Style-Bert-VITS2のAPIを使ってAIVtuberの音声に反映させる

AIVtuberシロハナちゃんの開発プロデュースをしているyukiです。
この記事では、Style-Bert-VITS2のAPIを使用することで、AIVtuberシロハナの音声がこれまでより感情豊かになったので、その手順や説明をまとめた内容となります。
つまり、Style-Bert-VITS2のAPIの使い方や、音声の学習方法、他音声モデルとのマージなど、Style-Bert-VITS2について幅広く知ることができます。
(もちろん、AIキャラやAIVtuberの音声に本記事の内容を参考にして活用することも可能です)
こちらの内容はシロハナのYouTube動画でも同じ内容で公開しているので、実際の音声を聴きたい場合などはそちらをご覧ください。
※逆にAPIを使用するサンプルコードなどは本記事のほうが分かりやすいですので、臨機応変にご活用ください。
※この記事は2024/6/8時点のものなので今後変更があるかもしれないですのでご了承ください
Style-Bert-VITS2概要と実装要件
Style-Bert-VITS2については上記のREADMEをご覧いただくのが確実ですが、簡単に説明すると、テキストの内容をもとに音声を生成できるものになります。
AIVtuberシロハナはこれまでvoicevoxという合成音声ソフトを使用してきましたが、機能としては大体同じようなイメージです。
テキストを入力するとその内容を合成音声で読み上げるというものとなります。
Style-Bert-VITS2の特徴としては主に以下があります。
テキスト内容をもとに感情表現された音声を生成できる
音声ファイルをもとに学習でき、その学習したモデルを合成音声として使用できる(APIとしても呼び出し可能)
マージ機能で、例えば"声はAモデル"で"話し方をBモデルにする"などカスタマイズが充実
ざっくり以上のような機能があるため、独自の音声を生成することができるのです。
今回のAIVtuberシロハナに実装するにあたっての要件としては、以下の課題がありました。それらを踏まえて要件を整理します。
voicevoxでは決められたキャラから選択をするので他のAIVtuberなどと音声が被りやすい(オリジナリティが懸念)
voicevoxでも抑揚などである程度は自然に話すこともできるが、これまで以上に話し方を自然にしたい(感情などを表現できるように)
ただし、音声は既にvoicevoxの小夜というキャラで活動をしているので大きくイメージは変えたくない
APIでPythonを使って作成したモデルの音声を呼び出せるようにしたい
この要件をもとにStyle-Bert-VITS2を使って実装をしたので、これから実際に行った手順をまとめていきます。
インストール方法
ではまずはインストール方法からですが、READMEの通りなのでそちらを参照ください。


