
競技クイズとテスト理論
競技クイズの問題をどのように作るかについては、昔から様々な観点で議論がなされています。例えば、名数型の問題を作るとき、既存の問題ではしばしば「項目の中で異質なものがあれば、それが答えになる」などの傾向が知られていますが、これをルールとして課すべきか、それともこれに沿わないものも出題すべきか、などといった議論がよく行われています。
こうした議論は結局のところどのようなコンセプトでクイズを行いたいか、という好みの問題が絡んでくるので完全に客観的に良し悪しを決めることは難しいと思います。ですが、好みについて主張する際の整理の仕方として、これまであまり語られてこなかった1つの視点として「テスト理論」を参考にするのが有用な可能性があるので、ここで紹介してみたいと思います。
テスト理論とは
「テスト理論」というのは、文字通り「テスト」をより良いものにするためにはどういう要素が重要か、というのを扱った理論です。ここでいう「テスト」は、学校の試験や資格試験のようなものだけでなく、心理学などの研究で使われる調査なども含んでいます。
テスト理論では、推定したい対象として「構成概念」というものを考え、テストの結果によってこの構成概念について推定する、という風に考えます。構成概念は、学力試験でいえば学力、技能試験でいえば技能、心理学の調査では感情や性格などといったものが当てはまります。
テストを構成概念の推定手段と捉えると、良いテストというのはどういうものになるでしょうか。例えば構成概念がある能力だとすると、その能力が高い人は高得点になり、能力が低い人は低得点になるようなものが望ましいでしょう。
このようなテストを理論的に扱う上で、主要なアプローチとして「古典的テスト理論」と「項目反応理論(項目応答理論)」の2種類が知られています。
古典的テスト理論
古典的テスト理論は、テストをシンプルに統計的な標本調査のように捉えるものです。真値としての構成概念の程度があった時に、標本調査の結果としてテストの得点が得られた、と考えると、実際の測定値(得点)は真値から±いくらかの誤差を含んだ値となります。
標本調査では、良いサンプリングとして確度が高く(系統誤差が小さく)、かつ精度が高い(偶然誤差が小さい)という性質が挙げられますが、古典的テスト理論においても同様のものを考えます。すなわち、構成概念に対する「妥当性」が高く、かつ測定の「信頼性」が高いものが良いテストだと考えます。妥当性は確度に似た概念で、テストの得点が構成概念の特性をどのくらい適切に反映しているか、というものを指します。一方の信頼性は精度に似た概念で、構成概念の程度が同じ被験者についてどのくらい同じ得点が得られるか、というものを指しています。
古典的テスト理論は考え方としては分かりやすいですが、具体的にテストを改善するのには使いづらい側面があります。というのも、テストによってある得点分布が得られたとして、それが問題の傾向によるものなのか、被験者の特性を反映したものなのかを客観的に峻別することができないからです。そうした問題点を克服するために、テストの問題の特性をモデル化して理論立てしたものが、項目反応理論(項目応答理論)となります。
項目反応理論
項目反応理論(項目応答理論, IRT)では、項目(テストを構成する各設問)に対して、横軸に構成概念の程度、縦軸に正答率を取った「項目特性曲線」を考えます。通常、テストの問題は能力の高い人の正答率が高く、能力の低い人の正答率が低くなるように作られるので、この曲線は右肩上がりのカーブとなります。能力が最も高い人は正答率が1になりますが、最も低い人は必ずしも0にはならず、勘で答えて正解してしまう分だけ0より少し大きな値になります。
項目反応理論では、この項目特性曲線を数学的なモデルで扱います。一般によく用いられるのはロジスティック関数によるモデル化です。このモデルは「困難度」「識別力」「当て推量」の3つのパラメータを持ちます。(なお、実際には「困難度」のみ、もしくは「困難度」と「識別力」のようにパラメータ数を減らしたモデルを使うこともあります)
ロジスティック関数のグラフは全体として右肩上がりな曲線ですが、ある中心点の付近で特に傾きが大きいような形をしています。「困難度」という指標はこの中心点の位置が左右どのあたりにあるかを示します。

