
連載1-MMUを味方に! Cortex-Aを使った快適なuITRONシステム開発

1.MMUの使われ方
唐突ですが、MMUってご存じでしょうか?
論理アドレスを物理アドレスに変換する、アレです。
使用例を挙げるならば、Linux。複数プロセスが同時に動作するマルチプロセスです。
同時、と言っても、ある瞬間で見るとどれか一つのプロセスが動いているわけですが、次の瞬間には違うプロセスに切り替え、きちんと動きます。
それぞれプロセスは、
・実行プログラム本体があるメモリ空間
・データ保管空間
・スタック
など、必要なメモリ空間があります。
マルチプロセスシステムにおいて、各プロセスが個々にメモリ空間を持ってしまっていたら、プロセスを管理する側は大変です。
同時で動く全プロセス分、重ならならいメモリ空間に割り当てないといけないので、それぞれのプロセスのアドレスにオフセットがそれぞれ付くことになります。
(方法は色々あるかと思います。あくまでも一例です。)
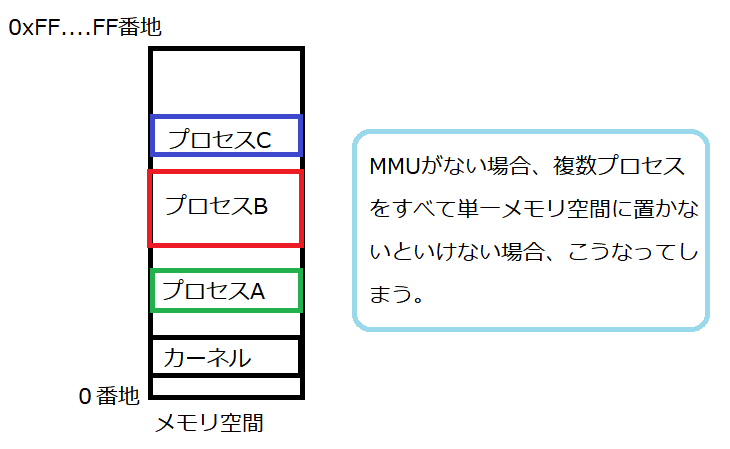
同時に動けるプロセスの数が少なければ、これもいいかもしれません。
ですが、Linuxのようなある意味完全体のマルチプロセスシステムでは、そうはいきません。
いくつプロセスが同時に実行するかなんて、カーネルはわかりません。
そこでMMUです。
「プロセスの空間」を論理アドレス(CPUが理解するアドレス)でココ!と定義し、みんなプロセスはそこで動くことにします。
その論理アドレスに対する物理アドレス(メモリに実際に格納されている場所)は、MMUが把握します。
プロセスごとに、同じ論理アドレスで違う物理アドレスが紐づけられるわけです。
どのプロセスがどの物理アドレスにいらっしゃるのか、を整理整頓しているのが、MMUのテーブルです。
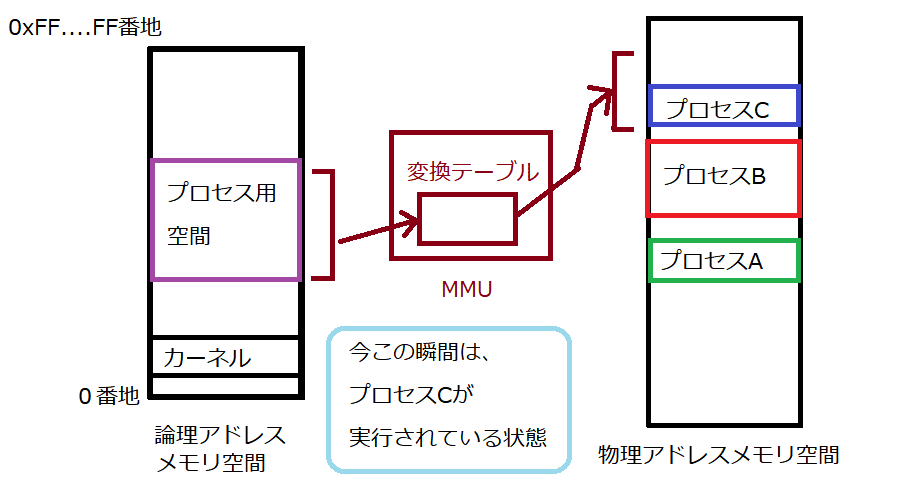
このように、Linux等、ある意味完全体のマルチプロセスシステムの場合、MMUはなくてはならない重要な存在です。
