
LangChainを用いて大量ファイルをロードするVectorDBを作ってみた(5)

はじめに
前回の投稿では、`Chroma`、`Qdrant`、`FAISS`の3つでローカルのVectorDBを作成プログラムを作成しました。
https://qiita.com/ogi_kimura/items/551c93cd94404c9381c7
今回は、それらのプログラムを実行して、本当にVectorDBができているかを確認します。
それから`chainlit`を適用して、生成AIに特許情報のことを確認してみたいと思います。
3つの中の精度の違いなどを比較検証したいと思います。
プログラム実行とVectorDBの確認
3つのそれぞれ実行してみました。
1.Chroma
`Chroma`では、`sqlite`のデータベース(`chroma.sqlite3`)が生成されました。
では、SQLiteの「DB Browser」を利用して、内容を確認してみます。
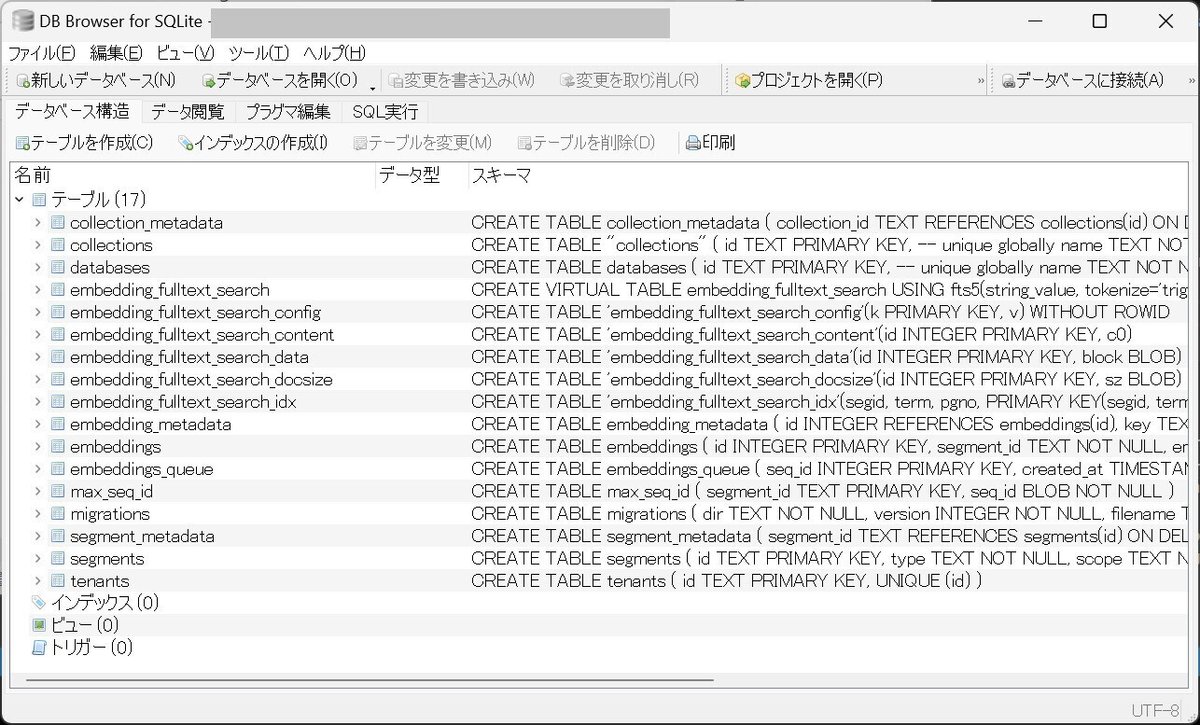
いろいろテーブルが入っていることがわかります。
特に`embedding_metadata`がちゃんと格納されているのかを確認するのにわかりやすいので、一度見てみましょう。

ちゃんとテーブルにデータが格納されているようです。
また、レコード数は、13万程度ですので大丈夫かなぁと思います。
2.Qdrant


`index.faiss'と`index.pkl`の2ファイルがありました。
容量はそれぞれ261MBと167MBです。
中身を見ようとしましたが、文字化けしていたので解析はあきらめました。
多分大丈夫かと思います。
3.FAISS
FAISSの場合は、Chromaと同様に`sqlite`のデータベースです。
テーブル構成はシンプルで`points`というテーブルのみです。

