
LangChainを用いて大量ファイルをロードするVectorDBを作ってみた(9)

はじめに
前回は、`chainlit`を用いて、プロンプトの最初の10桁はファイル名、11桁目以降は質問内容という、プログラムを作っていました。`chainlit`について、複数の入力欄を出力できるサンプルを見つけることができなかったからでした。とてもこんなプログラムでは、商用利用することはできません。
そんな中、いろいろなプログラミングのサンプルを検索していくと、`streamlit`というものを見つけました。
これであれば、私が考えていた「ファイル名をテキストボックスに入力して、プロンプトを別のテキストボックスに入力する」ということが出来そうです。
chainlit
では、前回の投稿記事で、`chainlit`の場合のプログラムを再掲します。
import chainlit as cl
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema import HumanMessage
from langchain.vectorstores import Chroma
from qdrant_client.http.models import Filter, FieldCondition, MatchValue
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
chat = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt = PromptTemplate(template="""文章を元に質問に答えてください。
文章:
{document}
質問: {query}
""", input_variables=["document", "query"])
database = Chroma(
persist_directory="C:\\Users\\ogiki\\vectorDB\\local_chroma",
embedding_function=embeddings
)
@cl.on_chat_start
async def on_chat_start():
await cl.Message(content="準備ができました!メッセージを入力してください!").send()
@cl.on_message
async def on_message(input_message):
print("入力されたメッセージ: " + input_message)
name = input_message[:10]
documents = database.similarity_search_with_score(input_message[10:], k=3, filter={"name":name})
documents_string = ""
for document in documents:
print("---------------document.metadata---------------")
print(document[0].metadata)
print(document[1])
documents_string += f"""
---------------------------
{document[0].page_content}
"""
print("---------------documents_string---------------")
print(input_message[10:])
print(documents_string)
result = chat([
HumanMessage(content=prompt.format(document=documents_string,
query=input_message[10:]))
])
await cl.Message(content=result.content).send()ご覧の通り、プロンプトの最初の10桁と11桁目以降で強引に文字列を分割していることがわかります。
streamlit
では、`streamlit`の場合はどうなるか。記述したプログラムは以下です。
import chainlit as cl
import streamlit as st
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema import HumanMessage
from langchain.vectorstores import Chroma
from qdrant_client.http.models import Filter, FieldCondition, MatchValue
from langchain.agents import AgentType, initialize_agent, load_tools
from langchain.callbacks import StreamlitCallbackHandler
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
chat = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt = PromptTemplate(template="""文章を元に質問に答えてください。
文章:
{document}
質問: {query}
""", input_variables=["document", "query"])
database = Chroma(
persist_directory="C:\\Users\\ogiki\\vectorDB\\local_chroma",
embedding_function=embeddings
)
st.title("langchain-streamlit-app")
if "messages" not in st.session_state:
st.session_state.messages =[]
