
Opensmileとwekaを使った音声分析・音声情報処理

今回はタイトルにあるようにOpensmileとwekaを使って音声を分析していきたいなと思います。VR系の開発(Unity)をこれまで行なって来ましたが一旦離れて今回はVRに音声分析を搭載する前段階として練習がてらにOpensmileとwekaを使って行こうと思います。
そもそもOpensmileとwekaって何?
Opensmileは音声ファイルを音響特徴量ごとに数値を出力してくるものです。
基本操作はCUIで取っ付き難いかもしれませんがかなりの項目の音響特徴量を抽出してくれます。(IS09_emotion.confでは385項目ほど)
感情を分析するのに特化していて、対話ロボットを作る研究や感情の分類や推定といった研究に使われていることが多いです。
wekaは何かというと機械学習を手軽にやってくれるものでpythonでの機械学習の方が 実装という観点では優れているんですが、データの俯瞰や分析とかボタン一つでしてくれるのでいずれpythonになるにせよ、知っておく分には損はないと思います。
学習コストも大していらないと思いますがネット上には記事が少ないので個人的には苦労しました。他にも苦労してる人がいるかもなのでここに備忘録として載せておこうと思います。
音声ファイルの前処理
音声ファイルはできるだけ同じ環境で撮られた方がいいのですがそうもいかないと思います。そこでsoxが便利です。使用PCはMacを使っています。Windowsもどうやら使用できるみたいですがMacを想定して記事を書きます。ではターミナルを開きましょう。
soxのインストール
brew install sox使ったコマンド
音量調整 下のものは input.wavの音量を0.5倍にしてoutput.wavに出力するものです。
sox -v 0.5 input.wav output.wavモノラル・ステレオ変換
sox input.wav output.wav remix 1,2参考サイト:https://qiita.com/moutend/items/50df1706db53cc07f105
ここ大事
オープンスマイルでの分析をする時に音声ファイルは16bitでないと分析ができません。そのため、soxコマンドで変換します。
sox input.wav -b 16 output.wavファイル数が膨大にある場合めんどくさいですよね。
めんどくさかったので、shell軽く勉強してfor文回しました。皆さんも勉強した方がいいですよ。こんなに便利だったなんて。。。
参考サイト:https://www.sejuku.net/blog/53611
cd 処理したいフォルダ まで行ってそこで
sh sox.shで使用してください使用したいフォルダ内にこのsox.shファイルないとダメなので注意してください。
x=1
for i in *.wav;
do sox $i -b 16 "data"${x}".wav"
let x++;
donefor文でフォルダ内のwavファイルを16bitにしてdata1.wavからデータ数だけ作られます。
普通にコード内にパス名を打てばディレクトリー移動しなくていいです。以下のコードは参考までに使ってください。ちなみにフルパスの取得は、ファイル名を右クリックからの[alt/option]キーで表示されます。通常は下の画像。

Opensmile
オープンスマイルのダウンロード:https://www.audeering.com/opensmile/
zipファイルをダウンロードしてください。
Opensmileにはconfigファイルというものがあり、分析したい音響特徴によってconfigファイルを変更する必要があります。ここに関しては、はっきりとは説明できないので詳しくはOpensmileのドキュメントを読むと良いと思います。
今回はIS09_emotion.confを使いました。インタースピーチ2009年のemotion challengeというのから来ています。他にもあります。以下のサイトを参考にしてください。https://so-zou.jp/software/tech/library/opensmile/
Opensmileってどう使うの?
今回、私は音声の魅力度をそれぞれ五段階評価しました。その評価を音声ファイルに付与して機械学習したい。そんなときに役に立ちます。
opensmileはcsvファイルでの出力もできますが今回はarffファイル出力します。arffファイルはcsvファイルの進化系と思ってもらえれば結構です。arff出力するとwekaで使用できます。
SMILExtract -C IS09_emotion.confのフルパス -I input.wavフルパス -O output.arff(任意のファイル名:arff出力) 上のようなコマンドで実行します。ですがこれも一々処理するの面倒くさいのでshellで書きました。configファイルのパスだけいじってください。あとはsoxで変換したディレクトリーに行ってこれを実行するだけです。全てのデータが一つのoutput.arffに保存されます。
#印象評定の結果data1 .wavから
classes=(
4,4,2,1,4,5,3,4,4,4,4,4,2,3,4,5,2,3,2,5,3,3,3
)
x=0
for i in *.wav;
do SMILExtract
-C #configファイルのフルパス /Users/PC/Downloads/opensmile-2.3.0/config/IS09_emotion.conf
-I $i
-O output.arff -class ${classes[x]}
let x++
done今回はarffファイルにおけるclass項目は印象評定の結果を記入しました。回帰分析することで印象評定の数字を説明する変数(項目)を特定します。
Weka
wekaのダウンロード: https://www.cs.waikato.ac.nz/ml/weka/
explorer開きます。

