
stable diffusionの「ComifyUI」を使って、「SDXL」モデルの画像生成をしてみた

先日からstable diffusionの「ComifyUI」を使い始めて、少し慣れ始めたところで、今回は「SDXL」モデルを使って画像生成を行いたいと思います。
「SDXL」モデルをまだ持っていないという方は以下の記事を参考に「SDXL」モデルをダウンロードしてお試しください。
「SDXL」モデルはあるけれど、「ComifyUI」がないという方は以下の記事を参考に「ComifyUI」を導入いただければと思います。
それでは早速始めたいと思います。
SDXLモデルでシンプルに画像を出力する
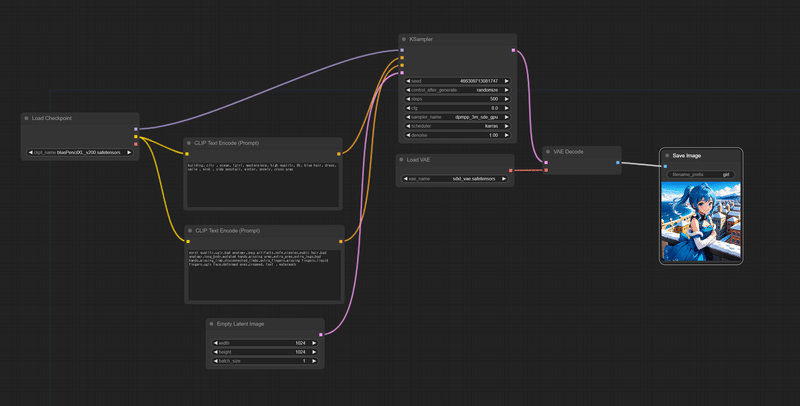
ここからはノードを「SDXL」出力時のものに変えていきます。
初期のノードは以下のような状態から進めます。
もしも拡張機能の「ComfyUI-Custom-Scripts」を導入されている場合は以下のjsonファイルを「Import」していただければ簡単に行えます。

①refrinerモデルの追加
何もないところで、「右クリック」→「Add Node」→「Load Checkpoint」を選択します。
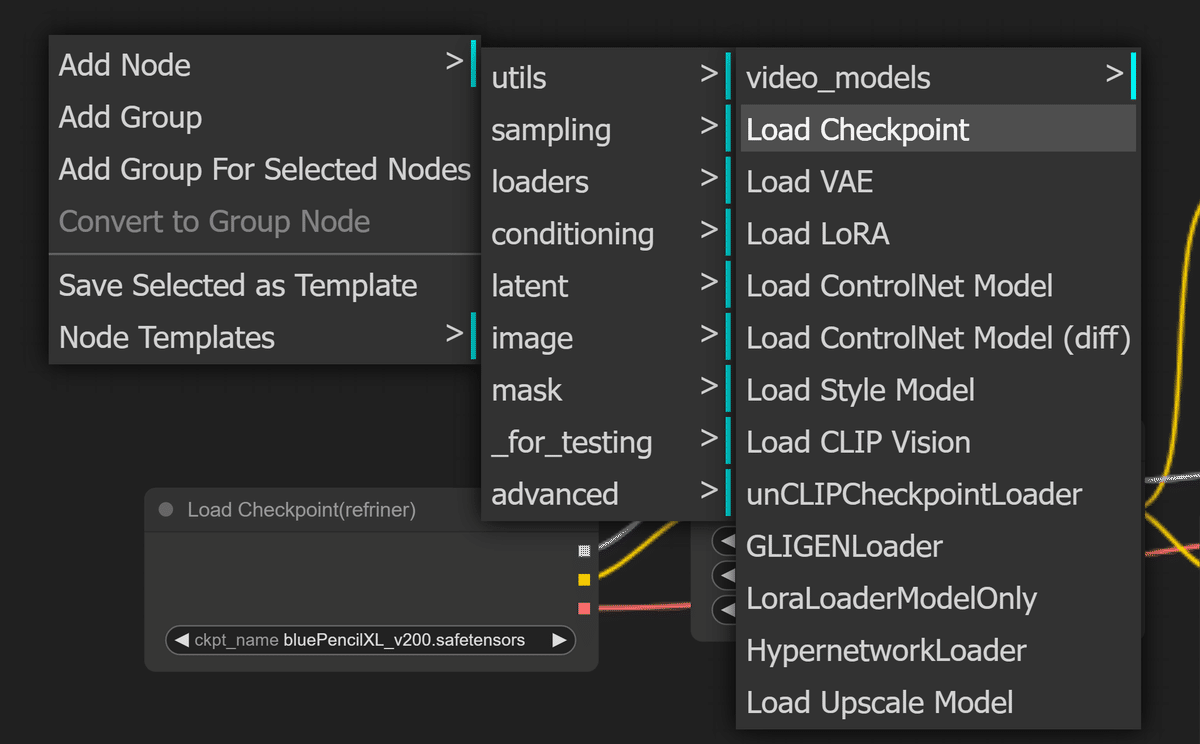
「Load Checkpoint」が出てくるので、「ckpt_name」を選択して、「refriner」モデルを選択しましょう。

