
Nejumi LLMリーダーボード Neoからの考察


Nejumi LLMリーダーボード Neoの仕組みと使い方を詳細にご説明するウェビナーを1/24に開催します。下記の申込ページよりご参加登録をお待ちしています!
Weights & Biases Japanでは昨年末、Nejumi.aiリーダーボードのアップデート版、Nejumi LLMリーダーボード Neoを公開しました。
https://t.co/J262Wk7ByR LLMリーダーボードが新しくなりました!一問一答形式での言語理解と、プロンプト対話での文章生成能力を総合評価を行う日本語性能ランキングの決定版です。W&Bレポート機能を使ってその場でモデル比較分析を行うことができます。話題のモデルをどんどん追加していきます!… pic.twitter.com/CELIkkn1YT
— シバタアキラ (@madyagi) December 27, 2023
この新しいバージョンの開発に際しては、LLM-jpのモデル評価チームや、Stability AI Japan の評価チームの皆さん、弊社内LLMエクスパートチームなどとのディスカッションを経て日本でLLM開発・提供をされている方々にとってフェアで、広く役に立つ評価方法の構築を心がけました。
7月に初期バージョンを公開してから、数多くのモデルがリリースされ、私たちもリーダーボードの運営を通じてモデルの「性能評価」に関して多くを学ぶことができました。今回のリリースに至るまでの詳しい経緯はこちらの記事をご覧ください
リーダーボードが変わって何がわかった?
今回のアップデートによって、それぞれのモデルについてより幅広くその性質を理解し、他のモデルと比較することができるようになりました。特に今回のアップデートでは、言語理解評価(Jasterデータセットを使用)と、言語生成評価(MT-Bench-jpを使用)の両軸から結果を分析することができます。全体の傾向としては、この二つの性能には緩やかな相関関係があるのですが興味深い外れ値も存在します:
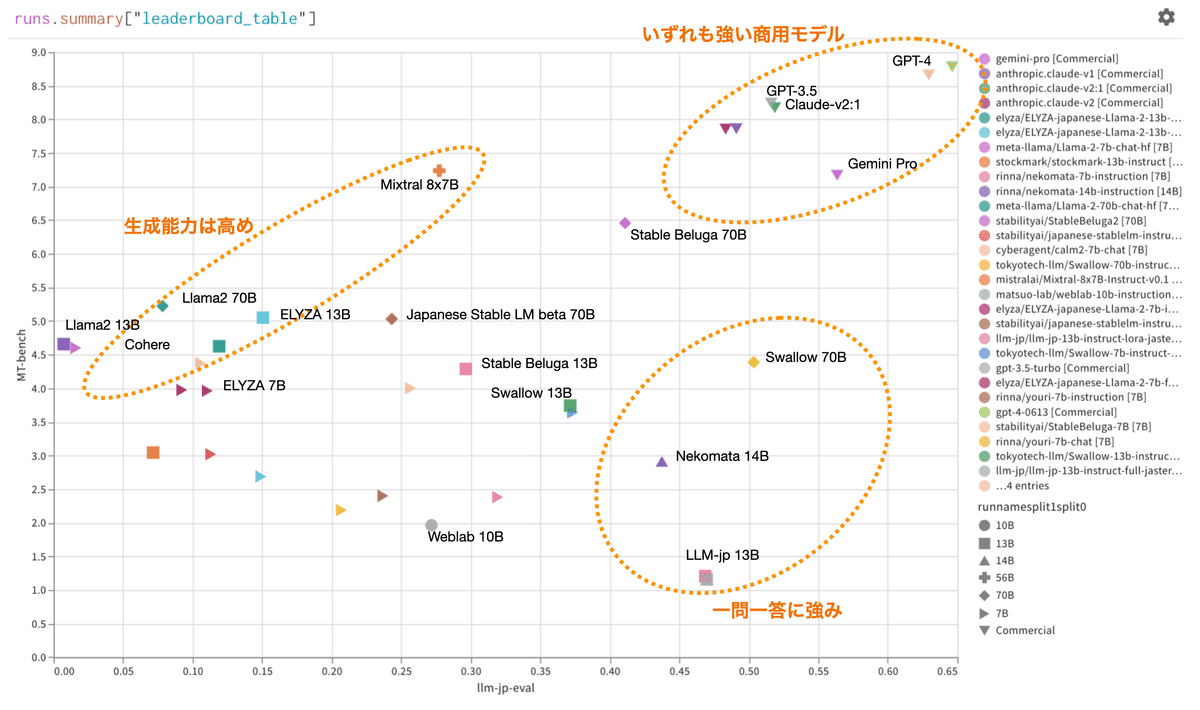