項目反応理論では、このモデルに対して情報量を計算することができます。これを表す項目情報関数は、下図のようになります。

すなわち、困難度が高い問題は能力が高めの付近での情報を与え、低い場合には低めの付近での情報を与えます。ざっくり言えば、正答率が変化する部分で情報量が高く、変化しない部分は情報量が低い、という形です。
ここで、上図に示したような、困難度が0.2、0.5、0.8の3問からなるテストを考えたとします。テスト全体の情報量は問題ごとの情報量を足し合わせたものになるので、全体としては下図の黒い曲線のようなテスト情報関数になります。
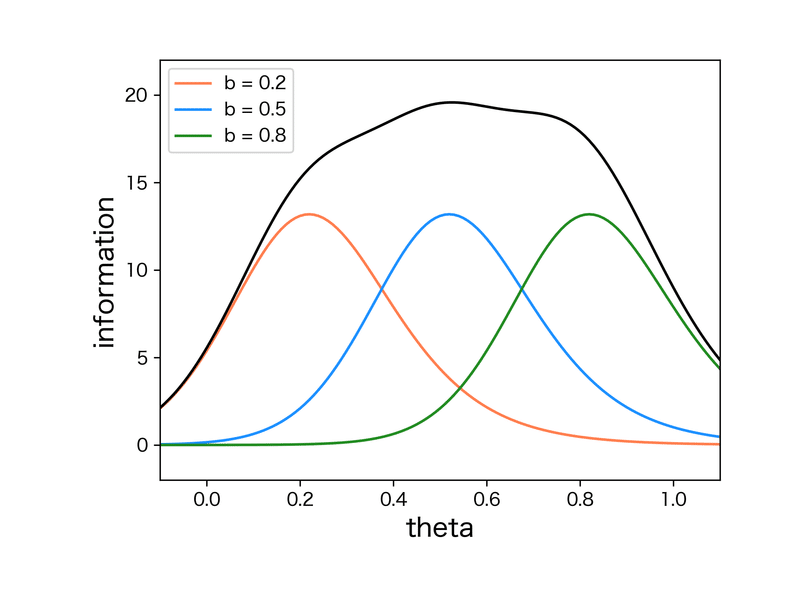
被験者の能力分布が全体にわたっている場合、テストとしては全体の情報量が高いことが望ましいです。例えば困難度の小さい問題ばかりを集めたテストでは、能力の高い被験者について得点差があまり付かず、能力差を見分けるのが難しくなります。したがって、良いテストというのは困難度が低いものから高いものまで平均的に取りそろえたもの、ということになります。
他の2つのパラメータについても見てみましょう。「識別力」は、中心点の付近での傾きの大きさに対応します。傾きが大きいほど能力の差異に関する情報の信頼性が高くなるので、一般に識別力は高い方が良い問題となります。

識別力の項目情報関数は下図のようになります。識別力が高ければ高いほど、情報量は大きくなりますが、その分情報が中心点に偏る形になります。

「当て推量」は、能力が低い側で勘で正解してしまう程度を表す指標です。この値が大きくなると被験者全体での正答率の差異が小さくなるので、情報の信頼性が下がることになります。なので当て推量は小さい方が良い問題と言えるでしょう。