ノードの上で右クリックをすると「Title」という項目があります。
これを変更するとノード上部の名称を変更することができるので、通常のモデルと判別ができるように名前を付けておきましょう。

②プロンプトの追加
「refriner」のプロンプトを追加します。
追加する方法は大本のモデル(Checkpoint)のプロンプトをコピーします。
やり方はノードを「左クリック」して、「ctrlキー」+「Cキー」を押して、「ctrlキー」+「Vキー」を押すと、選択したノードがコピーされます。
ポジティブプロンプト、ネガティブプロンプトをコピーしたら、「refriner」モデルの「CLIP」に接続します。

②-EX loraの追加
「lora」を利用する場合は「Load Checkpoint」とポジティブプロンプト、ネガティブプロンプトの間に「lora」を接続します。
「lora」が何かわからない方は以下の記事をご参照ください。
「lora」のノードは何もないところで、「右クリック」→「Add Node」→「Load Lora」を選択すると追加できます。
追加後は「Load Checkpoint」と「lora」の「CLIP」を接続し、「lora」の「CLIP」とポジティブプロンプト、ネガティブプロンプトの「CLIP」を接続します。

「refriner」と「大本のモデル」2つとも同じように接続し、同じ「lora」を選択しておきましょう。
③KSamplerのつなぎ方
まずは右クリック→「Add Node」→「sampling」→「KSampler」を追加します。

「KSampler」が追加されたら、以下のように接続します。
MODEL 「Load Checkpoint」→「KSampler」
positive 「prompt」→「KSampler」
negative「prompt」→「KSampler」
latent Image「KSampler(大本モデルの方の)」→「KSampler」


④VAEの追加
「VAE」を設定するためには、「LOAD VAE」というノードを追加する必要があります。
何もないところで、「右クリック」をしてノードメニューを表示します。
ノードメニューから「Add Node」→「latent」→「VAE Decode」を選択します。
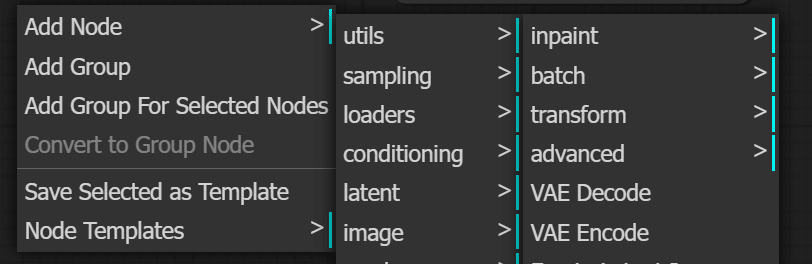
「VAE Decode」が追加されたら、以下のように接続します。
samples 「KSamplerのlatent」
vae 「Load Checkpointのvae」