何をさせても強い商用モデルたち
「ChatGPTを超えた」という触れ込みは今年(2023年)何度も聞いたのですが、実際のところ日本語においてはGPT4は他を大きく引き離して優れていることが示されました。AthropicのClaudeやGoogleのGeminiなどの商用モデルに関しては、GPT3.5には迫りつつもGPT4には及ばず。ただしいずれの商用モデルも理解・生成共にこなすオールラウンダーです。GPT4に関しては11月のバージョンが6月のバージョンより少し結果が悪くなっているところは気になります。より安全性を追求した結果能力が下がったのでは、などの憶測はありますが、実際のところはわかりません。
生成・会話に注力したモデル
これまでのNejumiリーダーボードでは、X軸のみによる評価だったのですが、利用者の定性評価は生成・会話能力に基づいているケースが多く、上記結果はその感覚値にも合っています。ELYZA社やMistral社のMoE (複数のエクスパートモデルを束ねた)などはいずれも今年高い会話能力で話題になりました。特にELYZAの13Bモデルは小型ながら特質すべき性能で、Llama2 70Bに理解能力で凌駕しながら、生成能力で肉薄しています。
形式的な一問一答に強いモデル
今回のリーダーボードアップデートのきっかけにもなったLLM-jpの13Bモデルは会話能力よりも形式的な一問一答に強くなるようチューニングされており、JGLUEをベースにした前バージョンのNejumiリーダーボードでは非常に上位にランクインしましたが、会話・生成能力とのトレードオフが鮮明です。また、Llama2の継続事前学習を行なって先日東工大からリリースされたSwallowは、全体スコアでも非常に好成績ですが、ベースのLlama2から比較すると、特に一問一答問題での精度が高くなっていることがわかります。ベースモデルであるLlama2とSwalloの70Bパラメーターモデルを比較したレーダーチャートを見ると、Jasterデータセットでの評価が全ての軸で向上していますが、生成能力では、HumanityやCodingなどの軸で少し結果が下がっています。

