
【医学生〜初期研修医向け】次郎作による英語論文読み解き講座〜RCT編〜

こんにちは、次郎作こと布施田泰之です。
医学生時代から続けている”次郎作ブログ”(https://fuseda.xsrv.jp/wp/)や、
医学書や医学参考書のレビューを集めている”医学書レビュー.com”(https://igakusho-review.com/)というサイトを運営しています。
また、医師としてのキャリアとしては、現在医師5年目で国立成育医療研究センターという小児病院で後期研修をしています。
今年で小児科専門医は取得できるので、
来年4月からは元々勉強したかった「公衆衛生学」を学んでMPHを取得するために、東京大学の大学院に進学します。
そういった興味もあって、僕は初期研修医の時から、
英語論文を読み解くための参考書や、実際に英語論文を果敢に読むようにしていました。
また、医師3年目からは最低でも月1回は抄読会のような形で先輩からのフィードバックを受けながら英語論文を読み続けていたので、多少はMethodの部分も含めて英語論文の質が読み解けるようになってきました。
しかし、
最近は「自分だけが論文を読めるようになるだけじゃ意味がない」と思い、
読んだ論文の日本語要約を作成してブログやサイト上で公開したり、
後期研修の後輩でこれまで英語論文に馴染みがなかった数人に対して、一緒に同じ論文を読んで、僕が作成したスライドを用いて知っておくべき知識を説明したりしています。
その後輩へ行っている「英語論文の読み解き講座」を、note用に改変して公開しようと思います!
基本的には無料で公開しますが、
内容が充実してきたら医学書レビュー.comの企画として有料コンテンツになるかもしれません・・・
今のうちに読んでおいてください!笑
第一回「論文読み解き講座」

では、今回は後輩が選んでくれたこの論文を軸に、色々と説明していきます!
理想は、一緒に英語論文を読んでもらうことなんですが、今回は↑の日本語要約を読んでもらっておくと良いと思います。
今回は、エビデンスレベルも高く、実は読みやすい、
RCT(ランダム化比較試験)の論文から勉強していこうと思います。
では、作成したスライドを用いながら説明していきます!
読むべき英語論文の選び方
実は、英語論文を読み始める時に一番最初に問題になるのが、
「なんで、英語論文を読むの?」
「どうやって読むべき英語論文を探してくるの?」
というところです。
特に抄読会はあるものの、どの論文を読もうか迷うことはよくあると思います。

「読むべき英語論文」に関して、
僕は↓このように考えています。

おや、「カッコつけんな」「意味不明」という声が聞こえてきますね笑
しかし実際に後期研修医になると、教科書や参考書には書いてないような臨床の問題にぶつかることがあります。
例を挙げてみます。

急性巣状細菌性腎炎(acute focal bacterial nephritis,以下 AFBN)の小児がいて、いつまで静注で治療しきろうか迷っていた時に2006年のPediatricsの論文を読んでみたところ、内服治療で再燃例がいなかったので解熱後すぐに内服に切り替え3週間治療し切りました。
こういう風に臨床医の立場では、「明日からの自分の臨床行為や臨床判断を変えうる論文」こそが読むべきで、吟味すべき論文だと思っています。
まぁ、ここら辺はみんな興味がないと思うのでサラッと書いて、
次は論文の探し方です。
論文の探し方

けっこうみんな最初からPubMedで面白い論文・役に立つ論文を探してこようとしますが、意外と検索に慣れていないと星の数ほどある論文から質の高い論文を探すのは難しいです。
uptodateで探してくる方法や、その分野で有名そうな論文のintroductionなどで引用されている論文を読んでみる方法、なども有用な時が多いのでオススメです。
読むべきか判断するための「ナナメ読み」
それっぽい論文が見つかりました!
次の瞬間、頭から一語一句読んでいこうとしていませんか?
その前に一度、さらっとナナメ読みをして、
本当に読み込むべき論文か判断するようにしましょう!
論文を読み切ってみて初めて「全く興味深くなかった・・・」となった経験がある人も多いと思います笑
上手なナナメ読みの方法を習得しましょう!
まずはタイトル

