
subset()でデータを抽出

東京大学医学部老年病科の矢可部です。
基礎、臨床研究の統計解析でRを用いています。
学生や研修医の指導に使うという目的もあり、noteに記事を書いています。
今回は、元データから条件に合うデータを抽出するやり方を紹介します。
使うのはsubset関数です。
サンプルデータ
この記事で扱うデータが入った"Rdata1.xlsx"ファイルは、下からダウンロードできます。なおこれは前回の記事で用いたものと同じなので、すでにダウンロードした方は不要です。
データをRにコピペする
Rdata1.xlsxに入っている20名分のデータをRにコピペします。
詳しいやり方は以前の記事をご覧ください。
コマンドは以下の通りです。
dat <- read.table(pipe("pbpaste"), sep="\t", header=T) # Macの場合
dat<-read.table("clipboard", sep="\t", header=T) # Windowsの場合
attach(dat)
20名分のデータをdatという名前で保存しました。
このdatの中から、男性のみを抽出します。
subset()でデータを抽出する
以下のコマンドを入力します。
# datから男性のみを抽出して、"Male"という名前で保存
Male<-subset(dat, sex==0)
# Maleを表示
Male
これで、datのうちsexが0のデータだけが抽出されました。
以下のように表示されるはずです。

Rの場合「等しい」を意味するのは"=="です。イコールを2つ書くことに注意して下さい。
さらに、その群をMaleと定義することで、男性のみを対象とした解析ができます。
前回の記事の方法で、各項目の平均、分散、中央値などを求めてみましょう。
年齢については、以下のようなコマンドになります。
# Maleのageの平均を求める。
mean(Male$age)
# Maleのageの標準偏差を求める。
sd(Male$age)
# Maleのageの四分位数を求める。
quantile(Male$age)
実行すると、以下のように表示されます。

また、数字の範囲を指定して抽出することもできます。
# datから65歳以上の人を抽出し、Olderという名前で保存
Older<-subset(dat, age>=65)
# datから50歳以上65歳未満の人を抽出し、Middleという名前で保存
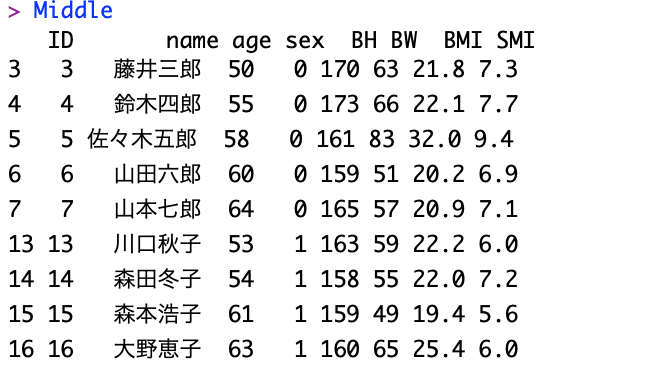
Middle<-subset(dat, age>=50 & age<65)
# datから「50歳未満、または65歳以上」の人を抽出し、YOという名前で保存
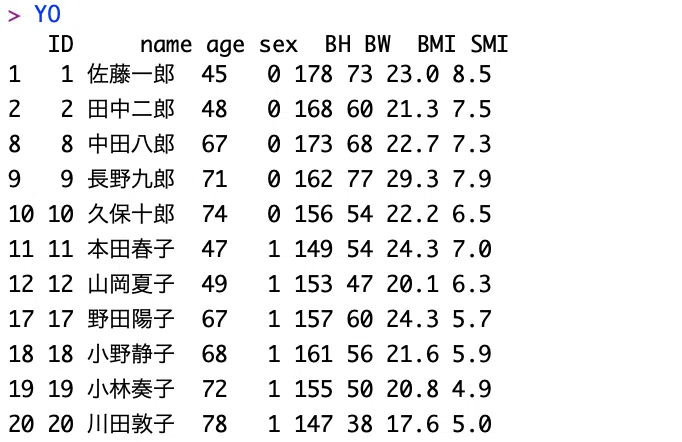
YO<-subset(dat, age<50 | age>=65)
条件で「かつ」を意味するのは"&", 「または」を意味するのは"|"(バーティカルライン)です。
Older, Middle, YOを表示すると以下のようになります。

より高度な方法として、同時に複数の変数の条件で絞り込むこともできます。
# datから「身長150cm以上170cm未満」かつ「体重50kg以上70kg未満」の人を抽出し、NNという名前で保存
NN<-subset(dat, (BH>=150 & BH < 170) & (BW>=50 & BW<70))
上のように( )を使って条件をまとめ、&で繋ぎます。
NNを表示すると以下のようになります。

練習問題
1. "Rdata1.xlsx"から女性のみのデータを抽出して"Female"という名前で保存し、そのage, BMI, SMIそれぞれについて平均と標準偏差を求めよ。
2. "Rdata1.xlsx"から「65歳以上」かつ「BMIが18.5以上25未満」のデータを抽出して"Hyojun"という名前で保存し、表示せよ。
RはExcelより便利
私はRを使ううちに、Excelより便利だと感じるようになりました。
それまではExcelを用いて統計量を計算していました。平均ならAVERAGE関数、標準偏差ならSTDEV関数を用いるといった具合です。そのためにはデータ範囲を選択しなければなりません。
データ全体のものを求める場合は、列全体を選択すればよいので楽です。
しかしサブグループで求めるのはより手間がかかります。
たとえば男性の平均年齢を求めるには、データ全体にフィルターをかけて男性と女性をソートするよう並び替え、男性の年齢の範囲だけを選択して、セルに入力する必要がありました。
さらに、たとえば年齢を「64歳以下」「65歳以上74歳以下」「75歳以上」のように複数のグループで分けて解析する場合、選択する作業はより煩雑になります。
そのような作業も、Rを使うと解説のように簡単にできます。
subset()関数は有用ですので、ぜひ使いこなしてください。
さらにsubset()関数を用いて抽出したデータについて、統計的検定を行うことができます。それは今後記事にしたいと思います。
この記事が気に入ったらサポートをしてみませんか?