
[論文解説]Finding Replicable Human Evaluations via Stable Ranking Probability

タイトル: Finding Replicable Human Evaluations via Stable Ranking Probability
学会: NAACL 2024
著者: Parker Riley, Daniel Deutsch, George Foster, Viresh Ratnakar, Ali Dabirmoghaddam, Markus Freitag (Googleの方々)
ざっくりまとめ
この論文では、人間の自然言語生成モデル(NLG)に対する評価をより安定させるために具体的な評価方法(設定)をシミュレーションを通して分析ています。その際にSRPという評価指標を提案し、導入しています。
結論は下記
出力のグループ化
同じ入力から出力されたものは全て同じ評価者が評価した方が良い(強めに推奨)
作業負荷の分配
データセットによっては不均一の方が良い場合があるが、基本的には評価者間で作業負荷は均等に分配すべき
スコアの正規化
z-score normalizationが一番良い(弱めの推奨)
出力ごとの評価数
限られた予算内でできるだけ多くの出力を評価するため、各出力に対して1回だけ評価することを推奨。
時間がない人用
以下はChatGPT(GPT-4o)が要約したものです。
この論文において解決したい課題は何?
この論文では、自然言語生成(NLG)システムの評価における信頼性と安定性の向上を目指しています。特に、評価方法が繰り返し適用されたときに一貫して同じシステムランクを生成すること(安定性)を重視し、信頼できるヒューマン評価を設定するための最適な構成を調査しています。
先行研究だとどういう点が課題だった?
先行研究では、ヒューマン評価者の評価基準が一貫していないことや、評価の安定性が低いことが課題とされていました。例えば、評価者のスタイルの好みや厳しさの違いにより、システムのランクが評価ごとに変動することが問題とされていました。
先行研究と比較したとき、提案手法の独自性や貢献は何?
提案手法の独自性は、評価の安定性に焦点を当て、評価方法が繰り返し適用された場合に同じシステムランクを生成する確率を測定する「Stable Ranking Probability (SRP)」という新しい指標を導入した点にあります。また、具体的な評価方法や設定に関する推奨事項を提供し、MQM(Multidimensional Quality Metrics)フレームワークを用いてその有効性を実証しています。
提案手法の手法を初心者でもわかるように詳細に説明して
提案手法では、以下の手順を推奨しています:
評価項目のグループ化:同じ入力文書の全システム出力を同じ評価者に割り当てる「擬似サイドバイサイド(pSxS)」方式を推奨。
作業負荷の分配:全評価者に均等に作業を分配し、評価ノイズを減少させるために明確なアノテーションガイドラインとトレーニングを実施。
スコアの正規化:評価者ごとのスコアのばらつきを抑えるために、Zスコア正規化を弱く推奨。
評価項目数の決定:評価の信頼性を高めるために、固定予算内で可能な限り多くの異なる項目を評価する。
提案手法の有効性をどのように定量・定性評価した?
定量的評価は、提案したSRP指標を用いて、システムランクの安定性を数値化しました。具体的には、システムペアのランキングの一貫性を測定し、異なる評価設定が安定性に与える影響を分析しました。定性的評価では、評価者の行動や同意度の分布を分析し、評価方法の改善点を明らかにしました。
この論文における限界は?
この論文の限界は、評価データが英語-ドイツ語および英語-中国語の二つの言語ペアに限定されている点です。また、評価者が専門家であるため、非専門家の評価者を使用する場合には推奨事項が適用できない可能性があります。さらに、異なるドメインやMTシステム、評価フレームワークに対しても同様の結果が得られるかは保証できません。
次に読むべき論文は?
次に読むべき論文として、MQMフレームワークに関連する以下の参考文献を推奨します:
Freitag et al., 2021 - "Experts, errors, and context: A large-scale study of human evaluation for machine translation"
Graham et al., 2020 - "Assessing human-parity in machine translation on the segment level"
Howcroft et al., 2020 - "Twenty years of confusion in human evaluation: NLG needs evaluation sheets and standardised definitions
研究の目的
この論文では、「人間がどのように自然言語生成(NLG)の評価を行うことで、安定的な評価が可能になるか」という問いに対して複数の観点から具体的な評価設計の推奨事項を提示することを目的にしています。
実際、本実験でも評価者間でのスコア分布の差が出ています。
ある評価者にとっては「軽いミス」でもある評価者には「重大なミス」とみなされることがあります。

「GPT-4でどのように評価させるか」という自動評価の最適化に関する論文が増えてきている中で人手評価に焦点を当てるのは面白いです。
本論文のResearch Question(RQ)は下記です。
出力はどのようにグループ化すべきか?
作業負荷はどのように分配すべきか?
各出力には何回の評価が必要か?
スコアはどのように正規化すべきか?
何個の出力をアノテーションすべきか?
実験方法
本実験では、機械翻訳のデータセットであるMQMを使用し、スコアを算出しています。約180個のドキュメントを用いて評価を行っています。
MQM(Multidimensional Quality Metrics) は、機械翻訳(MT)の人間評価に使用されるフレームワークです。専門の評価者が翻訳内のエラースパン(エラーの範囲)を特定し、それに対してカテゴリと重大度を割り当てます。例えば、「流暢さ/文法」や「正確さ/誤訳」といったカテゴリ、そして「主要」または「軽微」といった重大度です。この手法は、以前の多くの研究で用いられたリッカート方式の評価(数値スコアを直接割り当てる方法)とは異なります。MQMでは、まずエラーを注釈し、その後で重大度とカテゴリに基づいた重み付けを適用して数値スコアを計算します。そして、評価セット内のセグメントの平均スコアに基づいてシステムをランク付けします。このフレームワークは参照翻訳を使用せず、各評価アイテムは入力セグメントと単一システムからの翻訳から構成されます。
Stable Ranking Probability (SRP)とは
SRPとは簡単に説明すると、「同じ評価手法を使って繰り返し実験を行った場合、最初の実験で有意に優れているとされたシステムペアが、次の実験でも同じ順序で評価される確率」を表します。この確率が高いほど、その評価手法は再現性が高い、つまり安定しているとみなされます。