`points`のテーブルの中身は以下のようになっていました。

43,524レコードということで、たぶん大丈夫かと・・・
全体的な話になりますが、プログラム実行をしてからローカルデータベースに書き込み終えるまで、それぞれ1時間程度かかりました。
chainlitで対話準備
では、`chainlit`を適用して、生成AIと対話ができるようにします。
以下のソースコードを作成しました。
ユーザが質問をすると、Chroma、Qdrant、FAISSのそれぞれが同時に回答するようにしました。
そうすれば、どのVectorDBの精度が高いか解ると思いました。
import chainlit as cl
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema import HumanMessage
import qdrant_client
from langchain.chains import RetrievalQA
from langchain.vectorstores import Chroma
from langchain.vectorstores import Qdrant
from langchain.vectorstores import FAISS
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
chat = ChatOpenAI(model="gpt-3.5-turbo")
prompt = PromptTemplate(template="""文章を元に質問に答えてください。
文章:
{document}
質問: {query}
""", input_variables=["document", "query"])
# ========== VectorDB ===========
# ----- Chroma -----
db_chroma = Chroma(
persist_directory="C:\\Users\\***\\langchain_book\\local_chroma",
embedding_function=embeddings
)
rtr_chroma = db_chroma.as_retriever()
# ----- Qdrant -----
client = qdrant_client.QdrantClient(
path="C:\\Users\\***\\langchain_book\\local_qdrant",
prefer_grpc=True
)
db_qdrant = Qdrant(
client=client, collection_name="manga_data",
embeddings=embeddings
)
rtr_qdrant = db_qdrant.as_retriever()
# ----- FAISS -----
db_faiss = FAISS.load_local(
"C:\\Users\\***\\langchain_book\\local_faiss",
embeddings,
allow_dangerous_deserialization=True
)
rtr_faiss = db_faiss.as_retriever()
chat = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# ========== ON_CHAT_START ===========
@cl.on_chat_start
async def on_chat_start():
await cl.Message(content="準備ができました!メッセージを入力してください!").send()
# ========== ON_MESSAGE ===========
@cl.on_message
async def on_message(input_message):
print("入力されたメッセージ: " + input_message)
qa_chain_chroma = RetrievalQA.from_chain_type(llm=chat, chain_type="stuff", retriever=rtr_chroma)
qa_chain_qdrant = RetrievalQA.from_chain_type(llm=chat, chain_type="stuff", retriever=rtr_qdrant)
qa_chain_faiss = RetrievalQA.from_chain_type(llm=chat, chain_type="stuff", retriever=rtr_faiss)
result_chroma = qa_chain_chroma.run(input_message)
result_qdrant = qa_chain_qdrant.run(input_message)
result_faiss = qa_chain_faiss.run(input_message)
await cl.Message(content=result_chroma).send()
await cl.Message(content=result_qdrant).send()
await cl.Message(content=result_faiss).send()楽をするために、それぞれの`retriever`インスタンスを作成し、`RetrievalQA`を利用しようと思いました。
ただ、これだとスコアがわかりませんし、引っかかったファイル名などがわからないため、解析ができません。今回はそこも見たいので、以下のプログラムに変更しました。
import chainlit as cl
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema import HumanMessage
import qdrant_client
from langchain.chains import RetrievalQA
from langchain.vectorstores import Chroma
from langchain.vectorstores import Qdrant
from langchain.vectorstores import FAISS
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
chat = ChatOpenAI(model="gpt-3.5-turbo")
prompt = PromptTemplate(template="""文章を元に質問に答えてください。
文章:
{document}
質問: {query}