PICOは有名なので説明はいらないかもしれませんが、臨床の論文(特にランダム化比較試験)を構造化して理解しやすくするために有用です。
P (Patient):今回の研究で対象となる患者の特徴
I (Intervention):研究による介入の方法
C (Control):介入に対して、比較対象について
O (Outcome):結果として測定するアウトカム
PICOを用いて整理してみましたが、タイトルだけでも上のスライドのようにとても多くの情報が得られます。
Pubmedなどで論文を調べる際に意識すると良いと思います。
次にアブストラクト

次に、アブストラクト(抄録)を読みます。
正直、この要約を読めば論文のほとんどのことが分かります。
スライドでは、PICOを埋めてみましたが、このアブストラクトだけでかなり鮮明に論文の内容が分かるようになったと思います。
そして、「図表」をチラ見してナナメ読みは完成します!笑
図表をチラ見
Figure 1.はランダム化割付のフローチャート

今回のテーマはRCTなので、RCTでの基本的なお作法についても勉強しながら進みましょう。
スライドのようなフローチャートのような物をよく論文で見かけませんか?
実はこれ、RCTの報告の仕方に関するガイドラインである「CONSORT声明」というとても有名なガイドラインで記載があり、フローチャートを掲載することを強く推奨しています!
この図をみて、研究から脱落していっている患者数が多くないか(一般的に、脱落者が多いとバイアスがかかってしまうと言われています)、
介入群と対照群で脱落者に差がないか(恣意的な判断が入っていないか)、
などを確認します。
Table 1. は「研究対象者の特徴」を示す

次に、表1ですが、基本的に「研究対象者の特徴」を示す表が掲載されていることが多いです。
一応、RCTがうまくいっているのか介入群と対照群で差がある項目が出てしまっていないか確認します。また、自分が知りたいような患者群に対する論文かどうかも確認してください!
(小児科医の場合、年が成人以上だったり喫煙者だったりが対象の研究はあまり参考になりません)
Table 2.は「研究の命」(のことが多い)

大体、Table 2.くらいで研究で一番言いたい結果を持ってきます。
しかし、figure(図)でインパクトある結果を持ってくる論文もあるので、一概には言えませんが、ここら辺のタイミングで配置されることは覚えておいて良いと思います。
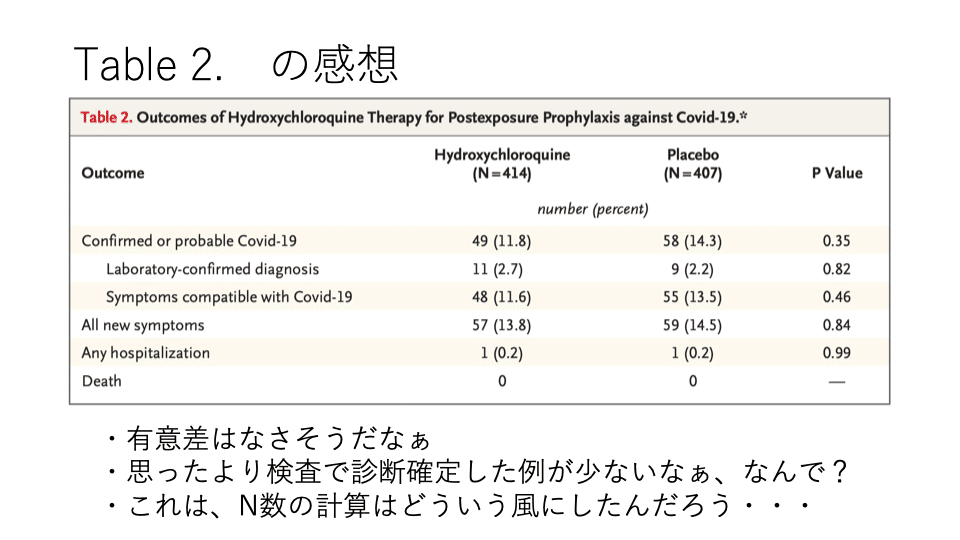
↑このように、アブストラクト+図表をナナメ読みしながら、研究の内容でもっと知りたいことを考えていきます。
この表で、僕が思ったのは、
・検査でCOVID-19の診断している例が少ないのはなんでだろう?
・N数の計算と、症例数は足りてるのかな?(COVID-19のRCTはサンプルサイズ計算をしても、研究開始後の流行具合でN数が足りない論文も散見されたため)
という点です。
Table 3.などは研究ごとの独自の図表

最後の方の表では、副作用に関する情報が並べられることも多いです。
興味があるなら読んでみよう!