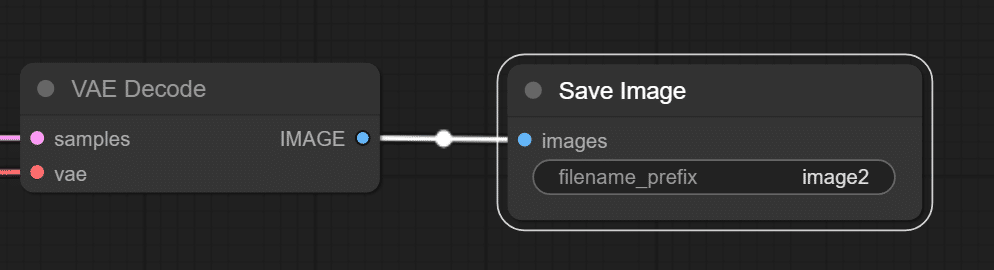
⑤save Imageの追加
すでに存在する「save Image」をコピーしてノードを追加し、「VAE Decode」の「IMAGE」と接続します。
これで準備完了です。
ワークフローは以下のようになりました。
※大本のモデルにも「Save Image」があるのは、通常の生成パターンと比較するために追加してあります。
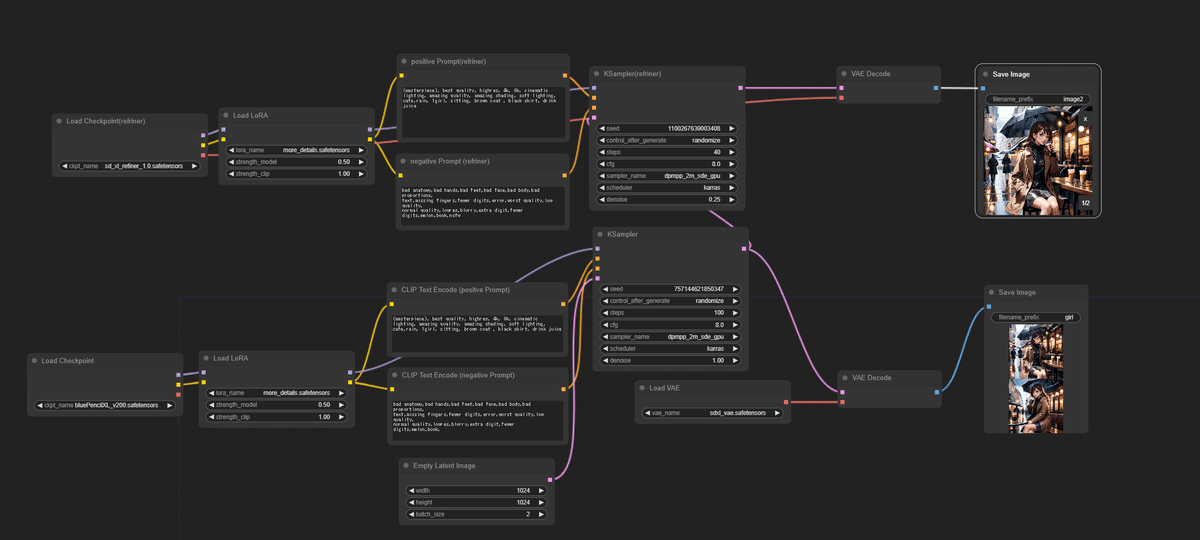
早速画像を生成してみましょう。
refrinerモデル利用時との生成結果比較
「SDXL」モデルで「refriner」モデルを使った時と一般の時でどのくらい画像に差異が出るのか見てみましょう。




一見すると両方とも同じように見えますが、顔が若干違いますよね。
後、2枚目の画像の「refriner」なしのパターンは口紅がはみ出していますが、ありのパターンは修正されていますね。
①refrinerのsteps数とdenoiseを高めにして生成してみた
steps数は20が大体の適正値ですが、大きくしたらどうなるのかワクワクしませんか?
まずはsteps数を以下のように設定してみます。
両方ともsteps数は「500」でやってみます。
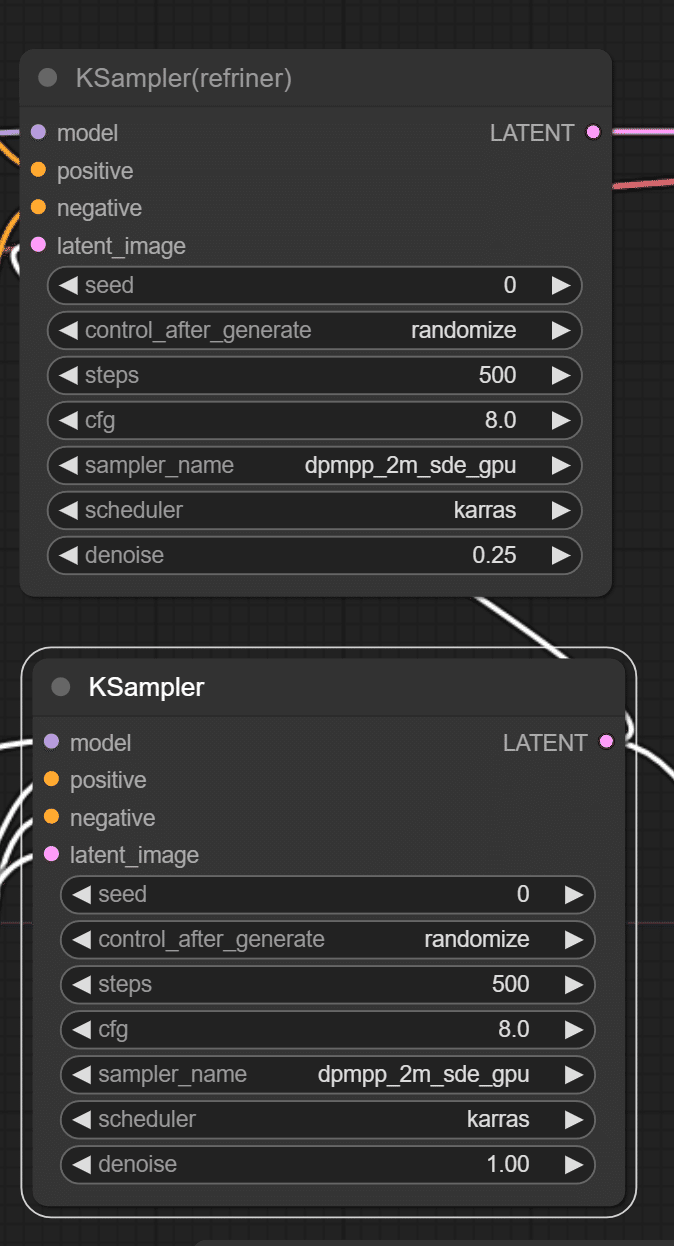


