
[PSPP]記述統計①度数分布と特性値

1変数の記述統計
ビジネスで統計を扱う場合、そのほとんどは得られたデータを元に、予測を立てたりモデルを構築したりという推測統計学の側面が大きくなると思います。しかし、その前段階として記述統計学をはずすことはできません。
まず、1変数の場合の記述統計をPSPPでどのように行うかを整理しておきます。
度数分布と棒グラフ・ヒストグラム
ある変数について、同じカテゴリに含まれるデータの個数を度数といい、総てのカテゴリについて度数をまとめたものを表に表すと度数分布表になります。
例えば、ある20人の血液型データ(A,A,B,B,B,O,O,A,A,AB,AB,B,B,O,O,A,A,A,B,AB)があって、血液型別人数を度数分布表に表します。
・[分析]→[記述統計量]→[度数分布表]を選択。
・[変数]に「血液型」を指定。[統計]のチェックはすべてはずす。
・[OK]をクリック。
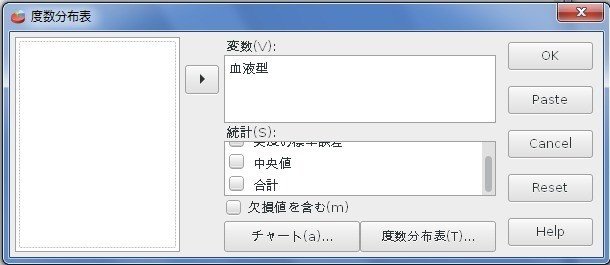

これをグラフ化すると棒グラフになります。上の工程に、
・[チャート]→[バーチャートの描画]にチェック。
を追加すると、度数分布表と同時に、棒グラフが出力されます。


カテゴリ別の度数の違いを視覚的につかむことができます。
一方、国語の小テスト20人分の得点データのような量的データの場合は、質的データのように単純にその数を数えればいいというわけにはいきません。上のように単純に[度数分布表]を実行してしまうと、下図のように一つ一つの数値がすべてカテゴリとして認識されてしまうので、度数分布としては役に立ちません。

量的データの場合には、カテゴリとして範囲を設定します。これを階級と言います。
そうしてできた度数分布表をグラフ化したものがヒストグラムです。ヒストグラムは、X軸が連続した値になっていることが特徴です。上の血液型ではX軸は質的なカテゴリですから、ヒストグラムにはならず、棒グラフになったのです。
ヒストグラムでは、データの分布の仕方などを視覚的につかむことができます。
上の国語の小テスト20人分の得点データを元に、量的データの度数分布表とヒストグラムを描いてみます。
・[変換]→[他の変数への値の再割り当て]
・「得点」変数を選択して、[変換先変数]に「階級」と入力して、[変更]をクリック。
・[今までの値と新しい値]をクリック。
・[範囲]に上限と下限を入力、[新しい値]に任意の数字を設定(ここでは、最小値が4、最大値が15なので、4から5.9:1、6から7.9:2、8から9.9:3、10から11.9:4、12から13.9:5、14から15.9:6、で設定)。
・[OK]をクリック。

ここで、データがすべて整数なのに、上限が小数になっているのは、区間を通常は「~以上~未満」とするので、それを明確にするためです。
PSPPの数値の再割り当ての[範囲]は、「A以上、B以下」であり、両端の数値を含むので、そのような指定にしています。
また、この数値の再割り当ては、先に[追加]したもの、つまり[新しい値]の一覧に表示されている上のものが優先されるため、
14から16:6、
12から14:5、
10から12:4、
8から10:3、
6から8:2、
4から6:1、
の順に[追加]していくと、5には14が、4には12が、3には10が、2には8が、1には6が含まれない範囲にすることができます。6には16が含まれてしまいますが、この場合16は存在しないので問題はありません。
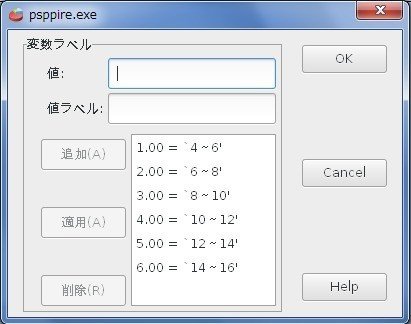
次に、変数ラベルを設定しておきます。
・[変数ビュー]から「階級」変数の[変数ラベル]の[…]をクリック。
・[値]と[値ラベル]を入力して、[追加]をクリック(ここでは、1:4~6 、2:6~8、3:8~10、4:10~12、5:12~14、6:14~16、で設定)。
・[OK]をクリック。
それから、先ほどの血液型と同じように、度数分布表を作成します。
・[分析]→[記述統計量]→[度数分布表]を選択。
・[変数]に「階級」を指定。[統計]のチェックはすべてはずし、[OK]をクリック。