""", input_variables=["document", "query"])
# ========== VectorDB ===========
# ----- Chroma -----
db_chroma = Chroma(
persist_directory="C:\\Users\\ogiki\\langchain_book\\local_chroma",
embedding_function=embeddings
)
rtr_chroma = db_chroma.as_retriever()
# ----- Qdrant -----
client = qdrant_client.QdrantClient(
path="C:\\Users\\ogiki\\langchain_book\\local_qdrant",
prefer_grpc=True
)
db_qdrant = Qdrant(
client=client, collection_name="manga_data",
embeddings=embeddings
)
rtr_qdrant = db_qdrant.as_retriever()
# ----- FAISS -----
db_faiss = FAISS.load_local(
"C:\\Users\\ogiki\\langchain_book\\local_faiss",
embeddings,
allow_dangerous_deserialization=True
)
rtr_faiss = db_faiss.as_retriever()
chat = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# ========== 文字列作成 ===========
def make_documents_string(documents):
documents_string = ""
for document in documents:
print("---------------document.metadata---------------")
print(document[0].metadata)
print(document[1])
documents_string += f"""
---------------------------
{document[0].page_content}
"""
print("---------------documents_string---------------")
print(documents_string)
return documents_string
# ========== ON_CHAT_START ===========
@cl.on_chat_start
async def on_chat_start():
await cl.Message(content="準備ができました!メッセージを入力してください!").send()
# ========== ON_MESSAGE ===========
@cl.on_message
async def on_message(input_message):
print("入力されたメッセージ: " + input_message)
documents = db_chroma.similarity_search_with_score(input_message, k=3)
documents_string = make_documents_string(documents)
result = chat([HumanMessage(content=prompt.format(document=documents_string, query=input_message))])
await cl.Message(content=result.content).send()
documents = db_qdrant.similarity_search_with_score(input_message, k=3)
documents_string = make_documents_string(documents)
result = chat([HumanMessage(content=prompt.format(document=documents_string, query=input_message))])
await cl.Message(content=result.content).send()
documents = db_faiss.similarity_search_with_score(input_message, k=3)
documents_string = make_documents_string(documents)
result = chat([HumanMessage(content=prompt.format(document=documents_string, query=input_message))])
await cl.Message(content=result.content).send()
`similarity_search_with_score`を適用したことでスコアがわかるようになりました。またスコアだけではなく、検索適用したファイル名やその文章も標準出力することができます。
今回は`k=3`としました。`k`の値が大きければ本当に必要な文章に引っかかる確率は高まるのですが、その副作用として不要な文章も引っかかってしまい、生成AIが雑味のある回答をしてしまいます。
今回はこれで行ってみたいと思います。
chainlitの実行
では、chainlitを実行してみましょう。
python -m chainlit run all_chainlit_detail.py
こんな感じで出てきました。
緊張の一瞬です!
ではさっそく前回のXMLファイルの内容を確認してみましょう。
今回は「背面に水蒸気バリア性を有する感熱記録体に関する特許を提出した会社は?」で質問してみました。期待する回答は「日本製紙株式会社」です。
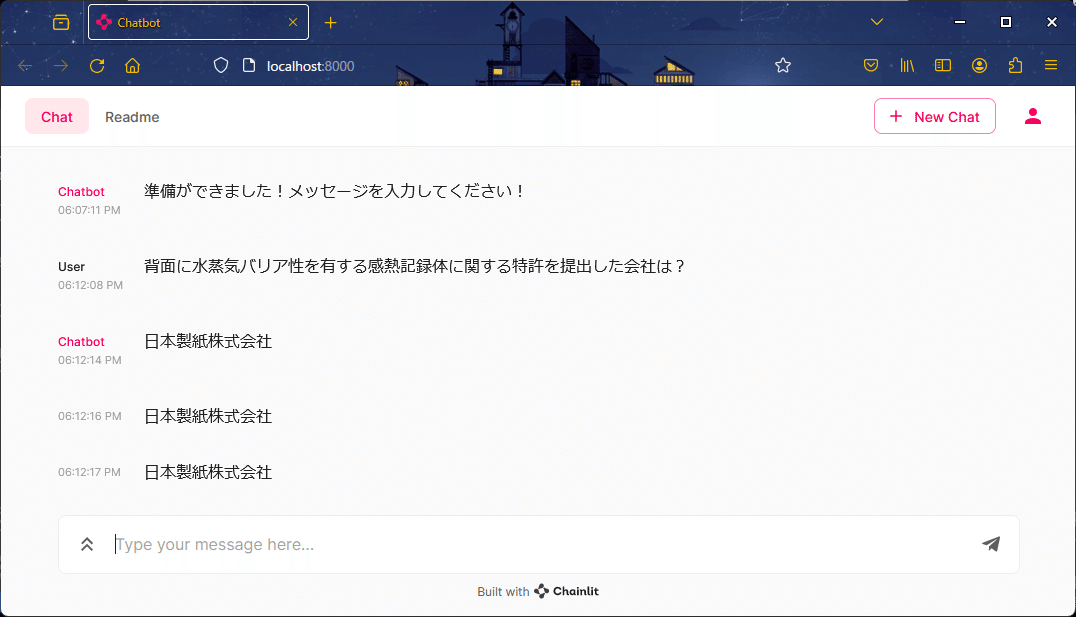
お!まずはすべてのvectorDBが正解しました。
次は「サミー株式会社の特許の概要を教えて」で確認しました。

おー、Chroma以外は正解ですね。
次は「特開2009-096175の特許のタイトルは?」で確認してみました。

正解は`Qdrant`と`FAISS`の回答です。
おわりに
今回の結果から、`Qdrant`と`FAISS`の精度が高いように見えました。
次回は、出力されたスコアなどを確認して、詳細を見ていきたいと思います。
この記事が参加している募集

この記事が気に入ったらサポートをしてみませんか?