上記のStyle-Bert-VITS2 エディターが開けばインストール完了です。
こちらで任意の文字を入力して音声合成ボタンを押下したら入力した文字列が音声で出力されます。
※GPU版に関して、「RTX 2060」など2000番代だとインストールできなかったので3000番代以上でお試しください。
音声学習方法
次に音声学習をしていきます。
音声学習とは、用意した音声素材を合成音声として使えるようにしたものとなります。
※ちなみに学習はGPU版でないとできないです
学習データ(音声素材)の用意
まずは学習させたい音声素材を用意します。
素材は人間の声でも大丈夫ですが、今回の要件では既存の音声(つまりvoicevox小夜ちゃんのボイス)から声はあまり変えたくないので、voicevoxでwavファイルを生成しました。
※小夜ちゃんの公式に問い合わせたところ、機械学習へ小夜/SAYOの音声を利用することに関して、禁止しておりませんとのことです。
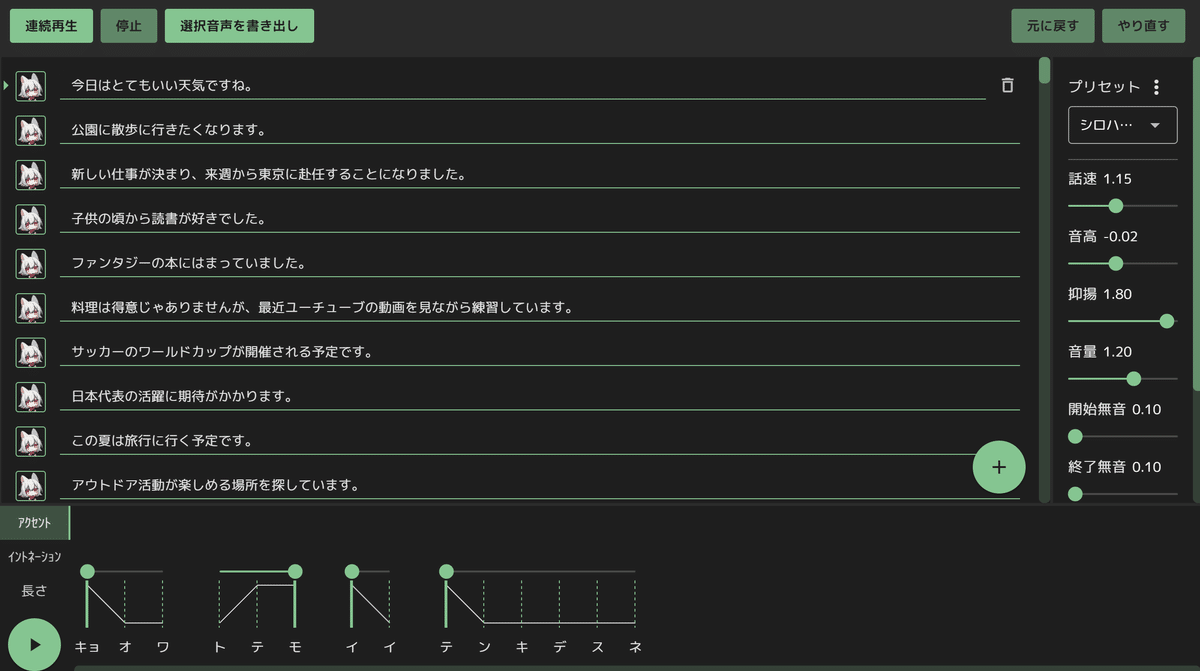

上記のようにAIVtuberシロハナで使用していたパラメータに調整をして適当な文章を入力します。(文章はGPTなどで用意)
パラメータ(声の高さや抑揚など)は何パターンか用意しておくと良いです。
今回は"デフォルト""嬉しい","照れ","感動","驚き","呆れ","好き","ショック","ドヤ顔","泣き","怒り"で各種パラメータを調整して音声生成させました。
理想は感情ごとのvoicevoxモデルがあれば良いのですが、小夜ちゃんの場合は1モデルしかないのでパラメータ調整で何とかしている感じです。
(ずんだもんなど、複数のボイスモデルがある場合は複数モデルの音声素材を用意したほうがより感情豊かに話すようになります)
ちなみに音声ファイルは合計800ファイルくらい用意しましたが、多分そんなに要らなかったと思います(数分からでも大丈夫そうなのでお好みって感じですかね)
音声素材があればあるほど学習に時間がかかってしまうので注意です。
こちらの音声素材(wav)は"sbv2\Style-Bert-VITS2\inputs"の中に保存しておきます。

Style-Bert-VITS2 WebUIを開く
音声素材を用意出来たらApp.batをダブルクリックします。
または以下コマンドでもOK。
cd C:\sbv2\Style-Bert-VITS2
python app.py
http://127.0.0.1:7860/でStyle-Bert-VITS2 WebUIが開きます。
スライスと音声の文字起こし作業
Style-Bert-VITS2 WebUIで最初に学習の下準備であるスライスと音声の文字起こしをします。
まずは「データセット作成」というタブを選択します。