素のLlama2がなぜ一問一答形式に弱いのか、実際の問題をNejumiリーダーボードで見てみましょう。Llama2は読解能力(RC)だけは少し評価されていますが、それ以外においては振るわない結果です。例えばMA(数学)カテゴリの問題の結果をSwallowモデルと比較すると:

双方プロンプトでは数字だけを返すようにと指示をされているのですが、Llama2に関しては "Sure, I can help you!" など、無駄な前置きばかりです。Swallowは見事に数字だけを答え、多くのケースで正答しています。
このように、WandBレポート機能を使ったNejumiリーダーボードではその場でさまざまな分析を行うことができます。
トップクラスのモデルでも難しい課題
OpenAI, Anthropic, Googleの3社のモデルは、全体の中でも秀でている存在ですが、それらのモデルでも不得手なタスクにはどのようなものがあるのでしょうか?

まず、言語理解(左側)においては、QA (Question and Answer), EL (Entity Linking), FA (Fundamental Analysis) の三つに対し、いずれのモデルも結果を出すことができていません。例えば、chaBSAデータセットを使ったEL問題への回答を見てみましょう。固有表現とそれに対応する極性(増えていたらPositiveなど)、を厳格な形式(固有表現、極性、改行)で正確に答えられることを求められる問題です。いずれのモデルも頑張っていることは見てとれますが、少し抜き出し箇所がずれていたり、全ての対象解を抜き出せていないなどの問題が多発しています。他の低スコアカテゴリについても、非常に複雑な形式での回答が求められる問題が多い傾向があり、モデルの能力が試されています。

言語生成に関しては、モデルによって成績の差が出ている項目がいくつか特定できます。特にCoding, Math, Reasoningの三つの項目は3モデルの成績に比較的大きな差があります。例えば、Reasoning問題を一つ抜き出してみました、「田中さんは健康だけど毎日病院に行く必要があるのはなぜ?」という質問に対し、「健康なら病院に行く必要はないだろう」と答えるGemini、「十分に判断する情報が足りない」と答えるClaude、そして「田中さんは医療従事者なのではないか」と答えるGPT-4の比較には明確な能力差を感じさせます。

日本におけるLLM開発の意義
ランキング全体を見ると、上位にあるのはOpenAIをはじめとするアメリカの商用モデルやオープンソース/オープンウェイトでもStableBeluga70B、Mistral 8x7Bなど海外の先端モデルが国内で開発されているモデルを凌駕しています。日本の開発者からは「海外のモデルは日本語のデータが少ないので日本語はあまりうまくない」というコメントを聞くことが多いのですが実際の事情はどうなのでしょうか?
日本の開発者が開発・公開しているモデルのほとんどは7Bないし13BパラメーターのsLLM(小規模なLLM)です。これは国内で大量のGPUが自由に使えるプレーヤーが限られていることや、大きなモデルを開発していても公開していないことに起因していますが、これらsLLMだけに絞ったランキングを見てみましょう。

どちらも上位に東工大のSwallowが入っていること、また、ほとんどのモデルがLlama2をベースにしていますが、日本で開発されている多くのモデルは、ベースのLlama2モデルよりも日本語が上手いことが確認できました。sLLMモデルは推論時に比較的小さなメモリーでも実行できることから、コストメリットやポータビリティーに利点があり、この領域での競争は全体ランキングとは別にみていく必要がありそうです。
また、モデルのサイズに関わらず、少ない量の日本語でしか学習していないモデルは、仮に日本語能力が高くても、「トークン・エフィシェンシー」が低いと言われています。トークンとはLLMにおける「単語」に相当する言葉の単位ですが、データ量の多い言語についてはより少ないトークンで多くを表現できるよう学習時に最適化が行われます。英語のデータが大半の学習データの場合、英語においては1トークンが数単語を示すこともあるのとは対照的に、日本語の一文字に数トークンが必要、と言うようなケースも出てきます。そうなると、日本語の計算効率が下がり、ひいては日本語で使うと割高になる、と言う問題もあります。
日本で独自モデルを開発することは人材の育成や、目的特化型モデルの開発などなど他にもたくさんのメリットがあり、より多くの企業が開発の取り組みを開始することを願っています。
精度以外の課題:モデルインターフェース
それぞれのモデルの使い方は共通しておらず、個別対応が必要とされます。特にモデルによって適切なプロンプト(インストラクション、コンテクスト、質問)を利用しないと、モデルのパフォーマンスを引き出すことができないため、それぞれのモデルの「使い方」を理解する必要があるのですが、多くのモデルにおいてどのプロンプトが正しいのか(多くの場合ベースのモデルに依存するが)わからないことも多いです。