左上のopen fileでoutput.arff開きます。

さすがに385項目では次元が多すぎるので削除して使います。選択してRemoveします。実際のデータは削除されません。項目を削除したファイルを右上で保存できます。項目ごとに分けたければ削除して保存すると便利です。
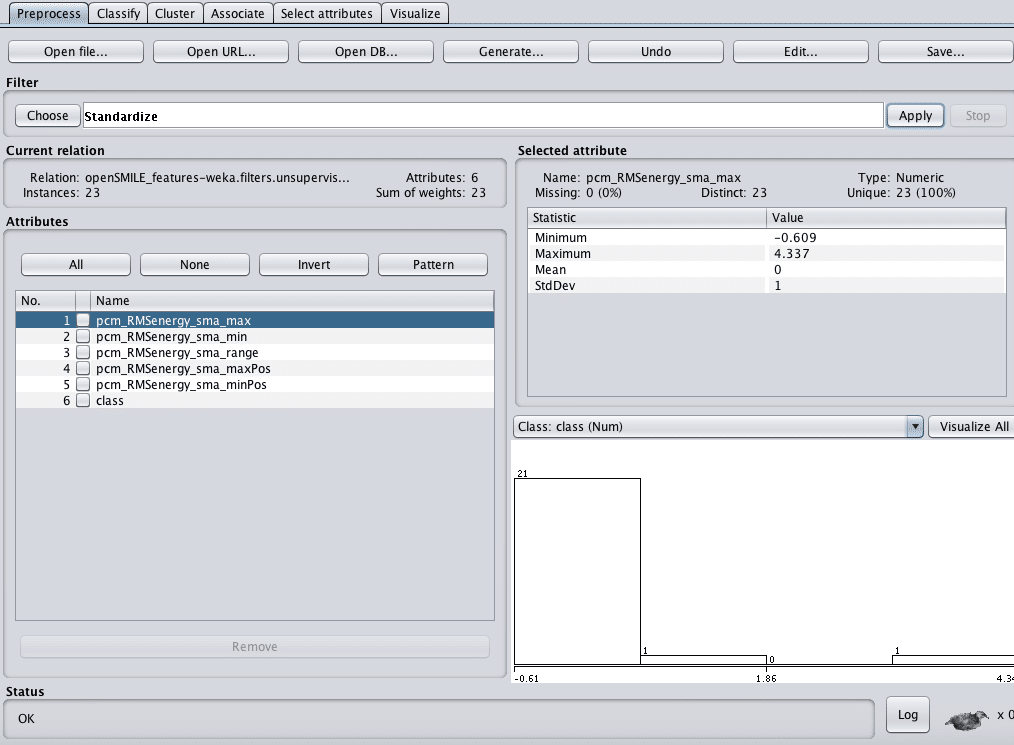
こんな感じに削除します。そして標準化します。Filters>unsupervised>attribute>standardize
Apply忘れずに
ClassifyタブでLinearRegressionを行います。

class =
0.5353 * pcm_RMSenergy_sma_range +
-0.4017 * pcm_RMSenergy_sma_maxPos +
3.3913これが回帰式です。およそこれでclassを推定できるということです。
Correlation coefficient 0.3821
Mean absolute error 0.9038
Root mean squared error 1.1713
Relative absolute error 98.093
Total Number of Instances 23 見るべきはRMSEだと思います。
Root mean squared error は、ばらつきの指標です。
人間の評価に対してモデルの評価が1程度ばらけるモデルという意味です。人間の評価が3だったら2~4の値をモデルがとるということです。5段階の評価なので、これを1以下に抑えたいところです。
Correlation coefficientは相関です。
RMSEとMSEはよく使われる指標です。上ではMSEは出ていませんが、どちらも見ておきたいところです。
他のconfigファイルでも試してみようと思います。以上が回帰分析の方法です。また更新しようと思います。他にもwekaのライブラリーではたくさんのことができます。こういう様にデータを見るのは便利です。
間違いがあれば、コメントをお願いします。
この記事が気に入ったらサポートをしてみませんか?