ここで最初にモデル名を入力します(話者名としても使用されるので、今回はshirohanaとしました)
次にスライスを実行というボタンを押下します。
結果の箇所に完了しましたと表示されるまで待ちます。
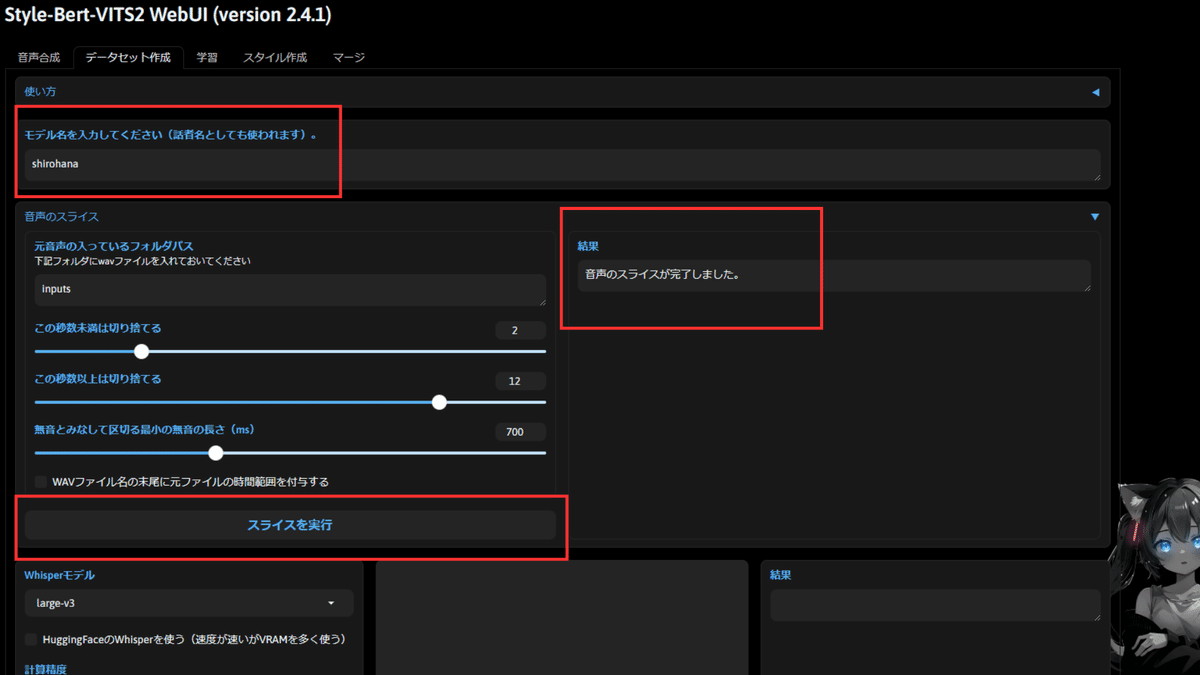
次にサイトをスクロールして"音声の文字起こし"をクリックします。