その点、Stability AIのモデルは非常にモデルカードがしっかり書かれていて(例えばStable LM Betaの場合)必要な情報がわかりやすく、助かりました。
また、MT-Benchでのテストを行う上では、各モデルとのチャットインターフェースが必要になります。LM-Sysから、FastChatという共通インターフェースがリリースされていますが、全てのモデルがこれに対応しているわけではなく、私たちのチームでは対応させるための開発をモデルごとに行う必要がありました。
このように、モデルインターフェースの共通化の流れはあるものの、モデルのバリエーションは多様化の一途を辿っており、また、マルチモーダルなモデルにおいては、インターフェースも評価方法も更に幅広いパターンが出てくるものと思われますので、リーダーボード泣かせの状況は当分続きそうです。
リーダーボードの使い方:非公開でも走らせたい
上記のような個別対応の必要とされる状況はありながら、W&Bチームでは当然モデル評価のステップは可能な限り自動化し、省力化を目指しています。評価手法の透明性を高め、また私たち以外でも評価を走らせることができるよう、リーダーボード評価に使われたコードはGitHub上に公開されています。このコードを使い下記のステップを経ることで、誰でも同じ方法でモデル評価を走らせていただくことができます。
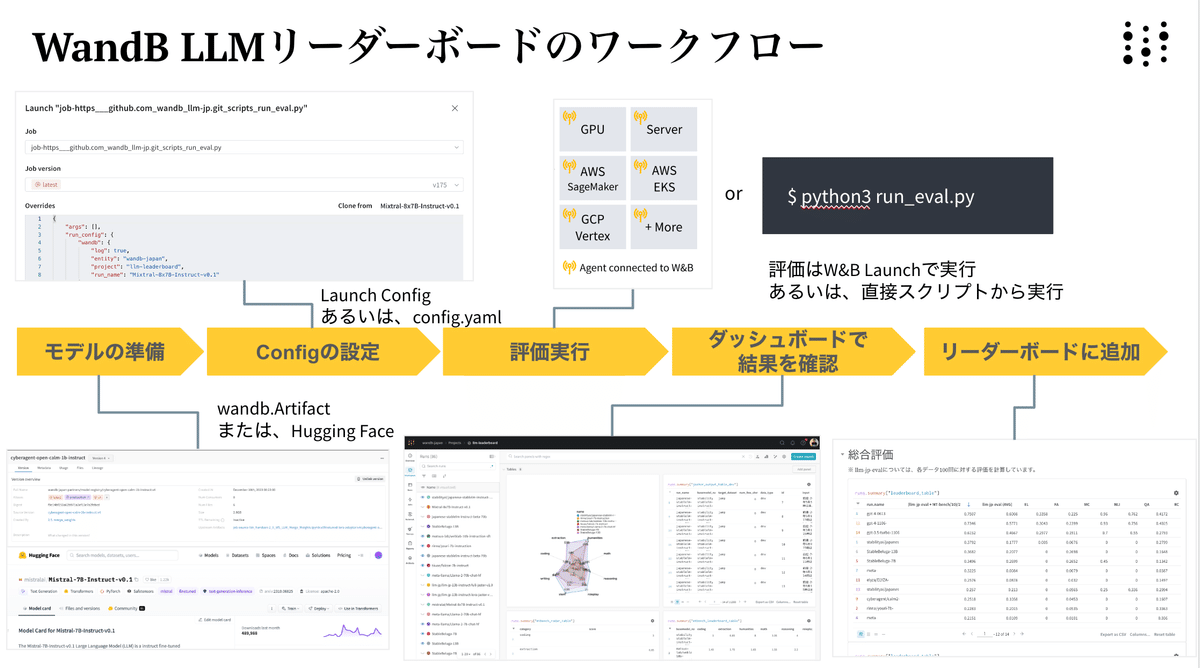
また、自社のモデルも同じ方法で評価したいが、結果は公表したくない、というようなユースケースも歓迎です。基本的には上記のコードとWandBを使って実現できますが、ご質問のある方はぜひお気軽にcontact-jp@wandb.comにご連絡ください。
WandB Slack 上の #nejumi -leaderboardチャンネルでも聞いていただけます。
