
DifyのLLMブロックの使い方

こんにちは、よーすけです。
今回はDifyのLLMブロックの使い方について解説します。
LLMブロックとは
LLMを簡単に使うことができるブロックで、 Difyの強みの一つです。
モデルを簡単に切り替えることも可能です。
※LLMの種類によってはパラメーターが存在しないものもあります。またバージョン0.6.8のLLM ブロックを解説しているのでバージョンによっては多少異なる可能性もあります
PARAMETERS(パラメーター)
以下のパラメータ部分の内容を解説します
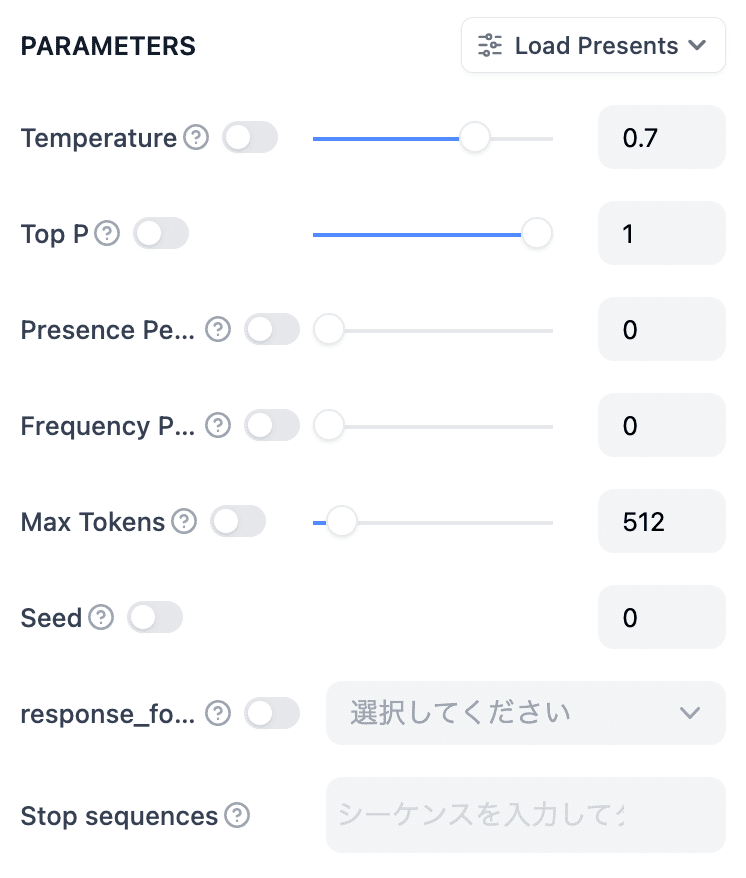
Temperature
Controls randomness. Lower temperature results in less random completions. As the temperature approaches zero, the model will become deterministic and repetitive. Higher temperature results in more random completions.
ランダム性を制御します。温度を低くすると、生成されるテキストはランダム性が少なくなります。温度がゼロに近づくと、モデルは決定論的で繰り返しの多い出力になります。温度を高くすると、生成されるテキストはよりランダム性が高くなります。
Temperatureは生成されるテキストのランダム性や多様性を調整するためのパラメータです。
フォーマルな文章や正確さが求められる場合は低い値(0.1や0.2)
創造的な文章や詩、物語の生成などは高い値(0.9や1)が適しています
Top-p (Nucleus) Sampling:
Controls diversity via nucleus sampling: 0.5 means half of all likelihood-weighted options are considered.
多様性をnucleus sampling(核サンプリング)を通じて制御します:0.5は、すべての確率加重オプションの半分が考慮されることを意味します。
モデルが生成する次の単語の候補を確率の高い順に並べ、その累積確率が指定したp(確率しきい値)を超えるまでの単語だけを考慮します。
テキスト生成の多様性を制御し、より自然で予測しにくい出力を得るために使用します。また、値を上げると多様性が増し、下げると一貫性が増します。
具体例
入力プロンプト:「今日はどんな日ですか?」
0.5 の場合
累積確率が50%に達するまでの単語候補のみを考慮します。通常、確率の高い少数の単語だけが選ばれるため、出力がより予測しやすく、一貫性が高くなります。
例:
出力1:「今日は晴れていて気持ちの良い日です。」
出力2:「今日は少し曇りですが過ごしやすいです。」
0.9 の場合
累積確率が90%に達するまでの単語候補を考慮します。より多くの単語が選ばれる可能性があるため、出力が多様で予測しにくくなります。
例:
出力1:「今日は晴れていて、風が心地よい日です。」
出力2:「今日は曇りですが、涼しくて過ごしやすいです。」
Presence Penalty
Applies a penalty to the log-probability of tokens already in the text.