同じく結果の箇所に完了しましたと表示されるまで待ちます。(少し時間かかるので進捗はターミナルで確認)
学習を行う
下準備ができたら実際に学習を行いましょう。
「学習」タブを選択します。
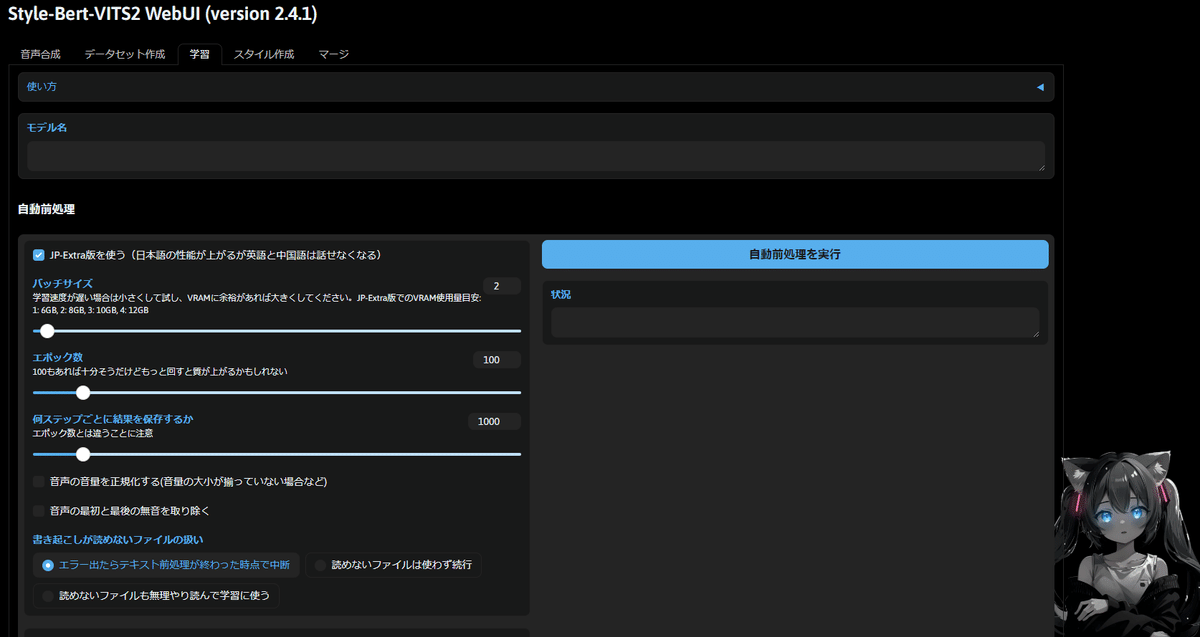
ここのモデル名に先ほどスライスをしたときに付けたモデル名と同じものを入力します(今回の場合はshirohanaと入力)
入力後に「自動前処理を実行」ボタンを押下してしばらく待ちます。
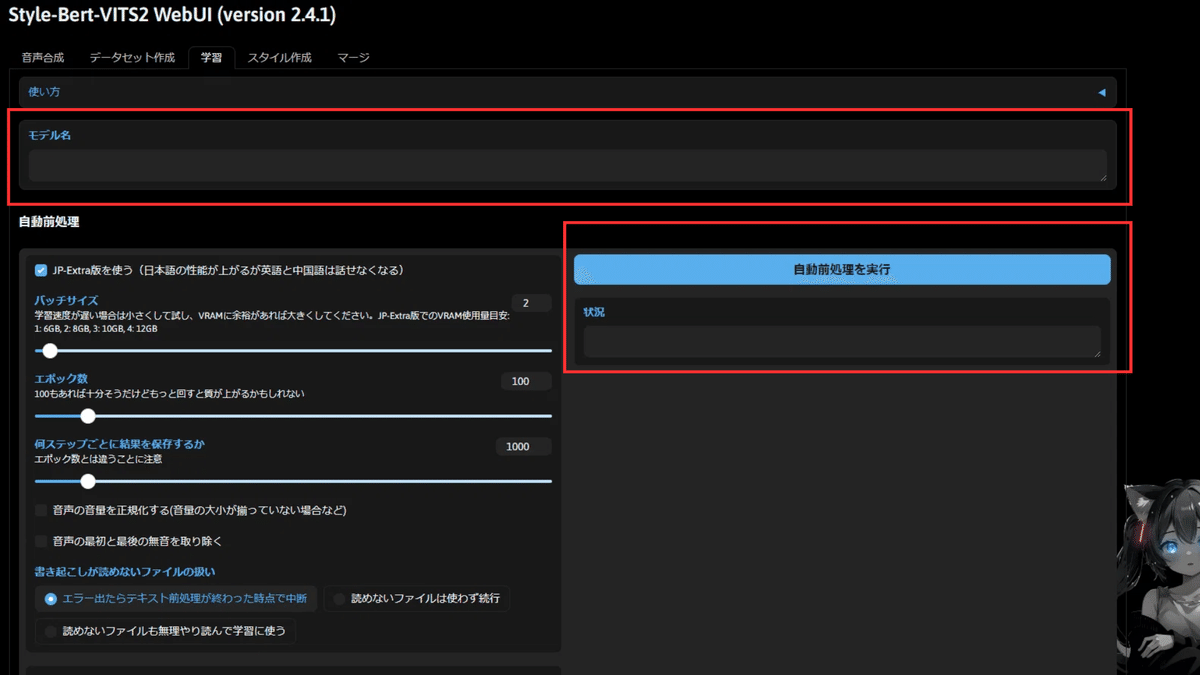
状況の箇所で完了と表示されたらOKです。
上記が完了したらスクロールして「学習を開始する」ボタンを押下して学習を開始します。


