
【ポーカー】GTO+の集合分析をPythonで重回帰分析してみた

ゴールデンウィークはステイホームしながら自己研鑽のためにプログラミング言語のPythonを勉強してみた。ただ勉強してもつまらないので、次のような目的とゴールを設定。
GTO+で解析した集合分析をCSVファイルにして、それをPythonで重回帰分析する。その後、フロップ毎のアクションがEVに与える影響度を確認する
前提条件
今回はちょっとマニアックかつ自己満な記事のため、はじめに記事の対象者になる条件を羅列してみた。条件に合致する方は、ぜひ最後まで読んで頂けると幸いだ。
・Pythonの学習が目的なため、ある程度プログラミングを理解してること
・ポーカーのルール、GTO戦略をなんとなく理解してること
・この記事を読んでもポーカーが強くなるわけではない
・分析練習のため、精度にはあまりこだわらない
GTO+で集合分析する
今回はCO vs BBのハンドレンジを分析する。オリジナルレイザーのCOはzeros preflopのレンジ、BBのコールレンジはpreflop advisorを採用。
その他、GTO+の設定は以下の通り。
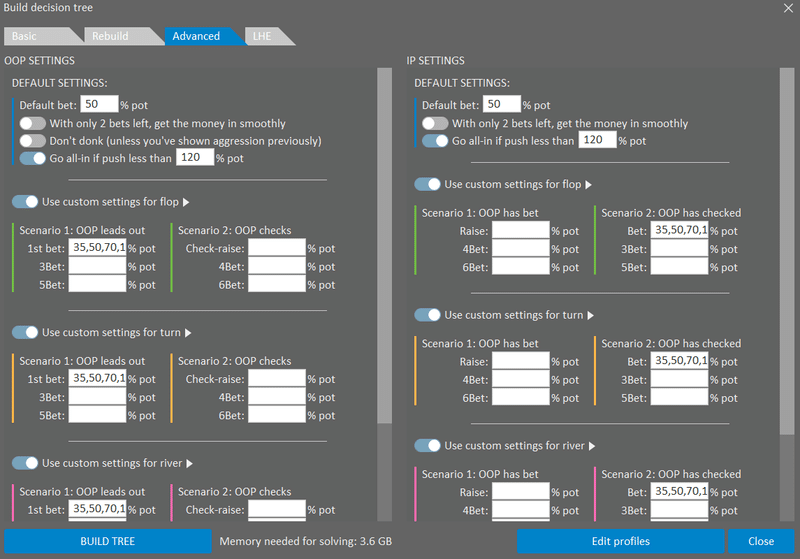
ベットサイズは35,50,70,100の4種類で、必要メモリの概算は3.6GBとかなり大きめだ。フロップはGTO+に標準で用意されているサブセットを使い、163個のボードを解析。これはかなり時間がかかりそうだが、これで想定されるフロップは概ねカバーできそう。

いざ分析を開始すると全て完了するまで6時間ほどかかった。これはかなりしんどいので、次からはもう少し設定を緩くしよう。ただPythonで解析するにはよいデータが用意できたと思う。データはCSVで保存した。
重回帰分析のコードを書く
PythonのStatsModelsを使って重回帰分析を実行する。コードはこちらのサイトで紹介されているものをほぼコピペさせてもらった。めちゃくちゃ分かりやすい神サイトだ。
実装はJuptyer NotebookでPython3を採用。これに先ほどのCSVファイルを読み込ませて重回帰分析してみた。わたしが書いたコードを晒しておこう。
import numpy as np
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
pd.options.display.precision=2
df = pd.read_csv('C:/Users/Path/to/file.csv')
#df.head()
x = pd.get_dummies(df[['EQ', 'BET1', 'BET2', 'BET3', 'BET4', 'CHECK']])
y = df[['EV']]
# 定数項(y切片)を必要とする線形回帰のモデル式ならば必須
X = sm.add_constant(x)
# 最小二乗法によるモデリング
model = sm.OLS(y, X)
result = model.fit()
# 重回帰分析の結果を表示
result.summary()
# 回帰式の結果を表示
#cons = result.params['const']
#ev = cons + (result.params['EQ'] * 40) \
# + (result.params['BET1'] * 50) \
# + (result.params['BET2'] * 10) \
# + (result.params['BET3'] * 10) \
# + (result.params['BET4'] * 5) \
# + (result.params['CHECK'] * 25)
#print(ev)簡単に説明するとGTO+の集合分析のうち、エクイティ(EQ)とベット(BET1~4)、チェックのアクションがEVに与える影響度が確認できる。
BET1~4は、それぞれポットの35,50,70,100(%)のベット額を意味する。
分析結果からの考察
サブセットで用意された163個のフロップの重回帰分析を見てみよう。

特に注目したい箇所を赤枠で囲んでおいた。まず「Adj. R-squared:自由度調整済み決定係数」を確認する。
以下、参考サイトより抜粋。
この値は、一般的に『自由度調整済み決定係数』と呼ばれ、回帰式全体の精度、説明力を示しています。目標は0.85くらいだと言われています。
とりあえず0.85あるので問題なさげだ。次は「t:各説明変数ごとの統計量」を確認する。この絶対値が大きければ大きいほど、目的変数(EV)に与える影響が大きいことになる。ご覧の通りEQの値が最も大きいため、EQがEVに与える影響が高いと分析できる。
次は「p>|t|:各説明変数ごとのp値」だが、これはP値とも呼ばれ「0」近ければちかいほど精度がよい。今回かなり「0」から離れているため精度は微妙だが、練習なのでこのままにしておく。最後は「coef」に注目しよう。ここは回帰式でEV計算する場合に利用するパラメータだ。
最後に興味深いデータを1つ紹介しよう。先ほどは163個のフロップを解析したデータを利用したが、これをモノトーンボードのフロップにフィルタリングしたデータで回帰分析してみる。重回帰分析の結果がどう変わるか見てみよう。

t値を比較するとBETの影響度が上がった。特にBET1(つまりポットの35%ベット)の影響が大きい。これはつまりモノトーンボードでは積極的にベットすることでEVが上がると解釈できる。ただしフィルタリングしたことでデータ量が減り、分析精度が曖昧になった可能性もある。
さいごに
今回の課題を通じて、CO vs BBのGTO戦略およびPythonの学習ができてよかった。分析の精度はイマイチだと思うが、重回帰分析に触れるよいサンプリングだったと思う。今後はGTO+にPythonの機会学習をプラスして何か実用的なことをしたい思いがあるが、わたしは統計学やデータ分析の勉強をしてこなかっため、なかなかハードルが高いのが現実だ。
ただPythonは開発ツールやライブラリが豊富なので、初心者でも取り組みやすい言語だと思った。その分、ブラックボックスな要素も多く難しいが。
最後まで読んで頂き、ありがとうございます。
この記事が気に入ったらサポートをしてみませんか?