テキストにすでに含まれているトークンの対数確率にペナルティを適用する。
Presence Penaltyは生成されるテキストが繰り返しや冗長にならないように設定する値です。
同じ単語やフレーズが何度も出現すると、テキストが単調になりがちです。ペナルティを適用することで、モデルはより多様な単語を選ぶようになります。
ペナルティを適用しない場合
例:入力プロンプト:「昨日のディナーはどうでしたか?」
出力:「ディナーはおいしかったです。ディナーは本当においしかったです。」
この場合、同じ単語「ディナー」が繰り返されており、冗長です。
ペナルティを適用した場合
同じ単語が繰り返されないようにペナルティを適用します。
例:入力プロンプト:「昨日のディナーはどうでしたか?」
出力:「ディナーはおいしかったです。食事全体が素晴らしかったです。」
設定することで繰り返しを抑制し、生成されるテキストの多様性を高めることが可能になります。
Frequency Penalty
Frequency Penaltyを設定することで、同じトークンが繰り返し出現することを抑制し、多様性のあるテキストを生成しやすくなります。
ペナルティを適用しない場合
モデルは最も確率の高いトークンを選びがちです。同じトークンが繰り返されることがあります。
例: 入力プロンプト:「猫は」
出力:「猫はかわいい。猫はかわいい。」
ペナルティを適用した場合
既に出現したトークンの対数確率が減少するため、モデルは異なるトークンを選択しやすくなります。
例: 入力プロンプト:「猫は」
出力:「猫はかわいい。犬もかわいい。」
繰り返しを抑制し、生成されるテキストの多様性を高めるために使用します。
Presence Penaltyと似ていますが少し違います。
ペナルティの基準
Frequency Penalty:トークンの出現回数に基づく
Presence Penalty:トークンが一度でも出現したかどうかに基づく
目的
Frequency Penalty:単語の多用を防ぎ、多様性を高める
Presence Penalty:一度出現した単語の再出現を防ぎ、多様性を高める
Frequency Penaltyはトークンが多く出現するほど、そのトークンに対するペナルティが大きくなりますが、Presence Penaltyでは一度でも同じトークンが出た場合にペナルティーを与えます。
Max Tokens
出力の最大トークン数です。
1からnで設定することができます。
nはモデルによって異なります。
例えば、Gemini 1.5 Proでは8192、gpt-4oだと4096です。
Seed
If specified, model will make a best effort to sample deterministically,
such that repeated requests with the same seed and parameters should return the same result. Determinism is not guaranteed, and you should refer to the system_fingerprint response parameter to monitor changes in the backend.
指定されている場合、モデルはできるだけ決定論的にサンプリングを行い、同じシードおよびパラメータで繰り返しリクエストすると同じ結果が得られるように努めます。ただし、決定性は保証されていないため、バックエンドの変更を監視するために system_fingerprint レスポンスパラメータを参照する必要があります。
シードを使わない場合
同じ入力に対しても、毎回異なる出力が生成されます。
例: 入力プロンプト:「今日はどんな日ですか?」
実行1:出力:「今日は晴れていて、とても気持ちの良い日です。」
実行2:出力:「今日は少し曇りですが、過ごしやすい天気です。」
シードを使う場合
同じシードを設定することで、同じ入力に対して毎回同じ出力が得られます。
例: 入力プロンプト:「今日はどんな日ですか?」 シード:42
実行1:出力:「今日は晴れていて、とても気持ちの良い日です。」
実行2:出力:「今日は晴れていて、とても気持ちの良い日です。」
つまりシード値が高ければ高いほど出力値にブレが出にくくなります。
シード値を設定しない場合は毎回異なる回答が生成されやすくなります。
response_format
出力値を「テキスト」か「JSON」形式かを指定できます。
Stop sequences
p to four sequences where the API will stop generating further tokens. The returned text will not contain the stop sequence.
APIがさらにトークンを生成するのを停止する最大4つのシーケンスを指定します。返されるテキストには停止シーケンスは含まれません。
Stop sequencesはテキスト生成を望ましいタイミングで終了させるためのシーケンスです。
意味:テキスト生成の終了
特定のキーワードやフレーズが出現した時に生成を止める。
例: 「終了」、「終わり」、「--END--」など。
使用例)
テキスト生成中に「終了」という単語が現れると、その時点で生成が停止します。
まとめ
今回は LLMブロックについて解説しましたが 、今後は他のブロックや機能についても解説していきます。
この記事が気に入ったらサポートをしてみませんか?