学習には時間がかかりますので、ターミナルで進捗を確認しましょう。
ちなみに今回はファイル数が800くらいで8時間もかかってしまいました。
おそらくこんなに音声素材は要らない気がしています。
学習時間も考慮して音声素材を検討するのが良いかと思います。

学習が完了するとこのように「SUCCESS」と出ます。
Style-Bert-VITS2 エディターで確認
学習が完了したら、学習されたモデルがしっかりとあるかエディターの方で確認してみましょう。
ちなみにEditor.batをダブルクリックでエディター開くことができます。
または以下コマンドを叩くでもOK
cd C:\sbv2\Style-Bert-VITS2
python server_editor.py --inbrowserここでモデルに先ほど学習時に入力したモデル名があるかを確認します。

今回はshirohanaというモデルがあるはずです。
こちらを選択して音声合成してみると学習した音声素材をもとにした音声が出力されます。
モデルをマージして話し方を自然にする
学習後にモデルの読み上げを確認してみると、今回の場合だとvoicevoxと比べてそんなに変わらない音声が生成されました。
これは恐らく、素材音声のバリエーションが少ないことが原因だと考えています(人間の声などは既にいろんなパターンの素材を取得できるが、voicevox小夜の場合はパターンが限られると推測)
このままだと意味がないので、他のモデルとマージを行います。
マージをすることで、先ほど作成したモデル「shirohana」の声のまま、合成音声モデル「Anneli」の話し方を反映させることが可能です。(マージするモデルはお好きなモデルで大丈夫です)
マージすることで、voicevoxの時よりも自然で特徴のある音声表現が可能になるわけです。
やり方としては、Style-Bert-VITS2 WebUIで「マージ」タブを選択します。
ここで、左のモデル名に「shirohana」、右のモデル名に「Anneli」を選択します。
※その前にマージしたいモデルをStyle-Bert-VITS2/model_assets/に入れておく必要があります。
新しいモデル名には、マージ後のモデル名を入力します。
今回は安直に「shirohana-anneli」としました。
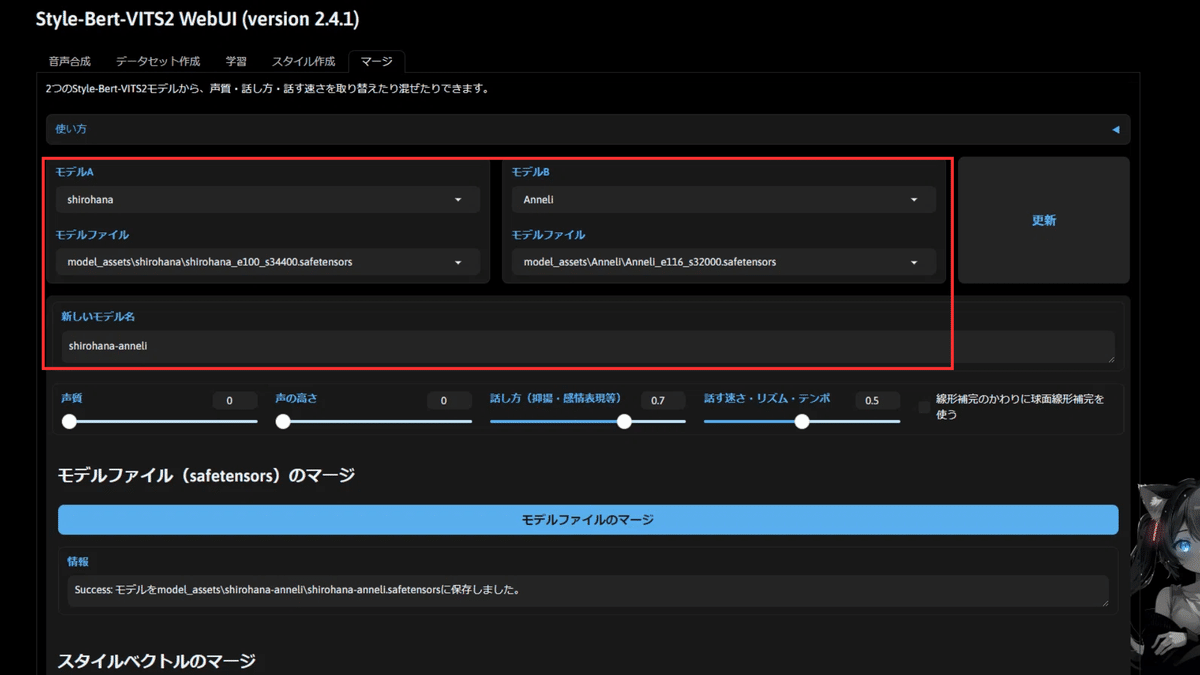
そして、シロハナの場合は話し方を「0.7」、話す速さ・リズム・テンポを「0.5」としています。