SRP(E): Stable Ranking Probability
E: 共通の評価手法を用いた研究のセット
pi_2(E)はEの中から2つの研究を選んでペアにする全ての組み合わせの数
SR(e1, e2): 研究ペア(e1, e2)の安定性
研究e1でシステムsiがsjより優位に優れている場合、研究e2でも同様にsiがsjより優れている時に1, そうでなければ0を返す。
SBe1, Be2はbool関数。
SRPは、ある研究で「有意に異なる」とされた出力のペアが、次の研究でも同じ順序で評価されることを要求しています。これは、単にランキングが同じであればよいというわけではなく、統計的に有意な差がある場合に、どちらが優れているかが一致していることを求めるという点で厳格な指標となっています。
SRPのもう一つの利点は、それが「確率」として表現されるため、解釈が簡単です。例えば、SRPが0.8であれば、「80%の確率で再評価しても同じランキングの方向が得られる」という意味になります。これは直感的に理解しやすい指標です。
シミュレーション
かなり長くなりそうなので、RQに沿って簡単に列挙させてもらいます。
出力はどのようにグループ化すべきか?
疑似サイドバイサイド(pSxS):同じ入力ドキュメントからのすべての出力がグループを形成し、同じ評価者によってアノテーションされます。
例: 入力1を用いたGPT-4, Claude3, …の結果を全て同じ人がアノテーションを行う
システムバランス:各システムの1つの出力からなるグループが形成され、同じ評価者によってアノテーションされますが、出力は異なる入力ドキュメントからのものでも構いません。
例: GPT-4が出力した結果(入力1, 2, 3…)を全て同じ人がアノテーションを行う
作業負荷はどのように分配すべきか?
完全に均等:アイテムは評価者間でできる限り均等に分配されます。
エントロピーバランス:0から1のエントロピー目標値を持ち、評価者間の作業負荷分散の正規化エントロピーが指定された目標値に近づきます。
各出力には何回の評価が必要か?何もいい感じの結論が出されてなかったので割愛
スコアはどのように正規化すべきか?
非正規化:正規化は行いません。
平均正規化:各評価者の平均MQMスコアが全評価者で同じになるように各スコアに乗算します。
エラー正規化:エラーの総数に比例してスコアを調整します。
Zスコア正規化:各評価者の平均スコアを各スコアから引き、標準偏差で割ります。
何個の出力をアノテーションすべきか?
単一評価:各アイテムは1回評価されます。
二重評価:各アイテムは異なる2人の評価者によって評価されます。
結果
ざっくりまとめで挙げられている結果と同じです。
出力はどのようにグループ化すべきか?
pSxSが良かったです。つまり、同じ入力から出力されたものは全て同じ評価者が評価した方が良いということです。
このグループ化を本論文では強く推奨しています。

作業負荷はどのように分配すべきか?
基本的に均等に分配するべきです。ただし、データセットによっては不均一に分配を行った方が良い場合があるそうです。
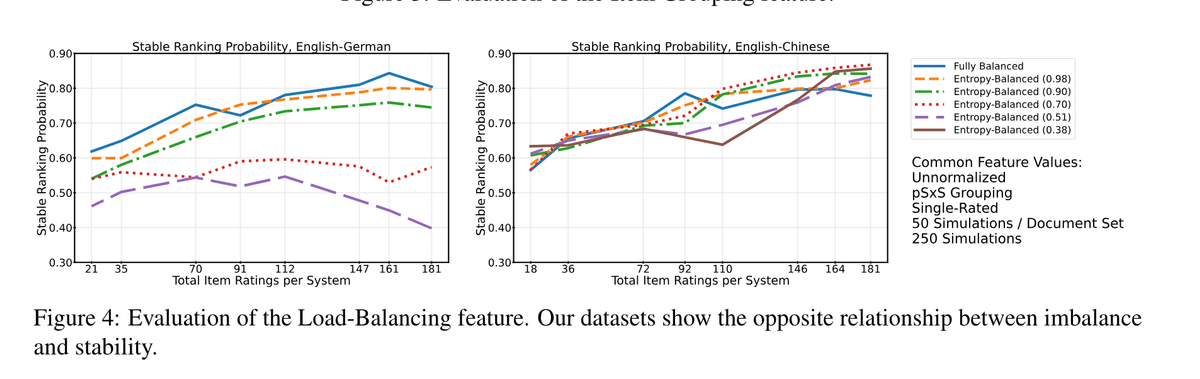
各出力には何回の評価が必要か?
1回です。異なる人同士で2回評価する方よりも安定していました。これは驚きです。普通に考えて2回評価を行うとアノテーションの依頼料が2倍になりますから、1回の方が安定しているなら1回を選択するしかないですね。

スコアはどのように正規化すべきか?
Zスコア正規化が一番良いです。ただし、たいして変わらないので弱い推奨となります。

この記事が気に入ったらサポートをしてみませんか?