
第2回 時系列分析~統計的手法編~

はじめに
前回の記事では、時系列分析の入門として、時系列分析とは何なのか、時系列分析に必要な前提知識について説明しました。
今回は、時系列分析で良く用いられる統計的手法のうち”自己回帰モデル”と"移動平均モデル"について説明します。
自己回帰モデルとは
Wikipediaでは自己回帰モデルは以下のように定義されています。
自己回帰モデルは時点 t におけるモデル出力が時点 t 以前のモデル出力に依存する確率過程である。
自己回帰モデルでは過去の値は将来の値に影響するという前提のもと、時刻tにおける値はそれ以前の値の関数として定義されます。
例えばコンビニエンスストアの売上に関する時系列データを考えた場合に、「昨日と同じような売上となる」や「昨日は売上が上がったので、今日は売上は下がる」といったような関係をモデル化することができます。
自己回帰は英語で"AutoRegressive"と書くことから、ARモデルと呼びます。1時点前までのデータに依存する場合AR(1)モデル、p時点前までのデータに依存する場合AR(p)モデルのように表記します。
AR(1)モデル、AR(p)モデルは以下のように表されます。yは各時点の値、cは定数項、Φは回帰係数、εは各時点のノイズとなっております。こちらの式を見れば分かるように、各時点の値は過去の値の関数として定義されています。

移動平均モデルとは
Wikipediaでは移動平均モデルは以下のように定義されています。
移動平均モデルは、単変量時系列をモデル化するための一般的なアプローチである。移動平均モデルは、実現値となる変数がその変数の平均値、過去の誤差項と確率項(確率、つまりその値を完全には予測できない項)に線形に依存している。
移動平均モデルでは時刻tにおける値はそれ以前の誤差項の値の関数として定義されます。
移動平均は英語で"Moving Average"と書くことから、MAモデルと呼びます。MAモデルは、1時点前までのデータに依存する場合MA(1)モデル、q時点前までのデータに依存する場合MA(q)モデルのように表記します。
MA(1)モデル、MA(q)モデルは以下のように表されます。yは各時点の値、μは定数項、θは回帰係数、εは各時点のノイズとなっております。こちらの式を見れば分かるように、各時点の値は過去のノイズの値の関数として定義されています。

なお、p次のARモデルとq次のMAモデルを組み合わせたモデルをARMA(p, q)と表記するため、ARモデルの次数はpでMAモデルの次数はqで表すことが慣習となっております。
Pythonでの実装例
ここからPythonでの実装例をご紹介します。今回はstatsmodelsというライブラリを使用してARモデルの実装をしますが、MAモデルに関してもstatsmodelsを使用すれば簡単に実装することが可能です。使用したPythonのバージョンや各種ライブラリの情報は以下の通りです。
python: 3.7.3
matplotlib: 3.4.3
pandas: 1.3.3
statsmodels: 0.13.0
まずはライブラリを読み込みます。
import matplotlib.pyplot as plt
import pandas as pd次にデータセットを読み込みます。今回は時系列データとして有名な飛行機の乗客者数のデータセットを使いたいと思います。
df = pd.read_csv('data/AirPassengers.csv')
print(df.shape)
display(df)
1949年~1960年の12年間の月次の乗客者数データが格納されていることが分かります。実際にどのように推移しているのかプロットしてみましょう。
plt.figure(figsize=(20, 8))
df['#Passengers'].plot();
季節的な周期性とトレンドがあることが見て取れます。それでは早速AR(1)モデルの当てはめ、予測をしてみましょう。まずはstatsmodelsからARモデルの読み込みをします。
from statsmodels.tsa.ar_model import AutoReg次に乗客者数データを用いてAR(1)モデルの当てはめを行います。ここでは検証のために、1949年~1959年を当てはめ用に使用し、1960年を検証用のデータとして使用します。
ar_model_lag1 = AutoReg(df.loc[:len(df)-13, '#Passengers'], lags=1)
# モデルの当てはめ
ar_model_lag1 = ar_model_lag1.fit()
# 予測
forecast_lag1 = ar_model_lag1.forecast(12)上記のようにたったの2行でモデルを当てはめることができます。非常に便利ですね。当てはめた結果および予測結果をプロットしてみると以下のようになりました。AR(1)モデルでは1時点前の情報しか使用できないため、うまく予測できていないことが分かります。