2枚の画像を比べるとrefrinerアリの場合は目の崩れがなくなっているのと、ワンピースの結び目の先の崩れが無くなっていますね!
時間かかるだけで崩れると思っていたので、面白いですね!
次は「denoise」を増やしてやってみます。
最大の1にしてみました。



全くの別画像になってしまいました。
「refriner」の「denoise」を大きくするとイラストの形式に大きく影響を与えるので、似ているけれど異なるものを出したいときには値を大きくするとよいのかも…。
②steps数を最大にして生成してみた
通常モデルもrefrinerも最大数の「10000」にして生成してみます。
どうなるんでしょうか…ドキドキ。
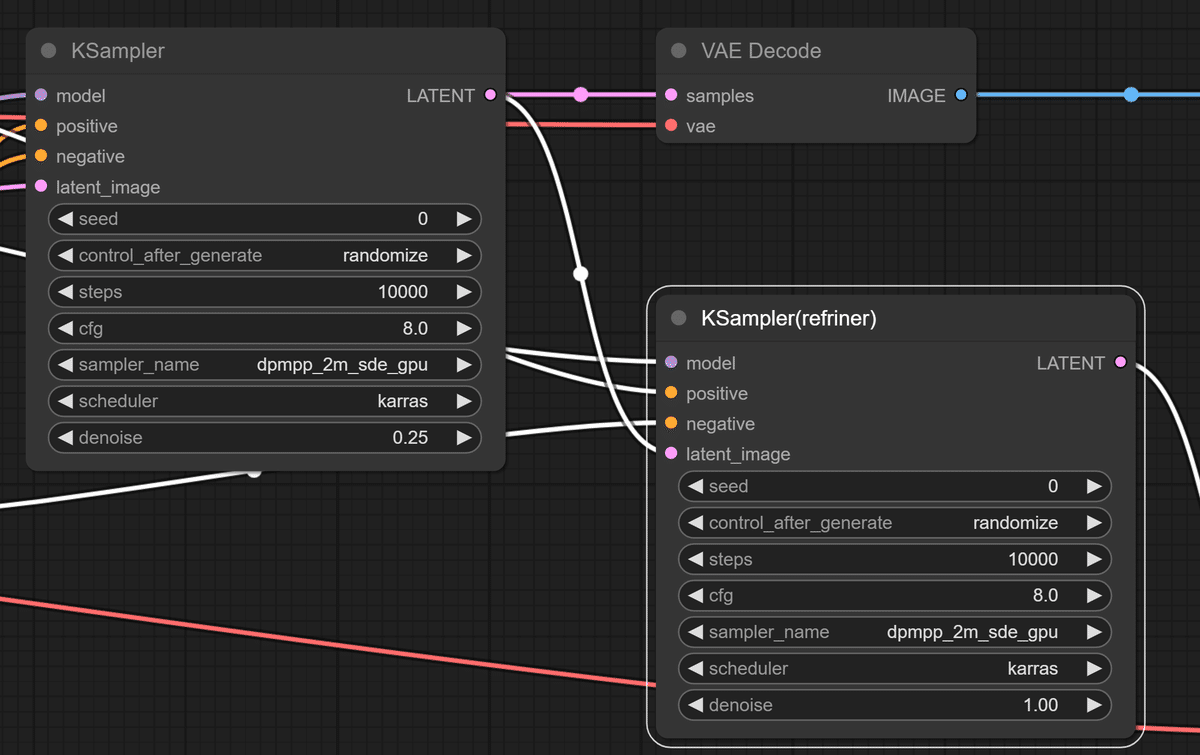
結果はグレーの四角と頭の上から女性の頭が生えている恐怖画像になってしまいました。
やっぱり適正値でやるのが一番ということですね!


やってみた感想
「SDXL」モデルは高画質で見ていて飽きないですね!
どんどん色んな機能や手法を学んで、生成できる幅を増やしていきたいと思います。
そして、「SDXL」モデルが利用できるようになったので、ようやく「animate diff」を試すことができます。
「animate diff」についても記事を書く予定ですので、そちらもよろしければご覧ください。
それでは良き創作ライフを…!
この記事が気に入ったらサポートをしてみませんか?