ここまで、論文をナナメ読みするだけでもかなりの情報を得られたと思います。
正直、ここまで読んで全文までは読まないことも結構あります。
ただ、ここまで読んで、
「めっちゃ面白い結果じゃん!」
「え、この部分は実際研究ではどうしてるの?」
「結果すごいけど、Method問題ないのかな?」
などと思えば、その論文を全文読んでみることをオススメします!
ここまでが、
「どの論文を読むべきか、論文の選び方・ナナメ読みの仕方」でした。
さて、ではこの論文をしっかり読んでいきましょう!
ランダム化比較試験(RCT)の読み方

New England Journal of Medicineに2020年の8月6日に掲載された論文です。
ランダム化比較試験と観察研究の違いは?

まず、そもそもの話ですが「ランダム化比較試験は、なぜエビデンスレベルが高い」のでしょうか?
1つは、介入群と対照群をランダムに割り付けることで、交絡因子の影響をほぼ皆無にして、純粋に治療と対照との比較をできるからです。
そのため、結果の解析はシンプルな単変量解析のみで済むことが多く、
圧倒的にMethodが読みやすいです!
個人的には、エビデンスレベルも高く読みやすい、ランダム化比較試験(RCT)の論文から読み慣れていくことをオススメしています。
実は、観察研究の方が研究の質を評価するのが大変です。
ITT解析とper protocol解析

RCTの解析の方法にはITT解析とper protocol解析というものがあります。いきなり本文に出てきたりするので、押さえておきましょう。
基本的にRCTではITT解析(Intention to treat解析)をするのが理想とされています。
ITT解析とは、ランダムに割り付けた通りの介入群と対照群で解析を行うことです。対照群の患者が勝手に治療を行ってしまったり、介入群の患者が勝手に治療をやめてしまっていても、最初に割り付けた介入群と対照群で解析を行うんです。
なぜ、こんなことをするのでしょう?
①ランダムに割り付けたままの群間で解析するので、理論上もっとも両群が均一となっている状態で理想的だから
②バイアスの入る余地をなくすため
ということが言われています。対照群だけ、lost to follow-up(研究からの脱落者)が異様に多い研究などは、確かにバイアスが入り込んでしまいますよね。
それでは、実際に治療を受けた群と治療を受けてない群で比較するper protocol分析は何故存在しているのでしょうか?
それは「治療効果がみたい」からです笑
研究している方からすれば、最終的にちゃんと治療した人たち vs 対照群、で比較できる方が実際の治療効果を反映していると考えたくなるし、それが一理ある研究デザインもあります(副作用を見る時などです)。
イメージとしては、
「ITT解析で有意差が出ていれば文句なし、per protocol解析をしているならなぜそうしたか理由を読もう」って感じです。
RCTの細かいテクニック

「置換ブロック法(permuted-block method)」と「層別化(stratification)」もよくRCTの論文に登場します。
意味がわからないと面食らいますが、原理さえ知っていれば、なんてことはありません。
置換ブロック法:単純にランダムに割付をしていくと、両群に割り付けた人数が偶然偏ってしまうことがあるため、それを防ぐために数人ごとのブロックごとに割付を行う方法です。どのタイミングで研究が終わっても、両群に割り付けられた人数が大きくずれることはありません。
欠点としては、例えば4人のブロックだった場合、最初の二人が介入群に割り付けられた時に、次の二人が対照群に割り付けられることが予想できてしまうことがあります。
層別化:ランダム化比較試験は基本的に介入群と対照群の特徴が最終的には均等に割り振られていくことが強みですが、それでも偶然両群の特徴に差が出てしまうことがあります。そのため、事前にoutcomeに影響を与えてしまうことがわかっている要素(この論文では、治療した国)で、予めグループを分けて確実に均等になるようにランダム化をしていきます。
RCTのサンプルサイズ計算

