
最新ChatGPT「OpenAI o1」は結局何がすごいのか?

OpenAIが2024年9月12日に発表した最新GPT「o1-preview」。一部界隈ではすごさが認知されているような気がしますが、まだまだどのように使いこなせば良いかわからない人もいるのではないでしょうか。
今回発表された「o1」は開発段階で「Strawberry」と呼ばれていたモデルであり、推論に強みを持っているモデルになっております。
ChatGPTの最新モデルであるのにも関わらず、「GPT4-omni」など、これまでのシリーズの継続としなかった(GPT4-XXや、GPT-5など)背景にはいくつか理由があると考えられます。
これにはこれまでのGPT-4シリーズから革新的な変化を遂げたモデルではない、全く別ジャンルの系統のモデルであると示したかった、などの背景があると考えられます。
「OpenAI o1」の概要
今回発表された「o1」モデルは推論に大きな強みを持つモデルです。従来のGPTシリーズと同様Transformerアーキテクチャが採用されているとのことですが、詳細については公式から明かされていません。(Transformerの詳細は以下の松尾研の講座を参照)
詳細は明かされていないものの、これまでプロンプトなどの方法により活用されていた「CoT:Chain of Thought」がモデル内で実行されているイメージです。

海外などのLLMの専門家の人は、下記の論文のPRM(Process Reward Model)をLLMと併用し、LLMの出力を推論ステップごとに評価しているのではないか、と予測している人も多いらしいですが、何かしらの推論ステップへの分解モデルと分解されたステップの出力を評価されるモデルが活用されていると考えるのは妥当であると思います。
公式の話に戻ると、OpenAIは最終的にAGI(汎用人工知能)を目指している企業であることは有名ですが、今回の「o1」モデルはAGIに一歩近づいている認識を持っているらしいのです。
OpenAI is an AI research and deployment company. Our mission is to ensure that artificial general intelligence benefits all of humanity.
OpenAIはAGIに向けたAIの進化のステップを以下のように定義しており、現在はレベル1からレベル2へ移行している段階と認識しているようですね。(出典:Bloomberg)
Stages of Artificial Intelligence
Level 1: Chatbots, AI with conversational language
Level 2: Reasoners, human-level problem solving
Level 3: Agents, systems that can take actions
Level 4: Innovators, AI that can aid in invention
Level 5: Organizations, AI that can do the work of an organization
では、発表された「o1」モデルの推論能力はどの程度凄いのか。
公式の発表によると、推論をより必要とする数学・競技プログラミング・博士レベルの科学的な質問への回答タスクにおいて、それぞれ従来の4oモデルに圧倒的な差をつけていることがわかります。