CPUは論理アドレスで、ホイッとメモリアクセスすればよく、実際にその論理アドレスに対応した物理アドレスに変換するのはMMUで、変換先のメモリはバス経由でアクセスされます
ただし、プロセス入れ替えの際にそれなりの遅延は発生します。
(MMUテーブルを切り替えたり、その時に多分キャッシュが総入れ替えになったり。。。)
では、uITRONの場合はどうでしょうか。
uITRONが期待されているのは厳密なリアルタイム性です。
uITRONもマルチスレッドで動作させる場合、ある程度コンテキストスイッチは発生します。(それさえも許容できない場合、マルチスレッドにしないことも可能)
ですが、MMUを使って大規模なマルチプロセスシステムを採用し、プロセスの入れ替えをきっちりとやり切る事は、リアルタイム性重視の観点からはちょっと難しいです。
じゃ、uITRONでは全然MMU使わない?
いえ、Cortex-Aの場合、キャッシュを使おうとするとMMUを有効しないといけない、とう消極的な理由で、MMUは使用されていたりします。
しかしこの場合、
「論理アドレス=物理アドレス」
で、実質MMUはスルーされています。
ちなみに他のCPUでは、キャッシュとMMUが完全分離されているものもあり、こういうCPUでは「キャッシュだけON」という場合もあります。
しかし!
MMUには、変換テーブルに属性を持たせることができたり、例外を発生したりすることができます。
「キャッシュ使いたいから、仕方ないからMMUをONにしなきゃ。」
だけだと、勿体ない!
2.変換対象アドレスがない場合?
MMUは、論理アドレスから物理アドレスに変換するためのものですが、その機能を実現するための付随機能で便利なものがあります。
それは、指定されたアドレスに対する物理アドレスが、MMUテーブルに記録されていない場合の機能です。
その場合、MMUは「変換先がありませんが?」という例外を発生します。
という事は、
「CPUからの変なアクセスをキャッチできる」
という事です。
