
二値分類の過学習対策 AIを使って日経平均株価の予測に挑戦 標準化ってどうなのよ編

前回の記事より、今後の課題を振り返る
前回は、翌営業日の日経平均株価が上がるか、下がるかを予測する二値分類に関して、学習データと評価データの隔たりによる影響を確認しました。
結論としては、データの隔たりによる特筆すべき影響を確認することはできませんでした。
壁にぶつかったので、インターネットに突破口を求めてさまよったところ、キノコードさんの動画にたどり着きました。
キノコードさん作成の動画内容を私なりにまとめると、以下のようになります。
キノコードさん作成の動画内容
月~木曜日の株価情報から金曜日の始値が上がるか下がるかを予測するAIモデルを作成する(動画11:50辺り)
各週の株価が、ある時は7,000円台だったり、またある時は25,000円台だったりするため、標準化と呼ばれる各週の株価の調整を行っている(動画16:40辺り)
AIモデルの構造はLSTMを使用している(動画17:30辺り)
作成したAIモデルの妥当性を検証するため交差検証と呼ばれる方法を実施している(動画21:20辺り)
過去の時系列データを使用して未来を予測する場合は、時系列分割による交差検証が一般的とのこと
今回作成したAIモデルはAccuracy=0.5152でした(動画25:40辺り)
ここで、私が注目したのが標準化です。
私がこれまで学習データおよび評価データに対して行ってきたのは正規化でした。
標準化および正規化とは、次の通りです。
標準化および正規化について
標準化(Standardization)とは、データの分布が中心を0、分散を1とするスケーリング手法である
正規化(Normalization)とは、データの最小値を0、最大値を1とするスケーリング手法である
私がこれまで行ってきた正規化では、日経平均株価を0~1の範囲にスケーリングしていました。
一方で、標準化では、日経平均株価を中心を0、分散を1とする分布にスケーリングします。
分布を理解するために、正規分布を例に挙げたいと思います。
下記は、正規分布を示すグラフです。
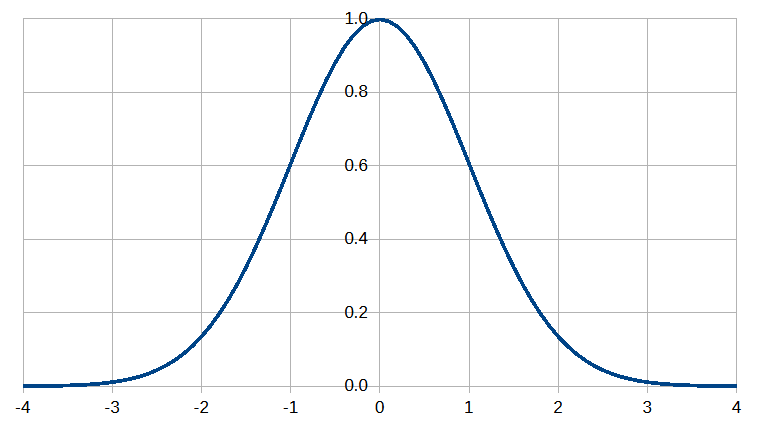
正規分布のグラフにおいて、横軸が標準偏差($${\sigma=1}$$)を、縦軸が発生確率を表しています。
標準偏差が0で最も発生確率が高くなり、標準偏差が0から離れるほど発生確率が低下していくのが確認できます。
標準偏差が$${\pm\sigma}$$に収まる発生確率が68.27%, $${\pm2\sigma}$$であれば95.45%, $${\pm3\sigma}$$なら99.73%となります。
テクニカル分析で使用されるボリンジャーバンドでお馴染みのアレです。
今回の目的は、学習データおよび評価データに対して標準化を行うことで、過学習が解決できるかを確認することです。