これで、度数分布表が出来上がりました。
次は、ヒストグラムを描きます。
・[グラフ]→[ヒストグラムの描画]を選択。
・[変数]に「国語」を指定。正規曲線を付け加える場合は、[正規曲線の表示]にチェック。
・[OK]をクリック。

ヒストグラムが描画され、標準偏差、平均などが表示されます。

また、度数分布表を描く工程に、
・[チャート]→[ヒストグラムの描画][正規曲線の重ね書き]にチェック。
を追加することでも、ヒストグラムを描くことができます。
特性値を求める―代表値と散布度
特性値とは、個々のデータの持っている情報を要約して1つの統計値で示したものです。データの中心を示す代表値と、データのばらつきを示す散布度の二つに分けることができます。
代表値として最も一般に使われるのが平均値(mean)でしょう。平均値は非常に分かりやすく便利なので、よく使われますが、分布が左右のどちらかに偏っている場合には、平均値は代表値としてふさわしくない場合があります。
そのような場合には、最頻値(mode)や中央値(median)を代表値にする場合もあります。
最頻値は最も多い度数が多い値です。次のようなヒストグラムから最頻値を求める場合、最も度数の多い階級の階級値(階級の端と端のまん中の値)が最頻値となります。
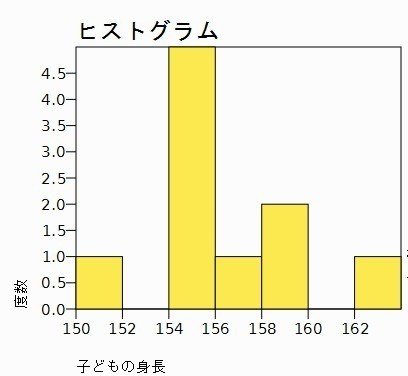
ですから、この場合は、155cmとなります。
中央値は母集団の分布の中央に位置する値です。データの個数が奇数の場合には特定のデータの値を取りますが、データの個数が偶数の場合は中央に2つの値が存在するので、その平均値をとります。データの「個数の中央」が中央値ですから、中央値の上下のデータの個数は同じになります。
PSPPで代表値を求める方法は、[度数分布表][記述統計量][探索的]などいくつかの方法がありますが、代表値3つを同時に求められるのは、[度数分布表]だけなので、ここではその方法を紹介しておきます。
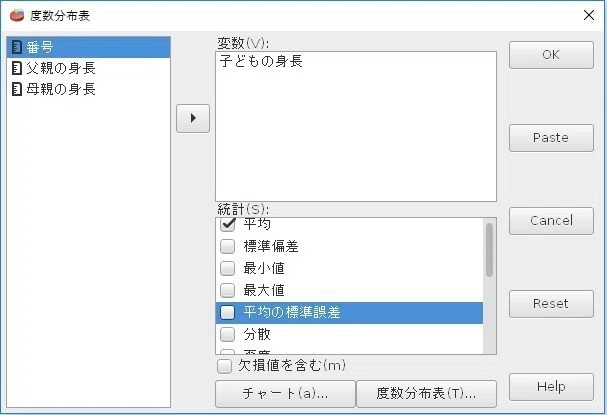
・[分析]→[記述統計量]→[度数分布表]を選択。
・[変数]に「子供の身長」を指定。
・[統計]の中の[平均][最頻値][最大値]にチェック。
・[度数分布表]から、[常に表示しない]にチェックし、[続く]をクリック。
・ヒストグラムを描く場合は、[チャート]から[ヒストグラムの描画]をチェックして、[続く]をクリック。
・[OK]をクリック。