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
input_message = st.chat_input("準備ができました!メッセージを入力してください!")
text_input = st.text_input("ここに番号を入力してください")
if input_message:
st.session_state.messages.append({"role": "user", "content": input_message})
print(f"入力されたメッセージ: {input_message}")
with st.chat_message("user"):
st.markdown(input_message)
with st.chat_message("assistant"):
key_no = text_input
documents = database.similarity_search_with_score(text_input, k=3, filter={"name":key_no})
documents_string = ""
for document in documents:
print("---------------document.metadata---------------")
print(document[0].metadata)
print(document[1])
documents_string += f"""
---------------------------
{document[0].page_content}
"""
print("---------------documents_string---------------")
print(input_message)
print(documents_string)
result = chat([
HumanMessage(content=prompt.format(document=documents_string,
query=input_message))
])
st.markdown(result.content)
st.session_state.messages.append({"role": "assistant", "content": result.content})まず、`chainlit`と`streamlit`との違いを見ていきます。
`chainlit`と比較して`streamlit`では「デコレータ」(@で始まる行)がありません。
また、`streamlit`では、以下の様に「ユーザ」と「アシスタント」で表示を分けています。
この様な感じで、`streamlit`を適用してコーディングをしてみました。
全く`streamlit`は触ったことが無かったのですが、30分くらいでできました。
「ユーザ」の場合
with st.chat_message("user"):この部分以下が、ユーザからの質問についての出力です。
「アシスタント」の場合
with st.chat_message("assistant"):この部分以下が、アシスタント(AI)からの回答についての出力です。
プログラム実行
では`chroma_stremlit.py`を実行してみることにします。
python -m streamelit run chroma_streamlit.py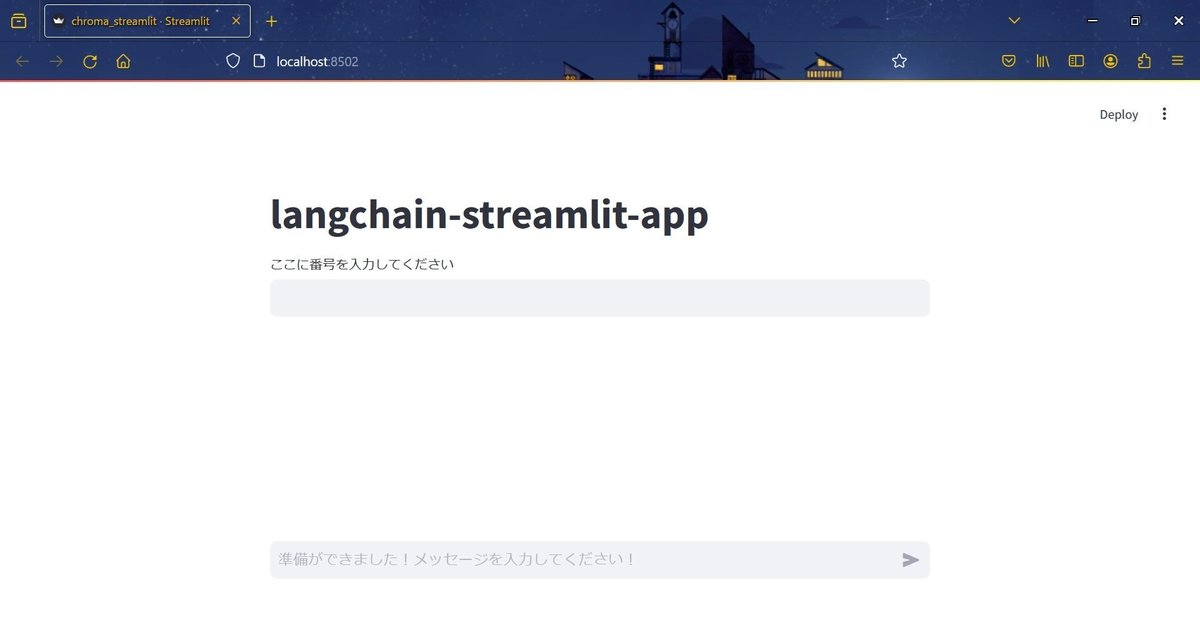
画面が立ち上がりました。
それでは、上部のテキストボックスにファイル名、下部のテキストボックスに質問内容を記入してみます。

ファイル名に「0007350061」、プロンプトに「この特許の概要は?」と入力して、実行しました。
見た感じでは、ちゃんとした回答が返ってきました。
では、VectorDB(今回はChroma)から検索されたデータ内容を確認したいと思います。
---------------document.metadata---------------
{'name': '0007350061', 'source': 'C:\\Users\\ogiki\\langchain_book\\JPB_2023185\\DOCUMENT\\P_B1\\0007350001\\0007350061\\0007350061\\0007350061.xml'}
0.43650519847869873
---------------document.metadata---------------
{'name': '0007350061', 'source': 'C:\\Users\\ogiki\\langchain_book\\JPB_2023185\\DOCUMENT\\P_B1\\0007350001\\0007350061\\0007350061\\0007350061.xml'}
0.4993675947189331
---------------document.metadata---------------
{'name': '0007350061', 'source': 'C:\\Users\\ogiki\\langchain_book\\JPB_2023185\\DOCUMENT\\P_B1\\0007350001\\0007350061\\0007350061\\0007350061.xml'}
0.5071185827255249結果内容から分かるように「name」はすべて「0007350061」となっています。すなわちファイル名が「0007350061.xml」であるという事になります。今までは選択文書はバラバラで、信ぴょう性が高くなかったのですが、予めファイル名で絞ることで、精度の高い結果が返却されるようになりました。
おわりに
今回は、`chainlit`と`streamlit`の違いを比較しながら、検索条件を絞りこみ、精度が上がってきたことを確認しました。
ただ、これだけでは満足できないため、次回は`tagging`を用いた結果を見ていこうと思います。
この記事が気に入ったらサポートをしてみませんか?