声質と声の高さは先ほども記載した通り、もとのままにしたいので0としています。
話し方と話す速さ・リズム・テンポに関してはMAXにするとAnneli側に寄り過ぎて違和感があったのでこのように絶妙に調整しているわけです。
こちら記載ができたら「モデルファイルのマージ」を押下すればOKです。

そのあとは下にスクロールをして、「スタイルのマージ」も行います。

これでマージは完了です。
エディターを再起動して、確認してみます。

エディターにマージしたモデルshirohana-anneliがあることを確認できたらマージ完了しています。
試しにこちらのモデルで合成音声してみると、声は既存のままで、話し方にマージしたAnneliの特徴が反映されているのが分かります。
マージのパラメータを強すぎない程度にしているので、キャライメージを崩さずに話し方を自然に変化させることができました。
APIを使ってシステムで作成した音声モデルを呼び出す
Style-Bert-VITS2でAIVtuberシロハナの音声モデルを作成できたら、このモデルを実際にAPIで呼び出せるようにしましょう。
音声生成が100文字以内に制限されているので調節する
まず事前準備ですが、Style-Bert-VITS2ではデフォルトだと1回に生成できる文字数が100文字と決められています。(100文字超えるとエラーになる)
しかし、AIVtuber配信だと回答が100文字超えることもあり得ます。
なので、ここの基準値を修正します。
C:\sbv2\Style-Bert-VITS2にあるconfig.ymlを開きます。
開いてserver:のlimitの箇所が最初は100になっているので、ここを1000にします。
そうすることで上限が1000文字になってエラーが発生しなくなります。

localhost:5000を立ち上げる
以下コマンドをターミナルで実行してください。
移動
cd C:\sbv2\Style-Bert-VITS2FastAPIサーバー立ち上げ
python server_fastapi.py
上記のようなターミナルになったらOKです。しかし、最初は必要なパッケージが多分ないためエラーになります。なのでエラーになったら以下のコマンドでパッケージのインストールをしましょう。
エラーが出る場合はGPTなどにそのままエラーを渡せば解決策が返ってくるはずです。
※Pythonのバージョンは3.12だとエラーが出たので、3.10で試しました。
ちなみにAPIサーバー立ち上げて、http://127.0.0.1:5000/docsにアクセスしてAPI仕様書が表示されれば問題ないことが分かります。