実は京都マイクロコンピュータ社製のSOLID OS/IDEで、この特徴を利用して便利なデバッグ機能を実現しています。
前回のRust連載で使用した、Raspberry pi 4 × SOLIDの環境で、見てみましょう!
3.SOLID OS/IDEでのMMU使いこなし例
組み込みのデバッグあるある:
「数時間に一度の頻度で、謎のリセット発生。」
疑うべくは、メモリ破壊、不正アドレスアクセス、多重割り込み発生、、、
いろいろ考えられますが、メモリ破壊、不正アドレスアクセスの要因の筆頭候補には以下2点があります。
・NULLポインタアクセス
・スタックオーバーフロー
実はどちらも従来もハードウェアブレークで引っ掛けるという形で実現できます。
ハードウェアブレークを「アクセス対象番地へのリードライトアクセス発生」で仕掛けておくと、メモリアクセス発生直前にブレーク発生します。
ちょっと試してみましょう。
ハードウェアブレークを使ってみます。
とりあえず、ハードウェアブレークでメモリアクセス起因のブレークが発生することを確かめてみます。なので、アドレスは適当な内蔵I/Oレジスタの値にしてみました。
プログラムではデータライトをしていますので、書き込んでも大丈夫そうな、SPIのFIFOレジスタをアクセス先としてみました。
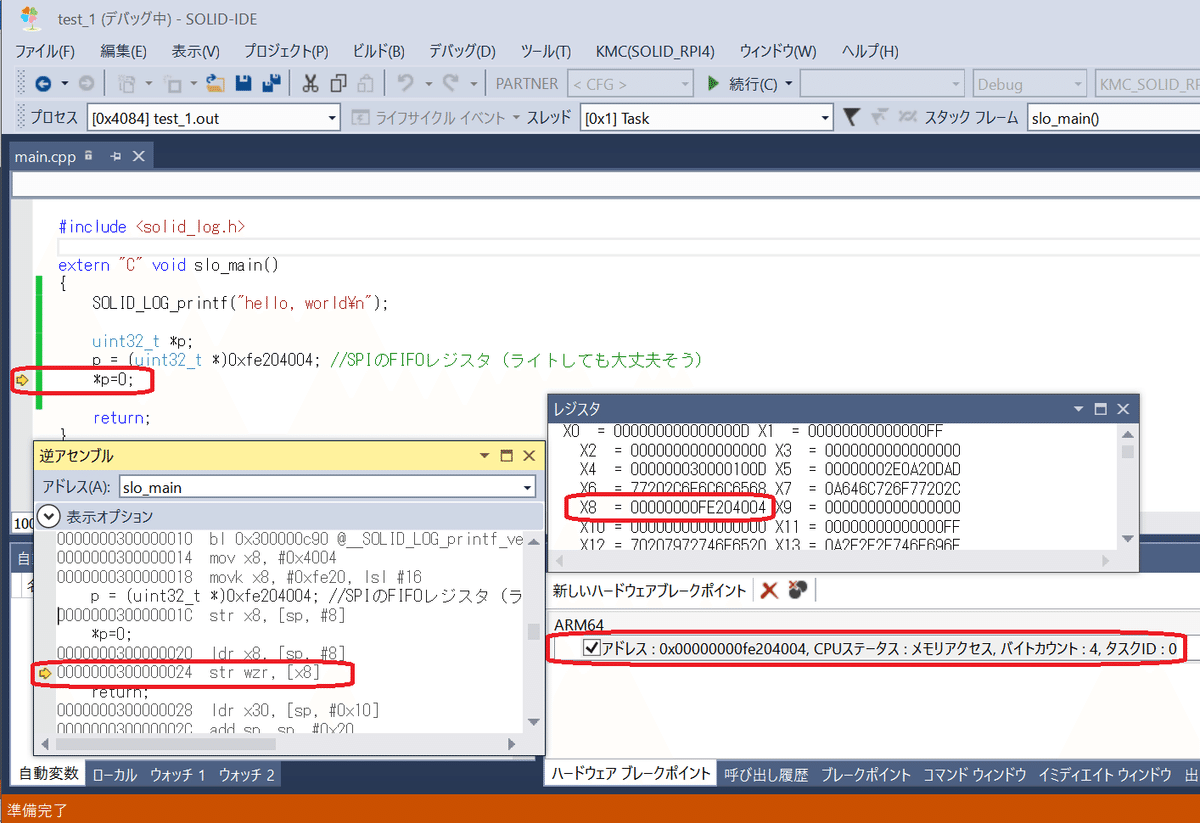
逆アセンブルウインドウと、レジスタウインドウから、対象メモリへのライト直前でブレークしていることがわかります。
同じように、アクセス対象アドレスを0番地としてハードウェアブレークを設定すれば、0番地への不正アクセス、すなわちNULLポインタアクセスを捕まえることができます。
ですが、ハードウェアブレーク機能は便利なので、他にも使いたくて、チャンネルを開けておきたいんですよね。
内蔵I/Oへのアクセスを引っ掛けたりしたいし、ブレークポイントが設定できないようなデバッグで使いたいし、、、
SOLID IDEでは、これらの検出にMMUを使っています。
まぁ、ちょっとやってみましょう!