項目反応理論を用いてテスト問題を作る場合、予め多数の被験者にテストを解かせて、その全体の得点と項目(設問)ごとの正答率のデータから項目特性曲線のパラメータを最尤推定しておきます。これによって識別力が高く当て推量が低くなるような項目群を作っておき、そこから困難度がばらけるようにいくつか選んで本番のテスト問題を構成します。
また、複数回のテストを行う場合には別の問題群を選んでテストを行うことになりますが、問題の違いが与える影響を排して被験者の能力を推し量るため、それぞれの項目群の特性値によって等化処理を行うことで、テスト間の比較ができるようにします。
競技クイズの問題群とテスト理論
競技クイズをテスト理論におけるテストとみた場合、構成概念は何になるでしょうか。実際のところこれは大会のコンセプトによって非常にまちまちになるはずですが、比較的よく行われている知識ベースの早押しクイズ形式の場合、以下の2つの要素の合わさったものになると思われます:
問題を解く能力
特に、問題で扱われているトピックに関する知識
早押し能力
押したポイントまでの問題文から後続の問題文を推測する能力
ここでは2つの要素が合わさっているため、どちらにどれだけの重みを置くかによって、問題文の良し悪しに関する評価も変わってくると思われます。テスト理論の言葉でいえば、構成概念妥当性の判断が変わってくることになるでしょう。
ペーパークイズの場合
ペーパークイズの場合は、純粋に問題を解く能力のみに焦点が当てられるので、一般的なテスト理論の応用例をほぼそのまま適用することができそうです。例えば、構成概念として教養的な知識を持っているかどうかというのを想定したとして、より広く深い知識を持っている人が得点が高くなるようにテストの構成を考えるとしましょう。この時、項目反応理論の考え方では、識別力が高く当て推量が小さいような問題を取りそろえて、様々な困難度にわたったものを集めたものが良いテストということになります。
ペーパークイズのよくある構成として、前の方に簡単な問題を並べ、後ろにいくにつれて徐々に難しくなっていく、というものがあります。これは、項目反応理論でいう困難度が低いものから高いものまで幅広くカバーするようにする、という考え方と符合していそうです。
識別力について考えると、ある水準より高い知識量を持っている人が正解でき、そうでない人は不正解となるような問題が良い、ということになります。これは、知識の有無という観点では自然に作れば満たされそうなところですが、例えば引っかけ要素があったり、運に左右されるような問題は、知識量という構成概念を想定している時にはあまり適していない、ということになるでしょう。
早押しクイズの場合
一方で、早押しクイズの場合には、問題の難易度は同程度のものに揃えているケースも多いと思います。こちらは、「早押し」という形態そのものが、早く押せば困難度が上がり、遅く押せば困難度が下がる、という仕組みにより、困難度の幅を自然と実現できる形になっている、という事情が影響しているもののように思われます。
また、早押しクイズの問題文では、マイナーな情報を問題文の前の方に置き、後にいくにつれて徐々によく知られた情報を配置する、という法則に従うのが良いとよく言われます。これは、押しポイントの差による困難度の違いに知識量の要素を入れ込んだものと捉えることができると思います。構成概念として後続文推測の能力よりも知識量を重視する程度が大きい場合には、この法則が特に重要になってきそうです。
早押しの場合は押したポイントで問題文が止まるため、あまりにも早く押した場合は十分な知識と推測力があっても解答を限定できない場合があり得ます。この場合、知識量・推測力の有無と正誤の相関が弱くなると考えられ、識別力が低い項目と見なせると思います。問題文の構成についてよく議論されるものの1つに「前フリで十分限定されていない問題文」の是非というのがありますが、これはこういう意味合いでの識別力の低さを問題にしている、と捉えることができるように思います。
個別の問題への適用を考える
さて、ここまでは問題群としてテスト理論を適用して考えてきましたが、個別の問題にフォーカスしても似たようなことができるのではないか、というのを、名数型問題を題材として考えてみます。
競技クイズで出題される名数型の問題は、慣例としてそのうち1つを答えさせるものが主流になっていますが、特に制約なく単にその名数を知っているかどうかを問いたいならば、全てを答えさせる方が望ましいはずです。ですが、1つだけを答えさせる問題でも、全てを答えさせるのと同等の効果が得られるのであれば、1つだけの問い方で代用するのも悪くない、と言えるように思います。
例えば、次の名数型問題を考えてみましょう:
一般に「世界三大料理」と呼ばれる料理とは、フランス料理、中華料理と何料理でしょう?(トルコ料理)
この問題は、「フランス料理」「中華料理」に比べて「トルコ料理」が日本での知名度が低いとされることから、トルコ料理が問われる傾向が強い、という風にしばしば言われるものです。
この問題の出題意図として、「世界三大料理」について知っているかどうか、というのに重点が置かれているとしてみて、全部を答えさせるものの代用として1つだけを答えさせる、という状況を考えてみます。「フランス料理」「中華料理」「トルコ料理」のどれを答えさせる問題が、より良く出題意図に沿ったものになるでしょうか?
テスト理論の言葉で言えば、「世界三大料理について知っているかどうか」というのが真に測定したいもの、つまり構成概念となります。世界三大料理について知っているのに誤答してしまう、ないし世界三大料理について知らなくても正解してしまう、という場合は構成概念妥当性が低い、と考えられます。
このケースについて、項目反応理論の応用ができないかを考えてみましょう。一般的な項目反応理論の応用例では、各項目(問題)は独立になるように作るのが前提されていて、それらを一度に出題したプレテストで困難度や識別力のモデルを計算します。ですが、この事例の場合は3つの問題候補のそれぞれが互いの答えを問題に含んでいるので、一挙にプレテストして情報を集めることができません。
そこで、被験者に対してまず
一般に「世界三大料理」と呼ばれる3種類の料理は何料理でしょう?全て答えなさい。
という問題を出し、その後ランダムに3つのうちから1つを選んで
一般に「世界三大料理}と呼ばれる料理とは、○○料理、××料理と何料理でしょう?
という問題を出す、というのを多数繰り返すことにしてみます。項目特性曲線として、横軸に1問目の正解数を取り、縦軸に2問目の正解率を取ります。
実際に、何人かの被験者を集めて調査してみると、以下のような結果が得られました:
$$
\begin{array}{crrr}
\hline
全体の正答数 & 0 & 1 & 2 & 3 \\
\hline
「トルコ料理」の正答率 & 0.10 & 0.00 & 0.12 & 1.00 \\
「中華料理」の正答率 & 0.00 & 0.00 & 0.73 & 1.00 \\
「フランス料理」の正答率 & 0.00 & 1.00 & 1.00 & 1.00 \\
\hline
\end{array}
$$