APIを使用するコードを記載する(サンプルコード)
ターミナルで入力した値をStyle-Bert-VITS2のAPIを叩いて合成音声で読み上げるサンプルコードです。
# 必要なライブラリをインポートします
import requests
import io
import soundfile
import argparse
import sounddevice as sd
# Sbv2Adapterというクラスを定義します
class Sbv2Adapter:
URL = "http://127.0.0.1:5000/voice"
def __init__(self) -> None:
pass
# 音声を取得するためのクエリを作成するメソッドです
def _create_audio_query(self, text: str) -> dict:
# パラメータを定義します
params = {
"text": text,
"speaker_id": 0,
"model_name": "shirohana",
"length": 1, #音声の話速(1.0=標準、2.0=2倍遅く、0.5=2倍速く)
"sdp_ratio": 0.2,
"noise": 0.6,
"noisew": 0.8,
"auto_split": True,
"split_interval": 1,
"language": "JP",
"style": "Neutral",
"style_weight": 5,
}
return params
# 音声をリクエストするメソッドです
def _create_request_audio(self, query_data: dict) -> bytes:
headers = {"accept": "audio/wav"}
response = requests.get(self.URL, params=query_data, headers=headers)
# エラーハンドリング
if response.status_code != 200:
raise Exception(f"Error: {response.status_code}")
return response.content
# 音声を取得するメソッドです
def get_voice(self, text: str):
query_data = self._create_audio_query(text)
audio_bytes = self._create_request_audio(query_data)
audio_stream = io.BytesIO(audio_bytes)
data, sample_rate = soundfile.read(audio_stream)
return data, sample_rate
def main(text: str):
adapter = Sbv2Adapter()
data, sample_rate = adapter.get_voice(text)
sd.play(data, sample_rate)
sd.wait()
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Text to Speech")
parser.add_argument("text", type=str, help="The text to be converted to speech")
args = parser.parse_args()
main(args.text)各種パラメータ等の説明はhttp://127.0.0.1:5000/docsでご確認ください。
モデルIDで作成したモデルを指定することで、その音声でレスポンスが返ります。
また、このサンプルコードsbv2.pyファイルで、以下コマンドを叩くと実行します。
(.venv) C:\aituber>python sbv2.py "こんにちは、世界!"これを実行すると、Style-Bert-VITS2のAPIで指定した合成音声にて「こんにちは、世界!」が読み上げされます。
こんな感じでAIVtuberシステムに組み込めば、LLMで生成されたテキストをStyle-Bert-VITS2のAPIで音声に変換して出力することができるわけですね。
追記:GPU版なのにGPU使われない事象の場合
GPU版入れたはずなのにGPUが殆ど使われずにCPU使用率が高い事象が発生していましたので、その解決記録を残します。
結論、CUDA Toolkitインストールして仮想環境内にCUDA対応のPyTorchを再インストールでGPU使うようになって生成が爆速になりました。
pip uninstall torch torchvision torchaudio
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121インストール後、仮想環境内でPyTorchがCUDAを認識しているか確認
python -c "import torch; print(f'PyTorch version: {torch.__version__}'); print(f'CUDA available: {torch.cuda.is_available()}'); print(f'CUDA version: {torch.version.cuda}'); print(f'GPU name: {torch.cuda.get_device_name(0) if torch.cuda.is_available() else \"No GPU\"}')"さいごに
以上がStyle-Bert-VITS2の音声学習からモデル作成、APIを使用する方法になります。
これまでAIVtuberシロハナちゃんは音声部分のカスタマイズは管理の制約がありましたが、sbv2を使うことでかなり自由度の高いカスタマイズができるようになったと思います。
実際にシロハナちゃんに今回作成したモデルを適用してみたところ、以前よりも自然で可愛い推せる音声と感情表現になったと感じております。
しかも、これまでと声自体はそこまで変化していないので、キャライメージも保てたままという点が個人的には大きいです。
そのうち、AIVtuberシロハナちゃんのYouTubeチャンネルにて、Style-Bert-VITS2のAPIを使用したAIVtuber配信を行う予定ですので是非チェックしてみてください。
また、本記事の内容を動画でも解説をしていますので、ぜひ音声の比較なども含めてご覧いただければ幸いです。
最後に私がプロデュースしているAIVtuberシロハナちゃんの宣伝をさせてください。
理想のAIヒロインを目指して、AIを使ったリアルタイム配信や、AIヒロイン研究所というコンセプトのもと、「テクノロジー×キャラクター」に関する動画等を発信しています。
興味がありましたらぜひ!
以上!それではまた👋
【New!!】
Style-Bert-VITS2のささやきボイス作成について記事と動画が追加されました。
いいなと思ったら応援しよう!
