぞれのシャードでどれくらいの時間がかかっているかも参照することが可能です。
手元にKibanaの環境がある場合は一度見てみると良いかと思います。
サンプルクエリでの例
次に、実際のサーバー負荷を見ることはとても大切だということです。
今回は、主にElasticsearchの検索パフォーマンスに着目して書きましたが、Elasticsearchに問題があると思っていたら別の箇所に問題があったという話も珍しくないと感じます。
パフォーマンスの改善をしていく中で、ボトルネックがどこにあるのかを特定することが第一ステップだと考えています。
さらに、Elasticsearchサーバーに問題があるケースであれば、クエリ自体の改善なのか、パラメータレベルのチューニングで対応できるのか、インフラのスケールアップが必要なのか。などなど
まずは実際にサーバーの負荷を見て、ボトルネックがどこにあるのかということについて調査することが大切だと考えています。
最後に
今回はElasticsearchのパフォーマンスについてでした。
検索機能があるサービスにとって、パフォーマンス問題は切り離せない問題だと感じています。
パフォーマンスが劣化したサービスはユーザーにとって大きなストレスを与えかねず、サービス全体に与える影響が非常に大きいと考えています。
そのため、データの増加やロジックの追加変更に伴いとてもシビアにチェックしてく必要がある部分だと考えています。
Elasticsearchを利用している方にとって、少しでも助けになれば幸いです。
また、ビズパは仲間を求めています!
ご興味のある方は是非、カジュアルに面談をしてみませんか。
▼採用HP
▼ご応募はこちらから!(カジュアル面談エントリーも)
▼Bizpaのことをもっと知りたい方はこちら!
この記事が気に入ったらサポートをしてみませんか?