出力は上のようになります。平均は156.56、中央値は155.7です。最頻値が空欄なのは、このデータでは同じ値のケースが存在しないためです。
散布度は、変数の分布を要約する統計量です。代表的なものとして、分散、標準偏差、範囲、四分位範囲、歪度、尖度などがあります。
範囲は変数内のデータの最大値と最小値の差です。
四分位範囲は、第1四分位数と第3四分位数の差で、データの半分が含まれる範囲です。四分位というのは、データを上から25%ずつに区切ったもので、下から25%のところが第1四分位数、50%のところが第2四分位数で、これは中央値のことです。第3四分位数は75%のところになります。
第3四分位数から第1四分位数を引いたものが四分位範囲となります。そして箱ひげ図を書くときには一般的に、第3四分位数と第1四分位数から、それぞれ四分位範囲の1.5倍以上離れたものを外れ値、3倍以上離れたものを異常値として扱います。

各データの値と平均値との差が偏差です。平均からどれくらい隔たっているかを表します。
偏差を2乗してすべて足して、サンプルサイズつまりデータの個数で割ったものが分散です。分散は平均値を中心に各データが平均してどの程度散らばっているかを表しています。
標準偏差は分散の正の平方根をとった数値です。これは、分散は散らばりを見るのにはよいのですが、2乗しているために元のデータと単位が異なっているので、実際の単位上での大きさが分かりにくいからです。そこで正の平方根をとり、単位を元に戻しています。
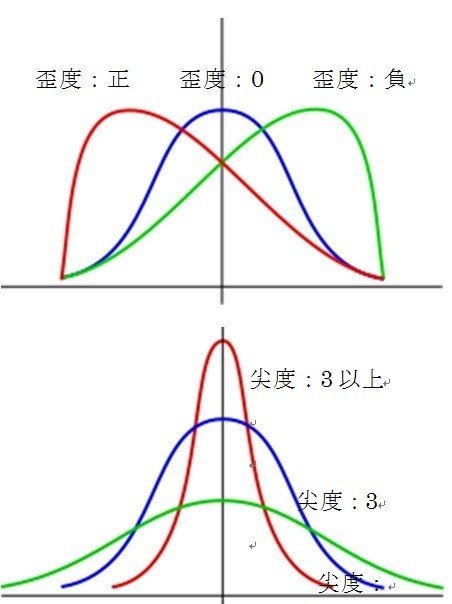
歪度は分布はどれくらい非対称に歪んでいるのかを表します。歪度が正のときは左側に、歪度が負のときは右側に偏っていることをになります。歪度が0のときは左右対称の分布を描いていることになります。
尖度は、分布がどの程度中央付近がとがり、すそが重たいかを表します。数値が3に近いほど正規分布に近く、3より大きいと中央が尖った分布、3より小さいと中央が低いなだらかな分布であることを意味します。
PSPPで、散布度を求める方法は、[度数分布表][記述統計量][探索的]などいくつかの方法があります。ただ、ここで紹介した散布度をまとめて求められるのは、[探索的]なので、ここではその方法を紹介しておきます。
・[分析]→[記述統計量]→[探索的]を選択。
・[統計]で[記述統計量][パーセンタイル]にチェック。
・[続く]をクリック。
・[OK]をクリック。

出力は、次の表の通りになります。「記述統計量」には、代表値も平均値と中央値は表示されています。

まず、「パーセンタイル」の「チューキーのヒンジ」を見ます(四分位はもともとチューキーが定義したもの)。「パーセンタイル」の「50」が第2四分位数で中央値にあたります。「25」が第1四分位数、「75」第3四分位数となります。
「記述統計量」の「最大値」と「最小値」の差が「範囲」になっていることを確認しておきましょう。また、先ほど見た第3四分位数と第1四分位数の差が「四分位範囲」になるはずですが、ここでは調和平均のパーセンタイルでとられていることに注意してください。一番下に「歪度」「尖度」があります。
なお、ここでの「分散」と「標準偏差」は不偏分散と不偏標準偏差です。
最後に[分析]→[記述統計量]以下のメニューで求めることのできるものをまとめておきます。

この記事が気に入ったらサポートをしてみませんか?