4.NULLポインタアクセス検出
先程のプログラムで、*pのアドレスを0番地に変更し、実行してみます。
特にブレークポイント、ハードウェアブレークは設定しません。

*pへのライトアクセスでプログラムが自動で停止し、Data Abort Exceptionが発生しました。
デバッグ例外ウインドウに表示されています。
これ、MMUを使用して実現されています。
[仕組み]
0番地付近は、プログラムによって使用されない領域です。したがって、MMUのアドレス変換テーブルに、論理アドレス0番地付近は登録されていません。
実際に0番地にアクセスがあった際、MMUにより対応する物理アドレスに変換すべきですが、そんな論理アドレスは変換テーブルに載っていないため、物理アドレスに変換ができず、データアボートが発生している、という仕組みです。
これは、論理アドレス=物理アドレスとしてとりあえずMMUをオンにしている、という状態であれば発生しないデータアボートです。
プログラムで使用するアドレスを把握し、関係のないアドレスは変換テーブルに登録してはいない、というひと手間があるおかげです。
5.スタックオーバーフロー検出
次は、スタックをオーバーフローさせてみます。
再起関数を永遠に呼び出すプログラムを書けば、簡単にスタックはオーバーフローしますね。(こういうのは得意ですよ。)
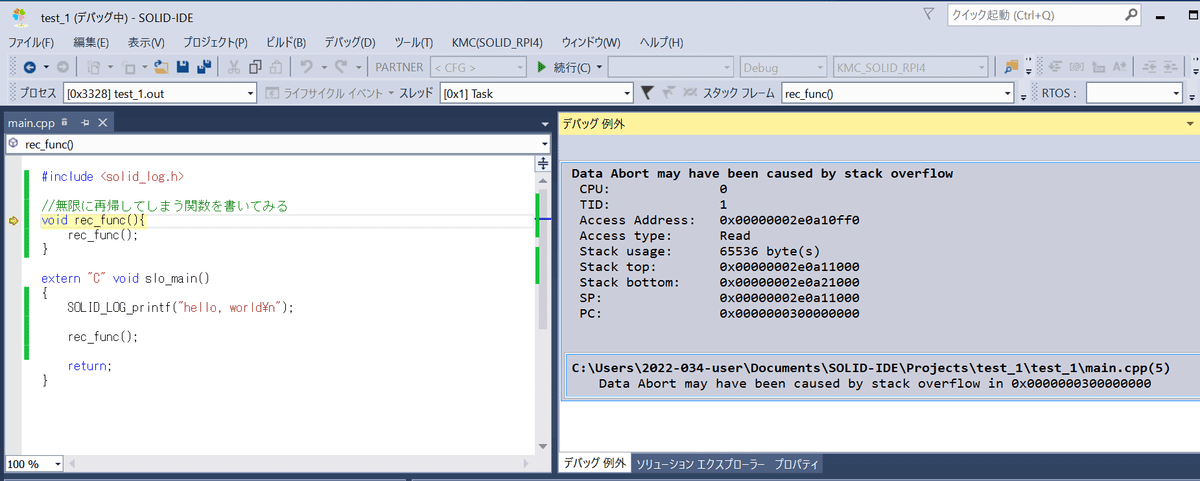
Data Abort may have been caused by stack overflow
というデバッグ例外が発生し、プログラムが停止しました。
[仕組み]
スタック領域と隣り合っている領域を、MMUによるアドレス変換テーブルに載せない。
そうすることにより、スタックの範囲から出てしまったとたんに「アドレス変換ができない」という例外が発生する。
6.まとめ
その他にも、MMUの書き込み禁止属性を使用して、コード領域へライトアクセスが発生すると例外が発生するようになっていたり、いろいろ考えられています。
Interface誌の2023年7月号に、詳しい解説が掲載されていますので、ご興味ある方、見てみてください。
また、SOLID-IDEでは、MMUのアドレス変換テーブルを、GUIで簡単に登録できるようにもしてあるそうです。
「MMUテーブルの登録って複雑すぎる」と思いますが、GUIで簡単に登録できるのであれば、書き込み保護したいバッファ等がある場合、ちょっと使ってみようかな、という気もしますね。
Raspberry Pi4用のSOLID-IDEは無償であるため機能が限定となっていますので、見てみることはできませんが、以下のサイトに記載されています。
https://solid.kmckk.com/SOLID/doc/latest/ide/user-interface/memory-map-designer.html
こういったことも含め、SOLIDは、組み込み開発を安全・楽にするために、いろいろな便利機能を搭載していますので、次回からご紹介していきます。
この記事が気に入ったらサポートをしてみませんか?