乗客者数データは月次単位のデータであるため、12ヶ月周期で乗客者数が推移することが考えられます。そのため、次はAR(12)モデルを作成して、モデルの予測結果を確認してみたいと思います。先ほどの実装からAutoRegの引数lagsを1から12に変更するだけです。
# lags を 1 から 12 に変更
ar_model_lag12 = AutoReg(df.loc[:len(df)-13, '#Passengers'], lags=12)
# モデルの当てはめ
ar_model_lag12 = ar_model_lag12.fit()
# 予測
forecast_lag12 = ar_model_lag12.forecast(12)
AR(12)モデルではうまくモデルを当てはめることができていることが確認できました。ただし、lagsを変更して精度を確認していくのは非常に大変、かつ時間がかかってしまいます。
statsmodelsでは与えられたデータから最適な次数を導くことができるar_select_orderというメソッドが用意されております。このメソッドで最適な次数を導いてみましょう。
まずはar_select_orderメソッドを読み込みます。
from statsmodels.tsa.ar_model import ar_select_order次にar_select_orderメソッドを使って最適な次数を算出します。ar_select_orderメソッドでは最適な次数を算出する際にどこまでの次数を調べるか(maxlag)を指定します。今回は先ほど試したAR(12)モデルより少し大きい15を指定しました。
sel = ar_select_order(df.loc[:len(df)-13, '#Passengers'], maxlag=15, glob=True)
# 選択された次数を表示
print(sel.ar_lags)
# 選択された次数を用いてモデルの当てはめ
ar_model_sel = sel.model.fit()
# 予測
forecast_sel = ar_model_sel.forecast(12)
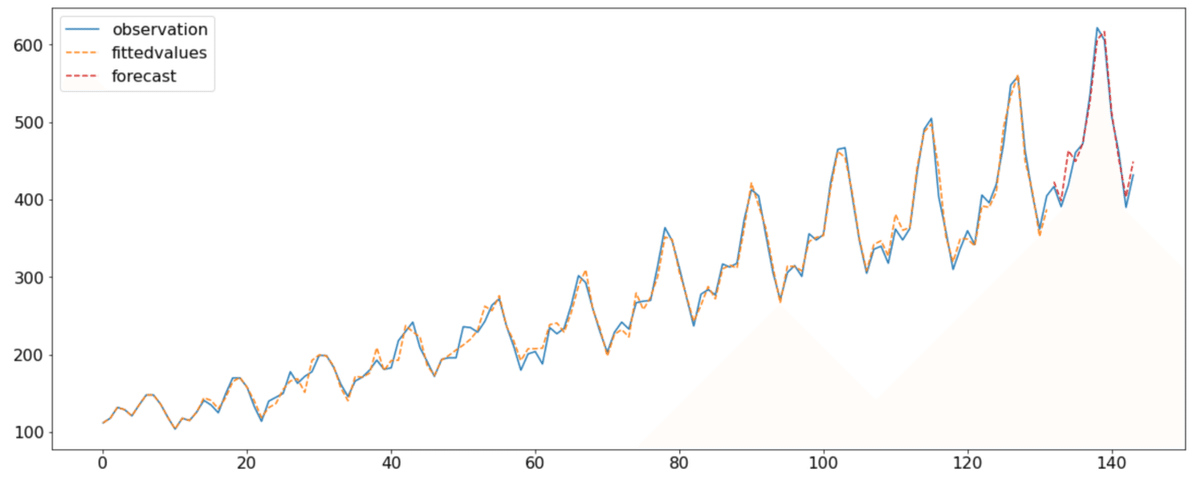
選択された次数を確認してみると[1, 12, 13]のようになっております。引数でglob=Trueと指定したことにより、影響を与えていない次数は選択されないようになっております。※glob=Trueとすると次数の組み合わせのパターンが増えるため、実行に時間がかかります。
予測結果を確認してみると、AR(12)モデルと同様にうまくモデルを当てはめることができていることが分かります。
まとめ
・時系列分析で良く用いられる統計的手法のうち”自己回帰モデル”と"移動平均モデル"について説明しました。
・自己回帰モデルでは過去の値は将来の値に影響するという前提のもと、時刻tにおける値はそれ以前の値の関数として定義されます。
・移動平均モデルでは時刻tにおける値はそれ以前の誤差項の値の関数として定義されます。
・自己回帰モデルをPythonで使ってみたい場合には、statsmodelsを使用すると簡単に実装することができます。
次回予告
次は状態空間モデルについて記事を書きたいと思っています。最後まで読んでいただきありがとうございました。
この記事が気に入ったらサポートをしてみませんか?