また、o1より80%安いコストで利用できるo1-miniもすでにTier5(高課金企業)へAPI提供されており、推論が重視されるタスクではo1に引けを取らない性能ながら、推論コストが大きく抑えられています。
(推論以外のタスクでは性能が下がるらしいので扱いには注意)
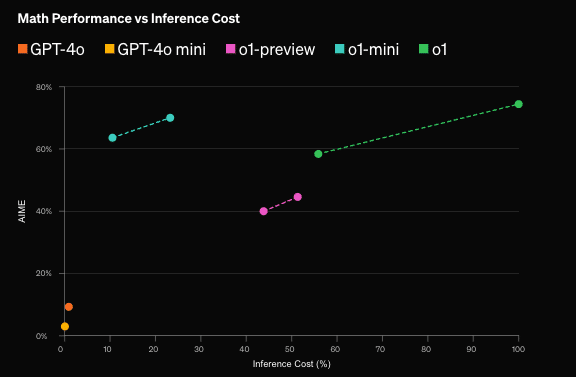
他モデルとの比較
以下の図は、6つの大規模言語モデル(GPT-3.5、GPT-4、Claude 3、Llama 3、Gemini 1.0、o1-preview)を比較し、以下4つの異なるタスクにおける出力確率と精度の関係を示しています。縦軸が精度であり、横軸が出力の対数確率(左へ行くほど
"低確率"な出力)になります。
Shift Cipher(シフト暗号解読)
Pig Latin(Pig Latinという形式の暗号化された文章の解読)
Article Swapping(文章中の単語の順序を入れ替えるタスク)
Reversal(単語のリストを逆順にするタスク)
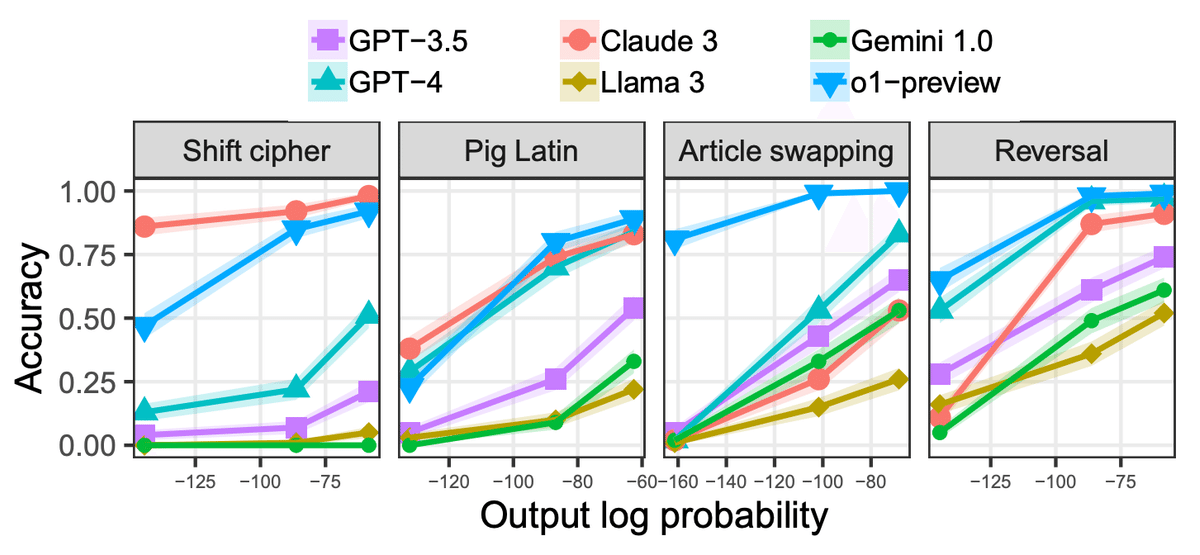
上のグラフから、o1-previewは全般的に他のモデルよりも優れた精度を発揮しており、特に稀なタスクのバリエーションにおいても高いパフォーマンスを維持していることが確認できます。
しかし、下のグラフを見ると、低確率な場合はより多くのトークン数を消費していることがわかり、o1モデルも従来のLLMと同様にタスクの頻度への依存があることが示唆されています。
これは論文中では「Embers of Autoregression」と表現されており、日本語訳で言うと「自己回帰の余韻」や「自己回帰の残り火」にあたります。

ここから言えることは、o1モデルは推論の能力が大きく向上したが、これまでのLLMモデルと同様の弱点は残っている、ということでしょうか。
ここあたりはもう少し個人的にも調べてみたいと思います。
まとめ
9月に発表されたo1に慣れきる前に、早くも次の大きな発表がありましたね。10月3日に発表された「ChatGPT 4o with canvas」では、文章やプログラムを別ウィンドウで開きながら、GPT4oと対話形式で編集できるモードを提供開始しました。
これまでは、プログラムや文章を少しずつ修正したい際に、モデル側の前提知識に左右され、「現在このモデルはどのような内容を想定しているのか?」という疑問が生じることが多々ありました。そのため、その都度モデルに出力を要求しながら調整を行う必要がありました。
しかし、今回の「ChatGPT 4o with canvas」では、別ウィンドウで共通の情報を参照しながら対話できるため、このような煩わしさが大幅に軽減されました。これにより、モデルとの連携がスムーズになり、効率的に修正を行うことが可能となる(ことを願っています)。
今回のアップデートは、これまでの仕組みを劇的に変えるものではないと想定していますが、操作のしやすさや理解の容易さという点で、使用ハードルを大きく下げる効果があると感じています。
どんどん使える幅が増え、煩わしさが減る、素晴らしいサービスですね。これを月20ドルで支えていることに感謝して、明日からも使い倒します。
それではまた。
<それぞれのジャンルの記事まとめ(マガジン)>
読んでいただきありがとうございます! ハートをポチっとしていただけると執筆の励みになります✌️