学習データおよび評価データに対する標準化の具体的なやり方
学習データおよび評価データに対する標準化の具体的な方法は、キノコードさんの動画に倣うことにしました。
具体的な方法を以下に記載します。
先ず始めに基となる日経平均株価のデータフォーマットについて説明します。
今回は、前回の記事で紹介したStooqを利用しました。
参照期間は、1970年1月5日~2024年1月31日です。
これで、念願だったバブル期の日経平均株価を学習データに収めることができます。
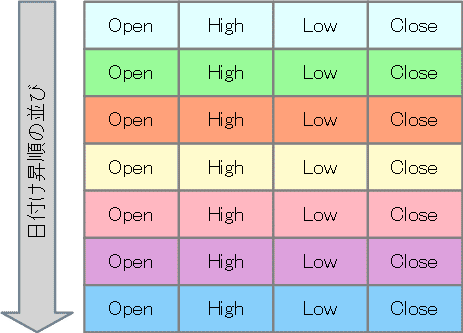
さて、ダウンロードした日経平均株価のデータを下記のフォーマットに変換します。
下記のフォーマットにおいて、Openは始値、Highは高値、Lowは安値、Closeは終値を意味します。
また、縦方向のデータの並びは、日付に基づく昇順です。
つまり、古い(1970年1月5日に近い)日付の日経平均株価が上、新しい(2024年1月31日に近い)日付の日経平均株価が下となります。
学習データ向けに、5日分のローソク足データが横に並ぶフォーマットに変更します。
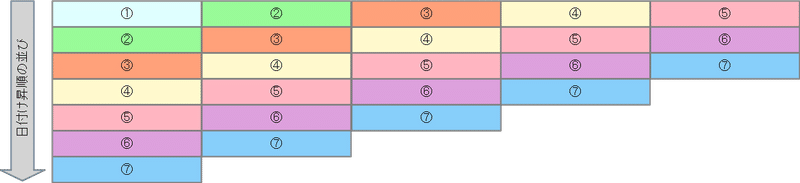
データの標準化は、5日分のローソク足データが横に並ぶフォーマットにおいて、各行を対象に行います。
例えば、1行目であれば、ローソク足①~⑤を対象にデータの標準化を行います。
続いて、標準化を行う式を以下に示します。
$$
X=\frac{x-\mu}{\sigma}
$$
上式において、$${\mu}$$は全データの平均、$${\sigma}$$は全データの標準偏差、$${x}$$が標準化を行う対象のデータ、そして、$${X}$$が標準化された後のデータです。
今回のケースでは、$${x}$$が5日分のローソク足データとなります。
Excelを使用する場合、$${\mu}$$はAVERAGE関数を、$${\sigma}$$はSTDEV.P関数を使用することで算出できます。
こうして作成したデータの前半約13,000を学習データ、後半約200を評価データとして使用します。
また、学習および評価に使用するAIモデルの構造は、前回と同じく中間層に1層Affineを使用したLSTMを使用します。
AIモデルの学習および評価を実行
標準化した学習データと評価データを使用して、AIモデルの学習および評価を実行した結果を以下に示します。
先ずは、学習曲線です。
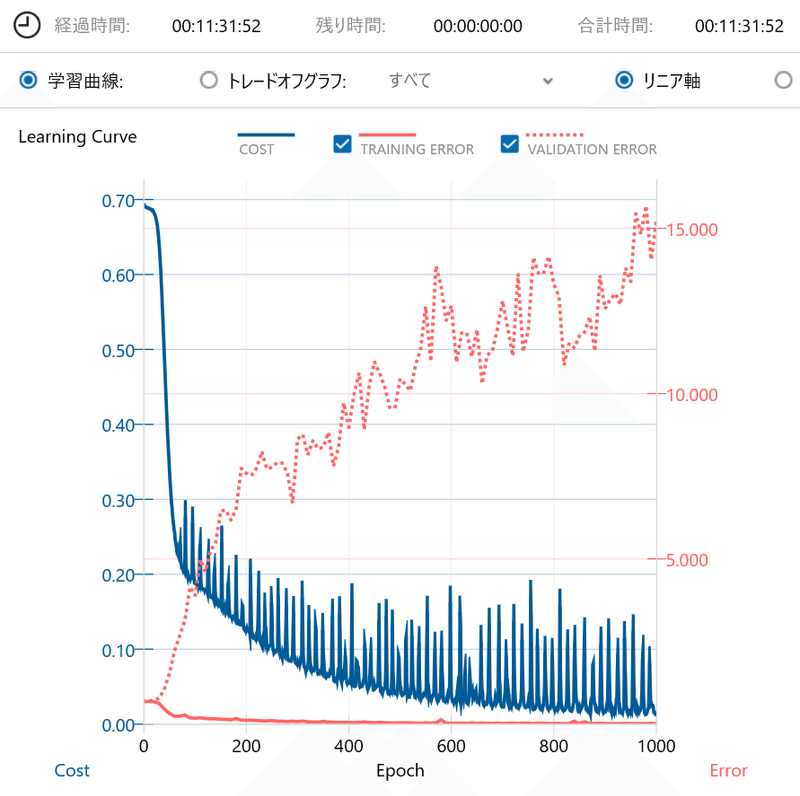
COSTとTRAINING ERRORは順調に低下していますが、VALIDATION ERRORは右肩上がりに増加していくことが確認できました。
続いて、混同行列です。
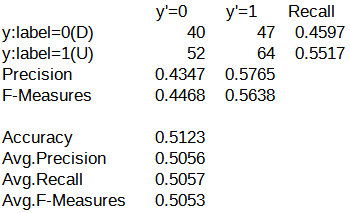