上記したようにRCTは、画一的な手法のためMethodの内容に頭を悩まされることは少ないです。
しかし、今回のような新型コロナウイルス感染症に対するRCTでは、未知の情報が多かったためにサンプルサイズ計算が、論文を読み解くためにキーとなることが多々ありました。
ちゃんとした根拠を持ってサンプルサイズ計算が行われているか、
そして、ちゃんとサンプルサイズ計算通りの研究が行われたか、
最後に、サンプルサイズ計算通りではなかったときは、理由はなぜなのか、
を意識して読むと良いです。
RCTのサンプルサイズ計算のために必要な数字

サンプルサイズ計算は、実はそんなに難しい計算はしていません。
スライドに書いてあるような4,5個の情報があれば、誰でもサンプルサイズ計算をすることができます。
まずは、①のαエラーについて、大事なのでご説明します。
αエラー、βエラーって?

αエラー(Type I error)とか、βエラー(Type II error)という名前は聞いたことあるでしょうか?
分かりやすく言うと、
αエラー=冤罪
βエラー=真犯人を取り逃がす
というイメージです。
言葉で書くと、
αエラー(Type I error):本当は「差がない」のに、仮説検定で「有意差あり」と判定してしまう誤り。
βエラー(Type II error):本当は「差がある」のに、仮説検定で「有意差なし」と判定してしまう誤り
となります。
「効果がない薬」が、研究で偶然「有意差あり」と判定されて、世の中に出回ってもらっては困りますよね。このミスがαエラーです。
つまり「罪を犯していない人」が「有罪判決」される冤罪のイメージです。これは、医学界では比較的厳しい基準でこのミスを起こさないようにしています。
その厳しい基準が一般的に「5%」です。p=0.05が有意差があるかないかの基準なのは、ここからきています。
少し脱線しますが、それでは「なぜ5%、p値は0.05」なのでしょうか?
実は、これはただの感覚です。慣習です。
p = 0.05という基準は、「20回に1回しか起こらないミスなら許容できるよねー」「そうだねー」「それくらいでいいよねー」という共通認識にすぎないです。
初期研修医の先生が大好きなp値0.05による有意差の有無の判断は(僕も昔は有意差警察でした笑)、
「そもそものp値の基準自体はゆるふわ」なんです。
最近のEBMの流れで、なぜか誤解されている部分なので詳しく説明しました。
さて、αエラーは、p値という数字に化けて論文に登場しました。
βエラーは、どうやって論文に登場するでしょうか?
答えは、「検出力(power)」というワードで登場します。
さっき、サンプルサイズ計算に必要な数字の②にも検出力というものがありましたね。
βエラー(Type II error)は、本当は「差がある」のに、仮説検定で「有意差なし」と判定してしまう誤りです。
つまり、「βエラーを起こさない確率」=「本当は差があるものを有意差ありと正しく判定できる確率(=検出力)」なんです!
これで、「検出力=100% ー βエラーの確率」という計算式の意味がわかったと思います。
検出力は一般的に、80-90%に設定します。
言い換えると、βエラーは10-20%まで許容していることになります。
「本当は差がある」のに「有意差なし」としてしまうミスは、10-20%くらいまでなら良いよねとみんなが思っているということです。
これは「真犯人がいる(効果がある)」のに「捕まえられない(有意差がでない)」ので、
真犯人を取り逃がす!と表現したのでした。
この論文での実際のサンプルサイズ計算

それでは、実際の計算を見ていきましょう。
①と②に関しては、先ほど述べました。
③の発症率などの数値に関しては、「先行研究を踏まえて妥当な数字」とする必要があります。
また、④の予想される改善率に関しては、「臨床的に意味のある数値」とする必要があります。
⑤フォローの離脱率に関しても、フォロー方法を踏まえて妥当な数字にする必要があります。
Methodのサンプルサイズ計算では、上記のような部分を気にしながら突拍子もない計算をしていないかを確認していきます。
中間解析

ランダム化比較試験には倫理的な問題があることを知っておきましょう。
理由は、「効果の分かっていない治療をランダムに施す」という文字にしてみれば当たり前の理由です。
そのため、有害事象が多発した時や、逆に介入群の成績が良すぎる場合も(対照群への治療機会を奪わないために)、RCTは打ち止めになることがあります。
その判断を行うのが「中間解析」です。
この中間解析では、サンプルサイズの再計算などが行われることもあるので注意しましょう。

