Lookerで経営データ分析!#2 全体アーキテクチャ

こんにちは。今回はLooler分析の全体のアークテクチャを掲載します。
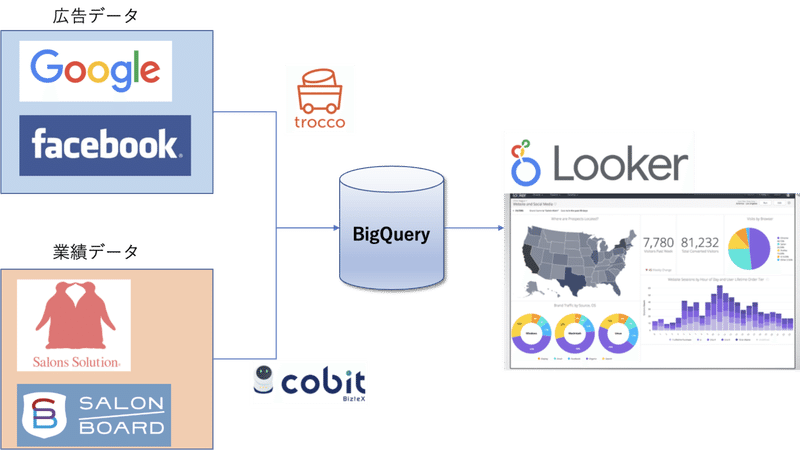
各広告サイトの管理画面から広告データを、クライアントが管理している業務システムから業績データを取得します。(今回クライアントが美容系になるので、Salons Solution、SALON BOARDという業務システムを利用します。)
これまでは担当者が毎日手動でデータを取得していたパートを自動化します。
広告データ → BigQuery
trocco(https://trocco.io/lp/index.html)というデータ統合自動化サービスを利用します。こちら広告系からストレージサービスまで様々なサービスのコネクターが用意されており、日々のデータのBigQueryへの連携を自動でやってくれる優れものです。
広告データ連携の前準備として、GoogleやFacebookなど自分の各アカウントに広告データの参照権限を付与します。※Facebookはデータ取得用に作ったアカウントなど個人と紐づかないアカウントはBANされてしまうのでご注意を...
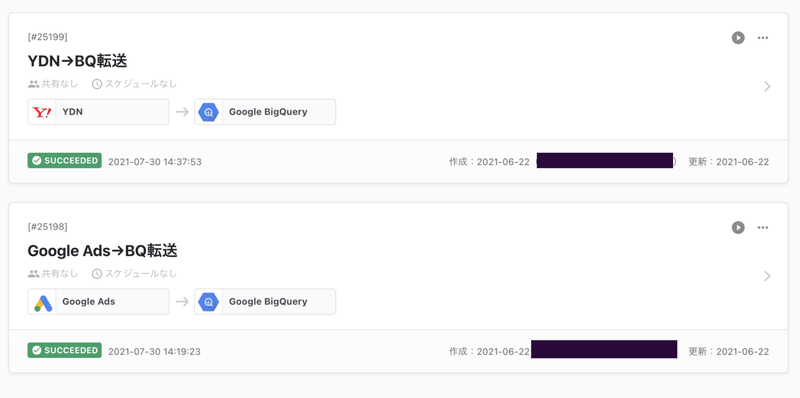
GUIで設定をぽちぽち入力して転送設定を作っていきます。自動でデータのプレビュー、データ型の設定を行ってくれるので、任意でデータ型の変更を行わない限りとても楽です。
業績データ → BigQuery
Biztex社のクラウドRPAのcobit(https://service.biztex.co.jp/)を利用します。データ可視化に必要な業績データのCSVファイルを所定の場所からダウンロードする工程をRPAで自動化、取得したCSVファイルはGoogleドライブに格納、または所定のスプレッドシートに書き出すようにして、日々データを取得、BigQueryに連携します。文字コードの変更Shift JIS → utf8 や取得日次列の追加などBigQueryに格納するのに必要な整形処理をPythonでやります。
import datetime
import glob
import re
import os
import codecs
def format1():
#フォルダ内のCSVファイル取得
files = glob.glob("*.csv")
files.sort()
now = datetime.datetime.now()
cnt = 0
for file in files:
#入出力ファイルの定義
file = codecs.open(file,"r","Shift_JIS","ignore")
out_filename = '../出力ファイル/out_{0:%Y%m%d_%H%M%S_}{1}.csv'.format(now,cnt)
out_file = open(out_filename,"w")
#入力ファイルでヘッダー行を飛ばした後、全行を読み取り、整形
file.readline()
lines = file.readlines()
for line in lines:
line = re.sub('^"|"\r\n','',line).split('","')
#店舗名、日付を挿入
#line.insert(0,STORE_LIST[cnt])
#line.insert(0,os.getcwd().split('/')[-1])
line = [i.replace(',','') for i in line]
line.append('{0:%Y-%m-%d}'.format(now))
#出力ファイルに書き出し
out_file.write(','.join(line))
out_file.write('\n')
#2つのファイルを閉じる
file.close()
out_file.close()
cnt += 1これでBigQuery上に広告データと業績データを日次で格納する準備ができました。BigQuery上で、広告データと業績データをJOINしてCPA(Cost Per Acquisition:広告費用 / コンバージョン数)やROAS(Return On Advertising Spend:広告経由の売上 ÷ 広告費用 × 100(%))を見ることができます。
BigQuery → Looker
https://docs.looker.com/ja/setup-and-management/database-config/google-bigquery#%E6%A6%82%E8%A6%81
まずGCPのサービスアカウントを作成、LookerからBigQueryを編集できる状態にします。接続設定が上手くいったら、LookMLというモデリング言語でBigQuery内のテーブルを参照し、可視化のモデリングを行います。
全体のアーキテクチャは上記の通りです。データ取得などはできるだけ自動化して、日々の運用工数はエラー対応やアップデートに割けるようにというのがコンセプトです。
この記事が気に入ったらサポートをしてみませんか?