これまでの結果と比べても、特に大きな差分は確認できませんでした。
VALIDATION ERRORが右肩上がりなので、大体の予想はできたという感じでしょうか。
ちなみに、1層Affineを使用したLSTMにドロップアウトを追加した構造に対して、今回の学習データと評価データを使用してみましたが、過学習を改善することはできませんでした。
結果の考察
VALIDATION ERRORの右肩上がりっぷりが半端ないのは、正直意外でした。
今回の学習データは、5日分のローソク足データのみでしたので、学習データが不足している可能性は気になります。
キノコードさんの動画では、学習データとして、ローソク足データに加えて、終値の前日比率と始値・終値の差分を追加していました(動画10:35辺り)。
私はこれまで、SMA, ボリンジャーバンド、MACDの情報を学習データに加えてきました。
学習データにどのような情報を加えるべきかは悩ましい問題です。
感覚的には、人がテクニカル分析で必要とする情報を与えるのが良いと思います。
問題は過学習です。
現状、ローソク足データのみでTRAINING ERRORは十分低下している状態です。
このため、学習データに含まれるローソク足データに過剰に適したAIモデルが構成されてしまっていることになります。
しかし、VALIDATION ERRORは増加しているため、学習データと評価データの特徴が異なるということなんだろうと私は考えます。
そこで、どうにかして学習データに評価データの特徴を含んだデータを加えなければなりません。
どのようなデータを学習データに加えるべきか。
考えても分からないので、SMA, ボリンジャーバンド、MACDを加えてどうなるかを今後の課題とします。
また、もう一つ気になっていることがあります。
それは、AIモデルが学習データに最適化されすぎているということは、もう少しAIモデルを簡略化した構造にしても良いのではないかということです。
現在のAIモデルの構造は、1層Affineを5段の数珠つなぎにしたものとなっています。
この構造を、1層Affineを2段の数珠つなぎにしたものに簡略化したいと思います。
もともと、5段の数珠つなぎにしたのは、1週間が5営業日だからです。
そして、現状のAIモデルは、5営業日分のローソク足データを使って学習をしています。
この状態で学習データに最適化されすぎるのであれば、AIモデルの構造を2段の数珠つなぎに簡略化すれば、最適化のレベルを下げることができるのではないかという考えです。
今後の課題
学習データを、ローソク足、SMA, ボリンジャーバンド、MACDとして、標準化を行ったものを使用して、過学習の状況を確認します。
また、AIモデルの構造を、1層Affineを2段の数珠つなぎにしたものに変更して、過学習の状況を確認します。
この記事が気に入ったらサポートをしてみませんか?