この研究でも、第2回の中間解析でも予想していたよりも、③の発症率が高かったためにサンプルサイズの再計算が行われています。
また、第3回の中間解析では、このままRCTを継続しても有意差が出る可能性は極めて低いと判断されてRCTが打ち切りとなっています。
つまり、今回のRCTはサンプルサイズが足りなかったことが有意差が出なかった理由ではない、ことが分かりました。
なぜ、こんなことを気にしているのでしょう?


それは後に効果が証明される「COVID-19に対するレムデシビル」の効果を、有意差なしとしたRCTがLancetに載ったことがあったからでした。
詳しくはスライドの通りですが、COVID-19の流行が収束してしまい検出力が58%(つまり、効果があっても2回に1回は有意差なしと判定してしまう!)となってしまっている研究でした。
Twitter上でも多くの医師がこの論文を紹介して「レムデシビルはCOVID-19に対してエビデンスがない」というようなことを書いていましたが、
その後に↓多くの国での多施設共同研究でレムデシビルには治療効果があることが示されました。
つまり、サンプルサイズ不足による検出力低下が原因で「有意差なし」と判定された場合は、そのRCTはあまり質が高いとは言えないので、
あまりそのRCTから結論を出さない方が良いです(これが論文の質を判断するという作業です)。
プチテクニック ”DeepL”

英語論文を読み進めると、単語がわからないものが続いて全然英語がわからなくなってしまうことがあると思います。
実際、この論文の解析の部分は少し難しかったのでDeepLの助けをかりました笑
Google翻訳と比べて、とても自然な日本語に翻訳してくれるので意味を取りやすくなります。無料なので、英語自体で引っかかってる人は使ってみてください!
(後輩からは実はこの「DeepL」の存在を教えたことが一番感謝されました笑)
最後にLimitation


基本的に、全ての論文で考察中にLimitationと題して、自分たちの研究を批判的に書いています(時々、客観的でないことがあります笑)
僕が、図表をみたときに感じた「なぜ、COVID-19を臨床診断している症例が多いのだろうか?」という疑問にも考察のLimitationの部分で触れていました。
理由は、COVID-19が流行しすぎて、医療体制として検査をすることができなかったから、のようです。
このようなlimitationをみたときやバイアスの存在を察知したときは、
そのlimitaton・バイアスが「有意差があるように見えてしまうものなのか」「有意差がないように見えてしまうものなのか」
を意識して読むと良いです。
では、次で最後のスライドになります。

英語論文について話すと、
「統計方法がちんぷんかんぷんです」と言う後輩が多いです。
正直、細かい解析方法は統計家に任せて、
臨床医としては「大枠としての研究デザインの理解」や「p値などの解釈」が正しくできることの方がよっぽど大切です。
なので、今回説明したような内容を理解して、果敢に論文を読み解いていってください!
また、今後も「コホート研究編」「メタアナリシス編」とシリーズ化していきたいと思っているので、興味ある人はフォローしてみてください!
一緒に「論文レビュー.com」を盛り上げていってくれる人募集中!
”論文レビュー.com”でやりたいと思っているのは、
果敢に英語論文を読んでいる若手医師たちで日々読んだ論文の日本語要約をupし合って刺激を与えあう環境を作ることです!
日本各地で、細々と英語論文を読んでまとめている医師がいると思っていますが、なかなか直接は出会えません。
そして、その知識を自分一人で独占したままにしておくのはもったいないです。
論文を読むときに一手間を加えて、日本全国の若手医師で知識を共有しませんか!?
興味ある方は、ご連絡ください!
このサイトの一番下にお問い合わせフォームがあるのでそこでもいいですし、Twitterなどでも良いです!次郎作ブログにコメントもらっても良いです!
以上、「第一回 論文読み解き講座」でした!
布施田泰之
医師としての勤務経験から、病院の外からも医療現場をよりよくできないかと考えています! サポートいただけるといろいろなことにチャレンジできます! 応援よろしくお願いします!