
[論文解説]評価者としてのLLMはバイアスを持っていていて一貫性がない

はじめに
昨今、LLMの評価にLLMを用いることが増えています。
そんな中で、評価者としてのLLM(以後、LLM評価者)をバイアスや一貫性という観点から分析を行っている論文を読んだので少しだけブログという形で紹介します。
Large Language Models are Inconsistent and Biased Evaluators
著者
Rickard Stureborg(Grammarly), Dimitris Alikaniotis(Duke University), Yoshi Suhara(NVIDIA)
学会,ジャーナル
arXiv
年
2 May 2024
5月2日の論文ということで、採れたてほやほやですが、査読などが通っているものではないので、そこら辺はご了承ください。また、この記事では簡単な概要にしか触れませんので、詳細は論文を直接ご確認ください。
実験設定
この論文は評価者としてLLMがどのくらい有効か、という視点から要約に対する評価をGPT-3.5, GPT-4で行った結果を分析しています。
また、有効か否かを示す指標としては人間の専門家が評価を行った結果との相関などを用いて評価しています。
つまり、人間の専門家の評価とLLM評価者の評価に高い正の相関が見て取れればLLM評価者は優秀ということになります。
データセット:SummEval ( https://arxiv.org/abs/2007.12626 )
評価観点
Coherence(首尾一貫性):要約内の文の総合的な質
Consistency(一貫性):元のテキストとの事実的な整合性
Fluency(流暢さ):個々の文の質
Relevance(関連性):選択された内容の適切さ
3つのバイアス
論文では主に3つのバイアスがあったと触れています(その他の細かい点も論文の中で触れています)。
親しみバイアス(Familiarity Bias)
親しみバイアスとは、LLMが低いPerplexityに対して高い評価を行っていることを指しています。Perplexityが低いというのはLLMが予想しやすい、わかりやすい文章と捉えられると思います。
図1を見ると、Perplexityが高くなるにつれLLMが与える評価も下がっているのが見て取れると思います。また、図1では人間の専門家も同様の傾向を示していますが、表1のドキュメントに対してのPerplexityを見るとLLMは同様にPerplexityが高くなるにつれ低い評価を与えていますが、人間の専門家はそのような傾向が見られませんでした。
このような傾向から、LLMは低いPerplexityの文章に対してバイアスを持っていることが考えられます。
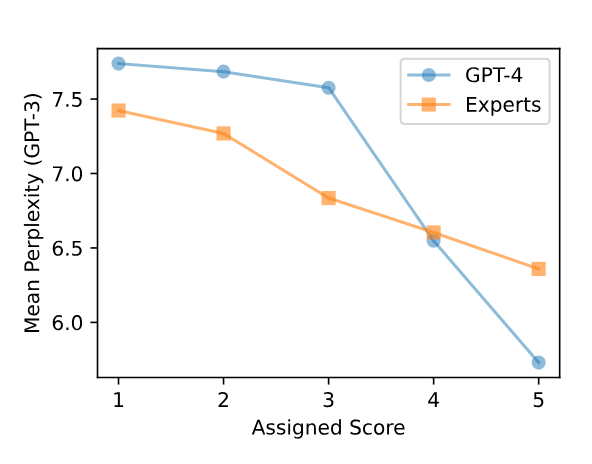
GPT-4ではPerplexityが低いものになると高得点をつけやすい。

GPT-4はdocumentに対するPerplexityにも同様にPerplexityが低いものに高得点をつけている。
スコアバイアス(Score Bias)
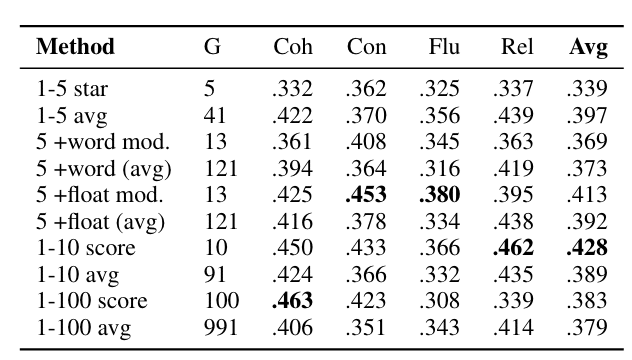
2つ目はスコアバイアスです。一般的には評価スケールは1~5となることが多いですが、自動評価のためにスコアを生成する場合、候補間の同点は望ましくありません。
そのため、スコアスケールを1~100とし、評価を行いました。
その結果、特定のスコア(例:90や95など)に不釣り合いな確率を割り当てており、正当な評価が行えていませんでした(図2)。
GPTは80, 85などのキリの良い数字を割り当てることが多く、81, 82などの微妙なスコアをつけることが少なかったです。

今回のSummEvalでの実験では1~10の評価スケールが最適であることがわかりました(表2)。
アンカリング効果
最後はアンカリング効果です。アンカリング効果では、その名の通り最初に評価したものが後の評価に影響を与えてしまっています。
具体的には、GPT -4が複数の評価観点(Consistency, Fluency, …)を評価する際に、最初に評価した観点のスコアが、その後に評価する観点のスコアに影響を及ぼしています。
この傾向は一般的に思えます。全体として評価が高い->流暢という関係は自然なことです。
しかし、評価順序の影響度合いが大きすぎると論文で指摘しています。
人間の専門家ではConsistencyとFluencyでのピアソンの順位相関係数が0.315なのに対して、GPT-4は0.979と非常に高くなっていることがわかります(図3)。

前のConsistencyのスコアに依存していることを示している
また、Coherence(全体的な評価)を最初に行うか否かで人間のスコアとの相関が変わると言及されています(表3)。

これらの結果はGPT-3.5, GPT-4を用いた結果ですので、他のLLMへどこまで一般化できるかは分かりませんが、LLM評価者に複数のバイアスがあることがわかります。
おわりに
皆さんはここまで読んでみてどのように感じましたか?
自分はこの論文を読んで「人間と同じようなバイアスをしっかり持ってるんだな〜」と感じました。
Perplexityが低いものに高い評価をつけることは、人間がわかりやすい要約に高い評価点をつけることのように思えて、至極一般的な挙動に見えます。
スコアバイアスについても、人間も同様に5点刻みの90, 95点などに高い確率でスコアを割り当てると思います。
アンカリング効果も言うまでもなく人間が持つバイアスです。
自分は、これらのバイアスが問題ではない、と言っているわけではないです。実際に、人間の専門家よりも評価のパフォーマンスが低く出ているので、問題ですし、改善の余地はあると思います。
また、これら3つのバイアス以外にも様々なバイアスはLLMにも人間にもあると思います。今後はこう言った部分の研究が増えてくると思うので、キャッチアップしたいですね〜。
今後もInputをこのように紹介していきますのでフォローお願いします〜!
この記事が気に入ったらサポートをしてみませんか?