サンプル数が103件とあまり多くないので細かい数値はかなり誤差を含んだものになっていそうですが、おおよそロジスティックモデルが当てはまりそうで、かつ困難度がそれぞれ異なりそうな結果が得られました。
困難度と識別力を考慮した2パラメータモデルで、ロジスティック関数の最尤推定を行うと、3つの問題の各パラメータはそれぞれ以下のような値になりました:
$$
\begin{array}{crr}
\hline
パラメータ & 識別力 & 困難度 \\
\hline
「トルコ料理」の問題 & 9.9 & 0.81 \\
「中華料理」の問題 & 24.0 & 0.63 \\
「フランス料理」の問題 & 34.5 & 0.13 \\
\hline
\end{array}
$$

「フランス料理」の問題は、困難度が低く、全体の正答数が0と1の間で正誤が分かれています。なので、「世界三大料理」についてほとんど知らない人について正誤を見分けるのに最も適していて、ある程度知っている人についてはあまり情報を与えない問題のようです。
「中華料理」の問題は、困難度が中くらいでした。「世界三大料理」を2つ知っているか知らないかくらいの人を見分けるのには、この問題が最も適している、ということになると思います。
「トルコ料理」の問題は、困難度が最も高いところにあります。なので、「世界三大料理」を全答できるかどうかを重視する場合はこの問題が良さそうです。ただ、3つのうち2つだけ知っている人の中で「トルコ料理」が含まれることを知っている人が若干いるため、識別力が少し低めになっています。全答できるかどうかに対する完全な代用になるとまでは言えないかもしれません。
まとめ
TOEFLやITパスポート試験のような、項目反応理論が使われている資格試験は、大量のデータを機械的に処理する目的で選択式の設問に依っていることが多いようですが、短答式のクイズの問題でも、考え方自体は応用ができるように思います。
また、前節で挙げた例のように、個別の問題についての良し悪しを検討する上での応用は、漠然とした評価になりやすい問題の良し悪しをある程度客観的に数値化できるので、より建設的な議論をする上では有用な可能性があります。大会を行う前に実際に調査を行って吟味するのは難しい場合も多いかもしれませんが、議論する時の材料として使える場面はあるのではないかと思います。
謝辞
「世界三大料理」の問題について項目特性曲線を推定するための調査を行うにあたって、私の勤め先の社員にご協力いただきました。ご回答いただいた皆様に感謝の意を表します。ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?